An onboarding guide to LLMs
By Ilana Stolovas
Large Language Models (LLMs) are capturing most of the AI-community’s attention over the past months. Keeping up-to-date to this world might look chaotic and quite overwhelming. This post pretends to sum up the highlights of this topic, diving into the technical details of these models while not neglecting the global view.
LLMs in a nutshell
LLMs are a subset of language models that have a particularly high number of parameters (typically billions) and are capable of generating human-like text. These models, like GPT-3, are trained on massive amounts of text and can perform a variety of language-related tasks such as language translation, text completion, and even composing articles and stories. They rely heavily on the Transformer architecture (Attention is All You Need, 2017) which is composed of two blocks: the encoder and the decoder. The encoder function is to process the input and “encode” the information that is passed to the decoder, using the attention mechanism over the whole prompt. The decoder generates the output token-by-token using the encoder’s output and its own generated tokens in an autoregressive way. It means that each output token is predicted looking at the tokens that came before it in the sentence, in a causal way.
Different kind of models were released using one or both types of transformer blocks, mainly grouped into three categories:
- GPT-like : also called autoregressive, only-decoder models.
- BERT-like: also called autoencoding models, only-encoder. They have full access to all inputs without the need for a mask. Typically, these models construct a bidirectional representation of the entire sentence.
- BART/T5-like: also called sequence-to-sequence or encoder-decoder.
Generative models belong to either the autoregressive or sequence-to-sequence families, as the decoder block is the one responsible for language generation.
Why LARGE models?
Natural language is complex and it is straightforward to think that we need large architectures to model it. But what do we mean by large? Google BERT, pioneer of the Transformers-based models, comprises 110M (base) to 340M (large) parameters. LLMs range from tens to hundreds of billions of parameters, which means orders of magnitude larger than other “traditional” language models – and by traditional we mean the ones discovered 4-5 years ago.

Model size comparison over last years.
The leap is huge! First of all, we are talking about foundation models – large models trained on enormous quantities of unlabeled data, usually through self-supervised learning, capable of a wide variety of tasks. These models are designed to be fine-tuned to downstream tasks, including even more data on this step. It is proved that when the parameter scale exceeds a certain level, these enlarged models show some special abilities that are not present in small-scale language models, such as the ability to follow in-context learning (i.e. adapting its output to few examples from prompting).
But only increasing model size is not enough to scale capability. LLMs require a massive amount of data to capture language nuances accurately. C4 Common Crawl corpus, one of the most used pre-training datasets, contains about 750GB of data, resulting in 175B tokens. Datasets are often used in combination to expand their knowledge with other sources, such as Wikipedia, Books, Github code or StackExchange/StackOverflow posts. Since LLMs are trained and fine-tuned on these datasets, information is therefore “memorized” in the model’s weights, which is only possible if having enough parameters to tune.
Getting to run these large models is not trivial in terms of hardware. While big companies can afford the infrastructure, the community is making the effort to optimize models to run on less resources (with techniques like LoRA-Peft or by using int8 precision).
Released architectures (to this date)
We will explore in more detail the foundation models that have been the protagonists of the last few years of research and development on language generation. There is a clear prominence of leading companies such as Google, Meta AI and OpenAI investing on these models training and, some of them, opening to the community for research and/or commercial purposes. Many of them are available in the Hugging Face platform, together with custom fine-tunings.
From past to present, the first outstanding models were BART (2019, encoder-decoder) and GPT-3 (2020, autoregressive). BART was designed to be a more flexible alternative to previous models like BERT and GPT-2, which were either autoregressive or bidirectional but not both. Following BART are T0, T5, mT5 (T5 multilingual) and UL2. These are transformer-based models capable of performing tasks including language translation, text summarization and question answering.
Many of them (the ones owned by Google) were fine-tuned using a technique called “Flan” (for Fine-tuned Language Net), improving zero-shot performance by applying instruction-tuning. As the paper says: “Because the instruction tuning phase of FLAN only takes a small number of updates compared to the large amount of computation involved in pre-training the model, it’s the metaphorical dessert to the main course of pretraining”. They built an instructions dataset by mixing existent datasets from natural language understanding (NLU), and natural language generation (NLG) tasks, and composed templates that use natural language instructions to describe the task for each dataset. To increase diversity, they also included some templates that “turned the task around,” (e.g., for sentiment classification, they wrote templates asking to generate a movie review).
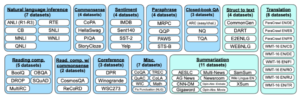
Datasets and tasks used in FLAN (blue: NLU, teal: NLG).
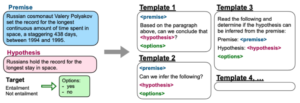
Instructions for NLI generated in FLAN.
