Building a Reliable Data Foundation: Data Quality for LLMs
By Juan Mantegazza
Achieving substantial value with large language models (LLMs) can be challenging without a scalable data foundation. Data points are collected from multiple sources and defined in multiple different ways. This could cause them to be in opposite directions and lack consistency. Lack of proper entity documentation and a strong data quality strategy boils down to engineers manually closing this gap and resolving discrepancies.
By investing in a scalable data foundation, this paradigm experiences a fundamental shift. Data is well documented, clearly owned and structured and LLMs can limit their decision-making scope to exclusively focus on the elements with clear governance and well-implemented change management.
Introduction
Large Language Models (LLMs) are advanced artificial intelligence systems that have been trained on massive amounts of text data to understand and generate human-like language. These models, such as OpenAI’s GPT-4, consist of millions (or even billions) of parameters, enabling them to grasp complex linguistic patterns, context, and semantics.

LLMs have gained immense importance across a wide range of applications due to their remarkable language understanding and generation capabilities. Here’s how they are making an impact:
- Natural Language Understanding: LLMs can comprehend and analyze text with a human-like understanding. They excel at tasks like sentiment analysis, text classification, and named entity recognition, enabling better understanding of user intentions and emotions.
- Text Generation: These models can generate coherent and contextually relevant text. We can think of content creation, chatbots, automated customer support and creative writing as examples of this feature.
- Language Translation: LLMs facilitate accurate and context-aware language translation, breaking down language barriers and enabling effective communication on a global scale.
- Summarization and Content Extraction: They excel at condensing large volumes of text into concise summaries, aiding in information retrieval and content summarization.
- Code Generation and Technical Support: LLMs can generate code snippets, troubleshoot technical issues, and offer programming assistance, enhancing developer productivity.
Please free to visit our post on LLMs (An onboarding guide to LLMs) for more in-depth detail.
Summarization and Content Extraction
Digging deeper into the summarization use case, retrieval involves searching through the available data to find content that best matches the user’s request. In retrieval-based models, the system identifies pre-existing pieces of content (e.g., sentences, paragraphs, documents) from a database that closely matches the user’s query and present them to him.
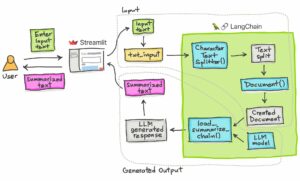
Image taken from Streamlit blog post about building a Text Summarization app with Langchain
Even though this sounds (and really is) amazing, it is not that straightforward. The output is directly related to the input (the famous Garbage-In-Garbage-Out comes into the scene). If we feed poor-quality data or incorrectly selected data into our models, we can expect that the result will also be of poor quality.
Some examples of “Garbage-In” are missing or imbalanced data, which affects the retrieval process, producing erroneous or bad-quality outputs.
Data Quality is at the heart of all ML(Machine Learning) applications, and LLMs are no exception. The purpose of this post is to explore the significance of data quality in the process of interacting with an LLM and improving its performance. In this sense, we will dive into what risks we should avoid and what considerations we should take when facing this meaningful task.
The Evolving Data Lakes: Navigating the Challenges
Dynamic nature of Data Lakes
A data lake is a powerful and versatile storage system that allows organizations to store vast amounts of structured and unstructured data in its raw form.
Data Lakes are built to scale horizontally, accommodating petabytes of data or more. This scalability ensures that as data volume grows, the system’s performance remains stable, making it suitable for big data workloads (as LLMs!).
