Edge computing: deploying AI models into multiple edge devices
By Lucas Berardini
Imagine you have to develop a computer vision application that must run in an industrial or agricultural environment with limited connectivity. Think, for example, of an application that detects plagues using a camera mounted on agricultural machinery. Now imagine an application that monitors some machine in an industrial plant and needs to raise a real-time shutdown alarm every time a problem is detected, to prevent the machine from severe damages. These are just a few examples of applications where there are relevant limitations in terms of connectivity between the place where the data is captured and the server where the Machine Learning application will run. These limitations become even more significant when there is a requirement for near real-time response, which usually leads to solving the problem with edge computing architectures. In a high-level overview, a typical Machine Learning application will resemble the following diagram:
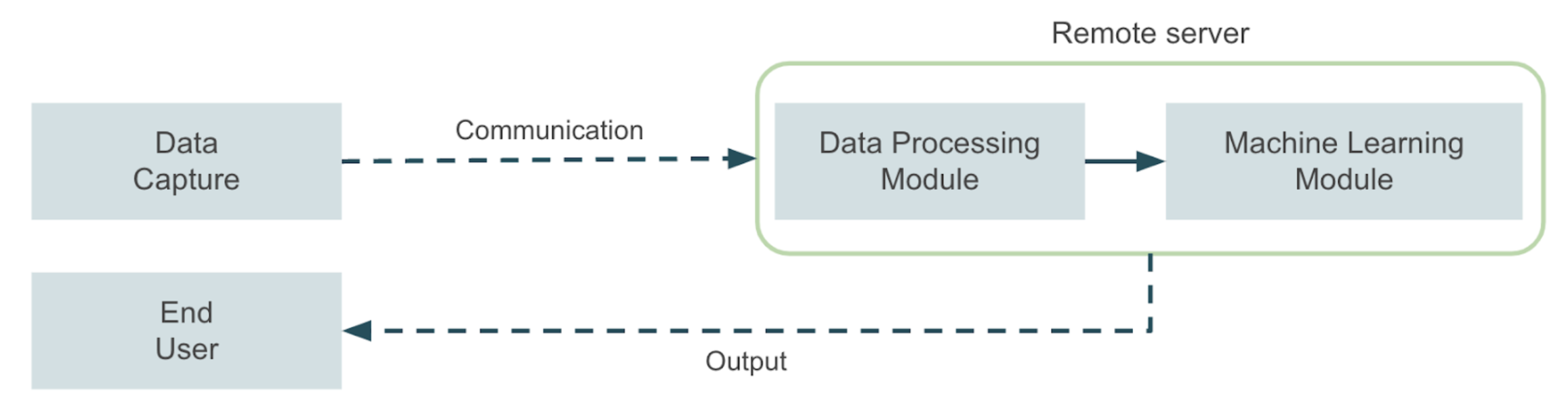
A data capture module sends the data to a remote server where all the Machine Learning tasks take place. Then, the server sends the application’s output to an end user, also via remote communication. Now, in our examples it might not be possible to implement such a solution due to the mentioned limitations, so we must ask ourselves how we can address this kind of problem in a more effective way. The answer to this question lies in the field of edge computing applications. In this case, a hardware device optimized for Machine Learning tasks is used to bring the inference as near to where data is produced as possible. This approach improves inference times and makes it possible to leverage AI solutions in a wider set of environments.
In this post we will explore some alternatives for designing architectures to deploy production-ready edge computing applications for Machine Learning in multiple edge devices using different Cloud vendor alternatives for centralizing the training and deployment stages.
Framing the problem
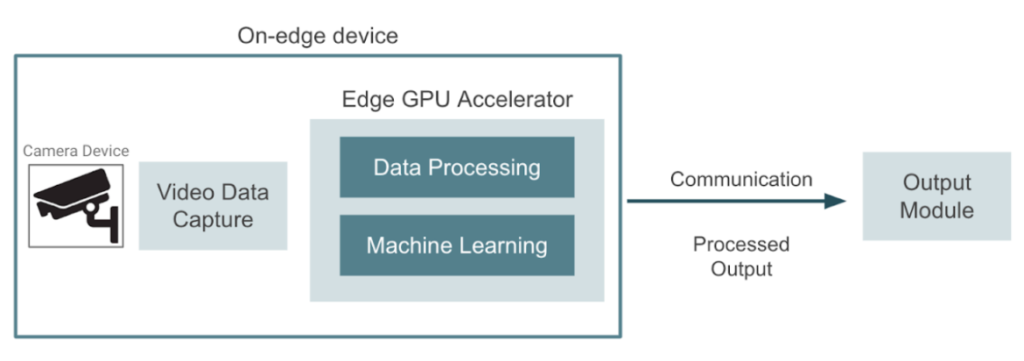
The image below shows a high-level diagram of what we are trying to build. A device captures video in real-time which needs to be processed, and the goal is to leverage edge computing devices that can be used to bring machine learning near the camera devices. In this case, the edge device takes care of both data pre processing and machine learning tasks. The application may involve object detection, face recognition, image segmentation, or any other computer vision task. Finally the edge device send the result to an output module where end users can consume it. In order to run machine learning inference in such an environment, it is necessary to deploy the trained models using external GPU accelerators that make it possible to run inference on-site.
