Diffusion models for video generation
By Joaquin Bengochea
Introduction
Diffusion models have earned a special place in the AI visual Content Generation landscape, dethroning GANs and positioning themselves as the go-to approach when creating realistic content. As technologies like LoRAs and Latent Consistency Models arrived, these models started to be less restrictive in terms of time and computing resources, and new possibilities and applications started to emerge. This was the case of video generation models, an area that had an exponential growth in the last few years, with hundreds of papers on 2023 showing that the milestone of producing high quality videos in a reliable way is just around the corner.
In this blog we will make a technical summary of the use of diffusion models to generate videos, not just diving into a particular paper, but digging into the architectural decisions that are taken by different authors instead, generalizing and categorizing their approaches, pretending that, after this, the reader could have a general idea that will enable them to understand specific solutions more easily.
Applications
Video diffusion model applications can be categorized by their input modalities, like text, images, audio or even other videos. Some models can also use a combination of different modalities, such as text and images. The video to video generation can also be separated into video completion, when the idea is to add more frames to the existing video, and video editing, when the task is to modify the existing frames to add a style, color or change an element.

Different kinds of conditioning [1]
Usually, authors use different kinds of information simultaneously, allowing more control over the generation. For example, papers like DreamPose [2], AnimateAnyone [3] and FollowYourPose [4] use pose estimations over an existing video to condition the generation. Analogously, Gen-1 [5] and MakeYourVideo [6] use depth estimations over an original video. MCDiff [7] takes an original approach, animating images using motion information represented as strokes over the image. Lastly, ControlVideo [8] has the ability to use different kinds of controls like pose, depth, canny filters and more.
Architecture: starting from images
We will start with some common knowledge about diffusion models applied to images. This topic is addressed on our previous blog “An Introduction to Diffusion Models and Stable Diffusion”, but it is important to refresh some concepts before delving into video models.
The process of generating an image with a diffusion model involves a series of denoising steps from a noisy input, conditioned on some other source of information, such as a text prompt. The most generally used model for this denoising process is a UNet. This network is trained to predict the amount of noise in the input, which is subtracted partially in each step.
Diffusion Model architecture based on the U-Net [9]
The UNet architecture is then modified and VisionTransformer blocks are added after each UNet block. This serves two purposes: first, it incorporates spatial self-attention, sharing information of the whole image. Secondly, it incorporates cross-attention, conditioning the denoising process on guiding information, such as text prompts.
The computational cost of these models is substantial, so in order to generate high resolution images, authors usually apply techniques such as Cascaded Diffusion Models or Latent Diffusion models, which we will describe below.
Cascaded Diffusion Models
Cascaded Diffusion Models consist of multiple UNet models that operate at increasing resolutions. The result of a low-resolution UNet is upsampled and fed as input to another one, which outputs a higher resolution result. This approach is the one taken by models that operate at pixel level, such as Imagen [10], ImagenVideo [11], VDM [12] and Make-A-Video [13]. The use of CDMs has largely vanished after the adaptation of Latent Diffusion Models that allow for native generation of high-fidelity images with limited resources.
ImagenVideo cascading models [11]
Latent Diffusion Models
Latent Diffusion Models bring significant improvements to the UNet architecture, and became one of the main solutions when tackling problems of image and video generation. The idea behind it is to convert the inputs from a high resolution RGB space to a latent representation with lower spatial dimensionality and more feature channels.
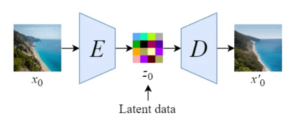
Illustration of an autoencoder as proposed by the Stable Diffusion paper [14]
Using a Variational Auto-Encoder (VAE) for initial input encoding before integrating with the UNet is the key strategy. Then, the denoising process is executed in that latent space, and the denoised latent is finally taken back to pixel space with the VAE decoder. This allows to save significant computational power, empowering the generation of higher resolution images compared to previous models. Examples of this approach are VideoLDM [15], Gen-1[5] and Gen-2 [16], SVD [17] and AnimateAnyone [3].
So far we explained the common architecture of diffusion models. In the next section we will dive into the modifications that make it possible to generate videos instead of images.
Bringing images to life: Adding the temporal dimension
To extend the functionality of image diffusion models to video it is necessary to have a method to share information between the different frames of the generated video, or what is the same, to add a temporal dimension to the so far spatial information included in the image model.
The input of the model then goes from a single noise image to one for each frame in the desired output, and the ViT blocks of the UNet are extended with temporal attention layers. These layers have the task of making the patches of a frame to attend to other frames, and are responsible for the temporal consistency of the generated videos.
Comparing attention mechanisms
There are different ways for the query to attend between the frames in these layers, resulting in multiple approaches:
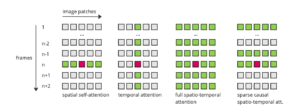
Examples of different spatial and temporal attention approaches [18]
Spatial Attention: As a reference, in this kind of attention the query in a specific patch attends to all of the other patches in the image.
Temporal Attention: In this case, the query attends to the patches that are at the same location in all other frames. Models like VideoLDM [15], Nuwa-XL [19] and ImagenVideo [11] (on their low-res model) use this kind of layers.
Full Spatial-Temporal Attention: This is the most cost-expensive form of attention, as each patch attends to all other patches in all other frames. It has great results but the computational cost makes it difficult to apply on long videos. Examples of this are in VDM [12] and Make-A-Video [13].