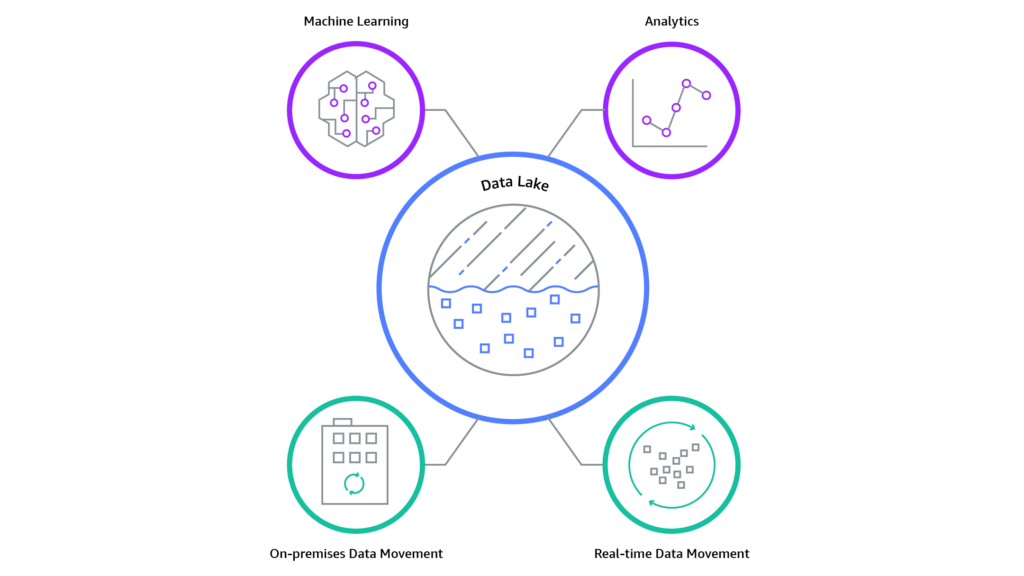
Image taken from What is a data lake? article by AWS
Data Lakes follow a “schema-on-read” approach. This means that data is ingested into the lake without the need to define a rigid structure beforehand, as is the case with traditional databases and Data Warehouses (“schema-on-write”).
Because of this, Data Lakes accommodate diverse data types and formats, making them incredibly flexible.
However, this flexibility comes as a double-edged sword that could end up doing more harm than good. Without the proper governance and a strong data quality strategy, what we wanted to be a Data Lake becomes the feared “Data Swamp”.

Imagen taken from dataedo very funny cartoon section
A data swamp is usually the result of a lack of processes and standards. Data in a data swamp is difficult to find, manipulate, analyze and, of course, work with ML models.
Collecting data points from multiple sources
As Data Lakes accommodate structured, semi-structured, and unstructured data, they allow organizations to handle a wide variety of data sources. This is particularly important in today’s data landscape where information comes from multiple channels and formats. Nevertheless, there are many challenges related to collecting data points from multiple sources, just to mention the main ones:
- Integration: Integrating these disparate sources requires complex data transformation and normalization processes to ensure data consistency and compatibility.
- Quality Disparity: Different sources may have varying levels of data quality. Some sources might contain incomplete, inaccurate, or outdated data, which can negatively impact the accuracy and reliability of analysis.
- Granularity: Data sources might provide data at varying levels of granularity. Integrating and aggregating data with different levels of detail can lead to challenges in maintaining accurate insights.
If all these challenges are not properly addressed, there is a huge risk to end up encountering the well-known “Data Silos”, where instead of having the desired “Source of Truth” we run into a sea of inconsistencies and incompatibilities. Attempting to work with an LLM in this kind of environment turns out to be a messianic task.
The Fragmented Truth: Unraveling Disparate Data Definitions
As we mentioned before, inconsistent data definitions would lead to poor LLM performance, but what exactly do we mean by “poor performance”? Let’s see some examples:
- Hallucinations: Hallucination refers to the tendency to generate content that seems plausible but is not based on factual or accurate information. This phenomenon occurs when LLMs produce text that appears coherent and relevant but is actually fabricated or invented, potentially leading to the generation of false or misleading content.
- Duplicity of Information: When we can not assure the uniqueness of the data, strange things can happen. LLMs may not be able to build a consistent context in an environment of duplicity leading to bad quality outputs.