In contrast, the more usual approach would be to use the camera devices only for data capture, and send the video to a cloud provider or a dedicated server. This server usually handlers all data processing, machine learning inference and output generation. In this other case, model training pipelines and deployment jobs take place in the same cloud environment. The following diagram represents this approach:
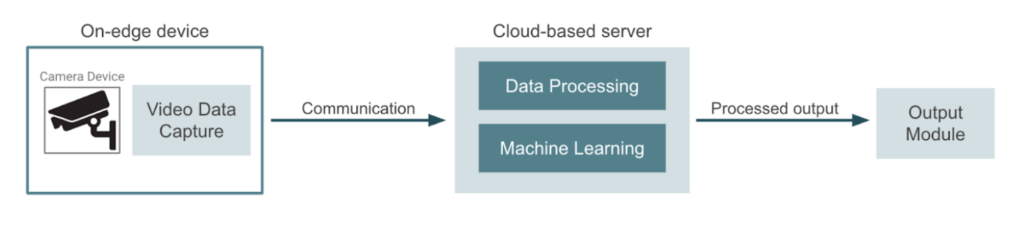
Edge computing vs cloud-based computing
At this point, we could ask ourselves which approach will give us the best cost/benefits outcome. If we decide to go for an edge-based approach, we can think of the following advantages:
- Latency-sensitive applications can be executed right next to where the data is being generated, which improves response latency.
- It is possible to tolerate unstable Internet connectivity. This scenario would not allow, for example, to stream a video to be sent frame-by-frame to a server.
- We can ensure data privacy, since the input data will never leave the edge device.
- It is possible to handle a large number of devices performing inferences using the same models in different locations.
Naturally, there are also some disadvantages that needs to be considered when designing the solution:
- Computational load on edge devices is relatively high, and any failure on the edge devices will end up breaking the application.
- Project costs could escalate due to the dedicated hardware used in each edge device. This might be prohibitive in applications with massive amounts of devices.
- GPU resources are static and up or down scaling based on the workload is not possible.
- There is some additional work needed to coordinate the deployment and updates of the models across all devices.
Ultimately, the decision to go for an edge-based or cloud-based solution will depend on a trade-off between latency and cost. If latency is a critical factor, or if if the operating environment is complex, then an edge-based approach would be the best choice. If the designed application supports some latency tolerance (near real-time inference), then a cloud-based approach might be the way to go.
Since we want to focus on deploying edge-based applications, for the rest of this post we will explore some alternatives to deploy models in multiple devices.