But why is it that nobody talks about Flan? For the autoregressive family and after GPT-3 (2020) came InstructGPT (2022). GPT-3 was designed for prompt completion, trained to predict the next word on a large dataset of Internet text. Instead, InstructGPT goes far beyond being trained on instructions to perform the language task that the user wants. The boom started by the end of 2022, when OpenAI released ChatGPT, a sibling model to InstructGPT, which is trained to follow an instruction in a prompt and provide a detailed response. As it was made public, users worldwide started to experiment and discover its capabilities by themselves.
Other GPT-like models that came lately were OPT, Palm, Bloom, Dolly and LLaMA. The latter was released with only-research license, but many developers took advantage of the model and fine-tuned it with their own datasets. Since then, instruction-tuned models like Stanford Alpaca, Vicuna, Koala (and many guanacos) were born.
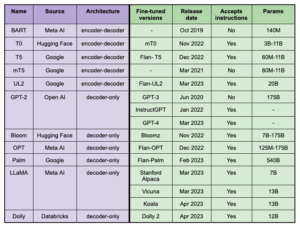
Relevant foundation models (purple) and their fine-tuned versions (green).
Attributes and innovation
What else should we know about these models? What are the trends on this topic? The following are some of the concepts used in SOTA models:
- Chain-of-thought: Prompting the model to explain step-by-step how it arrives at an answer, a technique known as Chain-of-Thought or COT (Wei et al., 2022) . Tradeoff: COT can increase both latency and cost due to the increased number of output tokens.
- RLHF: using methods from reinforcement learning to directly optimize a language model with human feedback. This technique trains a secondary model to “think like a human” (called reward model) and score the main model’s outputs. More on this topic can be found in Illustrating Reinforcement Learning from Human Feedback (RLHF).
- Prompt engineering: also known as In-Context Prompting, refers to methods for how to communicate with LLM by writing the model’s input to conduct its behavior for a desired outcome.
- Retrieval-augmented LLMs: Retrieval language models are used for instances in which we want the language model to generate an answer based on specific data, rather than based on the model’s training data. This is further explained in the next section.
Retrieval pipelines
While the ability to encode knowledge is especially important for certain NLP tasks, the described models memorize knowledge implicitly, making it difficult to determine what knowledge has been stored and where it is kept in the model. Furthermore, the storage space, and hence the accuracy of the model, is limited by the size of the network. To capture more world knowledge, the standard practice is to train large networks, which can be prohibitively slow or expensive. The ability to retrieve text containing explicit knowledge would improve the efficiency of pre-training while enabling the model to perform well on knowledge-intensive tasks without using billions of parameters. This would prevent the model from hallucination (instead of having the information to answer the query, the network makes it up in a realistic but inaccurate way).
Retrieval pipelines have documents stored and indexed for later retrieval. At query time, the documents that are most relevant to the query are retrieved and passed to an LLM, which is responsible for generating the answer. Useful open-source frameworks to build custom pipelines are Haystack, LangChain and Llama-index.
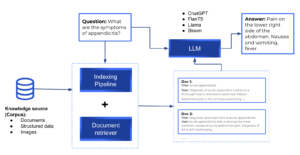
Retrieval general pipeline.
Final review
So far we have seen the big picture about LLMs and their potential on natural language understanding and generation. We went through the basics of large language models and the capabilities of billion-params models, and discovered the most relevant architectures up to now. We make explicit that the innovation is not due to the architecture components (as LLMs are based on Transformer blocks) but to the training and fine-tuning of the models.
From our point of view, what is the cause of this explosion in language models? Taking advantage of large models that are pre-trained on a huge corpus allows you to only focus on fine-tuning to your downstream task. And, for some models like ChatGPT, you may not even need any fine-tuning. Since OpenAI released their model to the public, a lot of hype has spread around this topic and many developers want to be up to par, flooding social networks with their own implementations. Relax, most of them rely on the same structures and introduce a new fine-tuning technique or dataset (as the case of all llama babies).
Many people believe that ChatGPT has the potential to replace search engines due to its vast amount of information and aggregating personalized responses. Google has even instructed some teams to shift their focus towards developing AI products, while Microsoft has entered the chatbot market with Bing Chat, which combines ChatGPT with their search engine. However, to fully replace search engines, ChatGPT models need to cite sources for their responses, therefore search engines still have the advantage when it comes to providing accurate and reliable information. Additionally, search engines have the ability to crawl the web and gather information from a wide range of sources, while ChatGPT relies on pre-existing data. Retrieval techniques may come to solve this issue, together with the use of agents, to boost large models capabilities. Great things like Auto-GPT are coming!
In conclusion, the rise of Large Language Models (LLMs) has revolutionized natural language processing and opened up exciting possibilities for artificial intelligence. With the ability to pre-train models on massive amounts of data, LLMs can achieve remarkable performance on a wide range of language tasks, from text classification to machine translation. While the architecture of LLMs is based on Transformer blocks, their true power lies in the training and fine-tuning of these models. Although running these large models can be challenging in terms of hardware, the community is working to optimize them to run on less resources. With the continued development of LLMs, we can expect even more breakthroughs in natural language understanding and generation in the future.