- Lost of Dependencies: In the process of parsing large documents into smaller ones, important pieces of information are lost affecting the quality of the output negatively.
The Role of Data Quality in LLMs Performance
Let’s take a step back and try to better understand what Data Quality means and how it is measured. Data Quality is defined as the health of data at any stage in its life cycle. It involves ensuring that the data fits the needs of the business. Data quality can be impacted at any stage of the data pipeline, before ingestion, in production, or even during analysis.
There are six key dimensions that companies use to measure and understand their data quality. Let’s take a closer look at them.
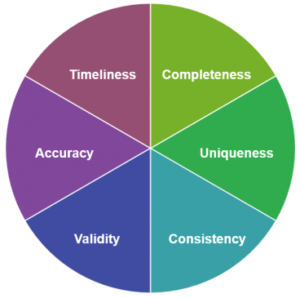
Image taken from Here is how to start with data quality article
- Completeness: It measures whether all required data elements are present in a dataset without any gaps or missing values.
- Timeliness: It evaluates whether data is up-to-date and available when needed for analysis, training or inference.
- Validity: It measures how well data conforms to pre-defined rules, constraints, and standards (i.e., format, type, or range).
- Accuracy: It measures how well the data accurately reflects the object being described ensuring that it accurately represents the real-world entities.
- Consistency: It examines whether data is coherent and in harmony across different sources or within the same dataset.
- Uniqueness: It ensures that each data record represents a distinct entity, preventing duplication.
With all this being said, it is clear that investing in a strong quality strategy is a no-brainer if we want to provide real value with the use of LLMs. For sure we can make up a fancy use case, but in the end, real-world use cases that provide real value with high-quality outputs are the ones who will thrive.
Let’s get a little bit more hands-on and explore a series of concepts and techniques to get this working.
Building a Quality-Driven Data Infrastructure for LLMs
Assessing Data Requirements
Whenever going through a project that involves getting value of an LLM, a first step is to identify the data needed to support the use case. In this stage, we will probably go through the famous 3 V’s of Big Data — volume, velocity and variety — to describe the shape of the data involved.
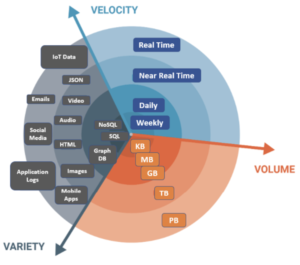
Image taken from packt article about 3 V’s of Big Data
We could also go over the Data Quality dimensions that we mentioned before and define how we want our data to behave.
Ensuring that entities are correctly identified and represented in datasets would be crucial. Entities would be the ones who represent and store information about specific items or things of interest in the shape of distinct, real-world objects, concepts, or individuals. Without the proper entity definition there would be no context for the LLM to work on.
Choosing the Right Data Storage
As we mentioned before, Data Lakes are a great option for when we need to store large amounts of data. Even though there are some caveats to consider (also mentioned) they continue to be one of the foundations on which every data project relies.
However, these systems rarely stand on their own. Instead, the necessity to include other tools arise when the use case becomes more complex.
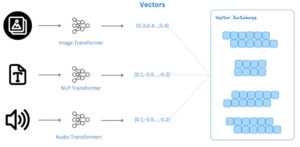
Image taken from decube.io blog post about Vector Databases
For example, Vector Databases are becoming more and more popular in the context of LLMs due their ability to store and manage high-dimensional vectors(such as those generated by LLMs!). These databases are optimized for efficient storage, retrieval, and similarity search of vector data. They are crucial for applications involving similarity comparison, recommendation systems, and content retrieval, where the relationships between data points are based on their vector representations in a high-dimensional space.
Implementing Data Documentation
Effective data documentation practices are essential for maintaining data lineage and preserving the context of data throughout its lifecycle. Proper documentation ensures that data remains understandable, traceable, and reliable over time. Implementing comprehensive data documentation includes:
- Document Metadata: Create a metadata repository that includes information about each dataset, such as its source, purpose, creation date, update frequency, owner, and relevant business rules.