Causal Attention: This approach is an optimization of the previous one, trying to economize resources. Just like in real life, each present frame can use information from the past, but not from the future. That way, each patch will attend to every patch in that frame and all the preceding ones. MagicVideo [20] and Make-Your-Video [6] take this approach.
Sparse Causal Attention: Going further down the line, Sparse causal attention limits the amount of previous frames taken into account. Typically, each patch attends only to the other patches in their frame, the immediately preceding one and the first frame, saving even more resources. Tune-A-Video [21] and Render-A-Video [22] use this method.
Achieving longer videos
Even with the cheapest of the attention methods, the number of frames that a model can generate is limited. Current hardware is only capable of generating a few seconds of video on a single batch. Researchers have studied several ways to overcome this limitation, and two main techniques arised: hierarchical upsampling and auto-regressive extension.
The idea behind hierarchical upsampling is to first generate spaced-out frames, and then complete the gaps between them generating more, using an interpolation between the existing frames or by doing additional passes of the diffusion model. Examples of models that use this technique are Make-A-Video [13], ImagenVideo [11] and Nuwa-XL [19].
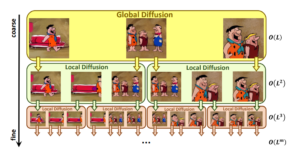
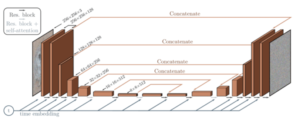
NUWA-XL hierarchical upsampling illustrated [19]
On the other hand, the auto-regressive extension involves utilizing the last few frames of a generated video to influence the generation of subsequent frames. From a technical standpoint, this approach enables the potential for an infinite extension of a video. However, in practical terms, the outcomes often experience increased repetition and a decline in quality as the extension lengthens. This technique is applied on models like VDM [12], LVDM [23] and VideoLDM [15].
Novel architectures
There are some other authors that came with novel ideas that do not totally fit in any of the previous categories. For example Lumiere [24] proposed changes over the UNet architecture, with their Space-Time UNet. The idea behind it is to add temporal downsamplings and upsamplings, along with the common spatial ones that characterizes a UNet. By doing so, they are able to compress the information both spatiallly and temporally, achieving, on one hand, a reduction in computational costs, and on the other hand, an improvement in the temporal consistency of the results.
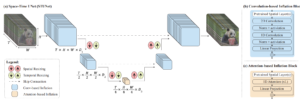
Lumiere Space-Time UNet [24]
Challenges to tackle
The last year came with an impressive amount of developments in the area of AI video generation, but there’s still a long way to go. In this last section we will summarize the main difficulties when training video diffusion models, that will hopefully be the focus of new advancements this year.
The more obvious one is the hardware resource limitation. For instance, even the biggest GPUs nowadays can only handle a few seconds of video. Even more, diffusion training is complex and requires a lot of data and hundreds of GPU hours. This makes the iteration over a model extremely challenging.
The lack of labeled training data is also a significant issue. Even though there are a lot of labeled image datasets with millions of data points, video datasets are usually much smaller. An intermediate solution that many authors have taken is to train on labeled image data first, and then train on unlabeled videos in an unsupervised manner, but that way it may be hard to capture finer video details like object-specific motion.
Regarding long video generation, it is yet to achieve a reliable way of modeling long temporal dependencies. Auto-regressive and hierarchical upsampling techniques try to help in this, but can lead to artifacts and suffer from quality degradation over time. This may be improved from the architecture side. With more processing power in the future, the adoption of full 3D spatial-temporal attention for longer videos might be able to capture those complex interactions.
The pace at which developments are made is only increasing, with more and more authors taking significant steps. The road to high-quality long video generation is tough, but it is only a matter of time until we get there. We are really excited to see what the next big jump will be.
References
- A Survey on Video Diffusion Models, Xing et al. (2023)
- DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion, Karras et al. (2023)
- Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation, Hu et al. (2023)
- Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos, Ma et al. (2024)
- Structure and Content-Guided Video Synthesis with Diffusion Models, Esser et al. (2023)
- Make-Your-Video: Customized Video Generation Using Textual and Structural Guidance, Xing et al. (2023)
- Motion-Conditioned Diffusion Model for Controllable Video Synthesis, Chen et al. (2023)
- ControlVideo: Training-free Controllable Text-to-Video Generation, Zhang et al. (2023)
- An In-Depth Guide to Denoising Diffusion Probabilistic Models – From Theory to Implementation, Singh (2023)
- Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding, Saharia et al. (2022)
- Imagen Video: High Definition Video Generation with Diffusion Models, Ho et al. (2022)
- Video Diffusion Models, Ho et al. (2022)
- Make-A-Video: Text-to-Video Generation without Text-Video Data, Singer et al. (2022)
- Stable Diffusion Clearly Explained!, Steins (2023)
- Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models, Blattmann et al. (2023)
- Gen-2: The Next Step Forward for Generative AI, Runway (2023)
- Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets, Blattmann et al. (2023)
- Video Diffusion Models – A Survey (2023)
- NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation, Yin et al. (2023)
- MagicVideo: Efficient Video Generation With Latent Diffusion Models, Zhou et al. (2022)
- Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation, Wu et al. (2023)
- Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation, Yang et al. (2023)
- Latent Video Diffusion Models for High-Fidelity Long Video Generation, He et al. (2023)
- Lumiere: A Space-Time Diffusion Model for Video Generation, Ber-Tal et al. (2024)


I do not even know how I ended up here but I thought this post was great I do not know who you are but certainly youre going to a famous blogger if you are not already Cheers