- Capture Data Lineage: Document the journey of data from its origin to its various transformations and usages. Include details about extraction, transformation, loading (ETL) processes, and any intermediate steps.
- Include Schema Information: Detail the structure of datasets, including column names, data types, constraints, and relationships. This provides a clear understanding of the data’s layout.
- Provide Contextual Information: Offer explanations for key terms, acronyms, and domain-specific concepts present in the data. This contextual information helps users interpret the data accurately.
- Version Control: Implement version control for documentation. As data evolves, update the documentation to reflect changes and ensure that historical context is preserved.
Quality Assurance Techniques
Remember that we talked about Garbage-In Garbage-out at the beginning of the post? Well, data engineers adopted a well known technique to avoid it. It’s name is write-audit-publish (WAP) pattern.
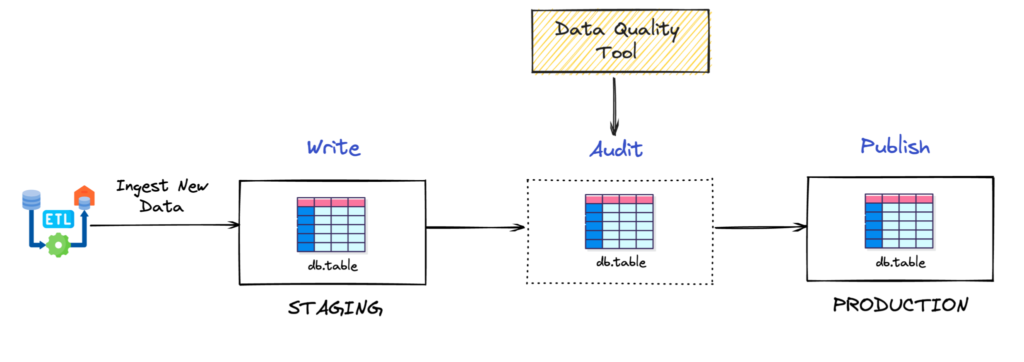
Image taken from Streamlining Data Quality in Apache Iceberg with write-audit-publish & branching article by dremio
The WAP technique is conformed by 3 elements: a staging section, a data quality validation process, and a production section. Notice that I wrote “section” instead of “table” for both staging and production. The reason for this is that the WAP technique could be extended beyond tabular structured/semi-structured data. Every piece of data(even text, audio or images) that is suitable for being tested against quality in any way, is also suitable for the WAP pattern. Let’s dive into each of the sections.
- Staging: Could be a table in a Data Warehouse or a text file in a Data Lake. Data comes raw or with little transformation directly from source.
- Data Quality Validation Process: Involves performing all the necessary Data Quality validations to assure that the data is production-ready. Remember when we talked about the six dimensions of Data Quality? Well, now it’s time to go all-in and turn them into real tangible tests. There are a few interesting tools that help build the testing platform such as Great Expectations, Soda and dbt tests.
- Production: If the Validation Process is passed, data moves to production sections where it is ready to be consumed for further transformation, analytics, ML model training, inference or retrieval.
Conclusion
Today we were able to realize the importance of Data Quality in the context of LLMs. We went through topics as storage systems, how data quality is measured, what implications could have a bad data quality strategy and also a straightforward pattern (WAP) on how to implement it today.
No matter how repetitive it sounds, if we feed garbage we will output garbage.
With all this being said, you have no choice but to treat your Data Quality Strategy as a first-class citizen. By investing in a scalable data foundation, where data is well documented, clearly owned, and structured you will be ready to leverage on LLMs to take your organization to the next level!


Hi there! Just wanted to let you know how much I enjoyed reading this post. Your approach to the subject was unique and informative. It’s clear that you put a lot of effort into your writing. Keep up the great work, and I can’t wait to see what else you have in store.