Deploying trained models into multiple edge devices
The main challenge we will address in this blog is related to training a model on labeled data and then deploying this model to many edge devices distributed across different locations. The image below shows a cloud-agnostic diagram of this process:
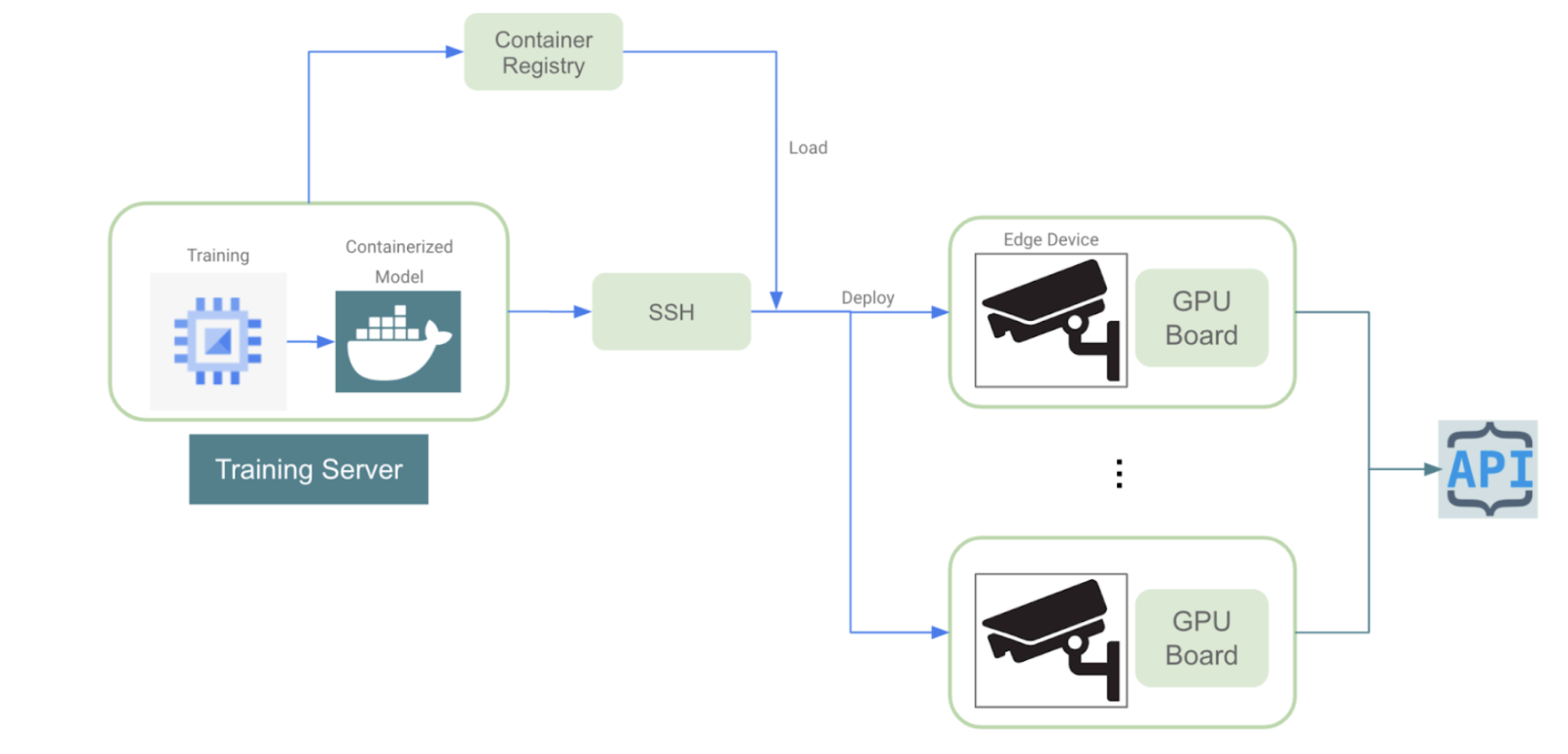
Here’s the technical side of how it works:
- The training phase takes place on a specialized server with GPU capabilities. In this stage the developers iterate until they reach a model with desired output performance. Once we finished training, we can containerize the model in an image. We will need to deploy this image on each edge device.
- The containerized applications are pushed to a container registry from which the devices can pull the image and run the deployment.
- For model deployment, we need to establish a secure remote connection between the server and each edge device. Then, the model image is pulled from the container registry. This secure channel ensures encrypted and reliable communication.
- All edge devices are instrumented with GPU boards that run the deployed algorithm. These GPU boards augment the computational capabilities of edge devices, enabling them to handle the complexity of deployed models efficiently.
- Once the model is deployed and running on all devices, the results from each device are sent to an external API. This API serves as a conduit to receive event notifications from the devices, providing real-time feedback on device status and performance.
Most of the cloud vendors provide a service or set of services that can be used to develop a deployment flow similar to what we described above. We will delve into each of the vendors and explore some alternatives in the following sections.
Extending AWS capabilities via IoT Greengrass
The Amazon cloud provides a service called AWS IoT Greengrass, which is useful to extend AWS functionality into edge devices, allowing them to act locally on the data they generate, even when they are not connected to the cloud. By using this service we can perform machine learning inference locally on edge devices, using models that we create, train, and optimize in the cloud. It allows the deployment of AWS Lambda functions and containerized applications on edge devices. The image below shows an overview of a deployment architecture using this service:
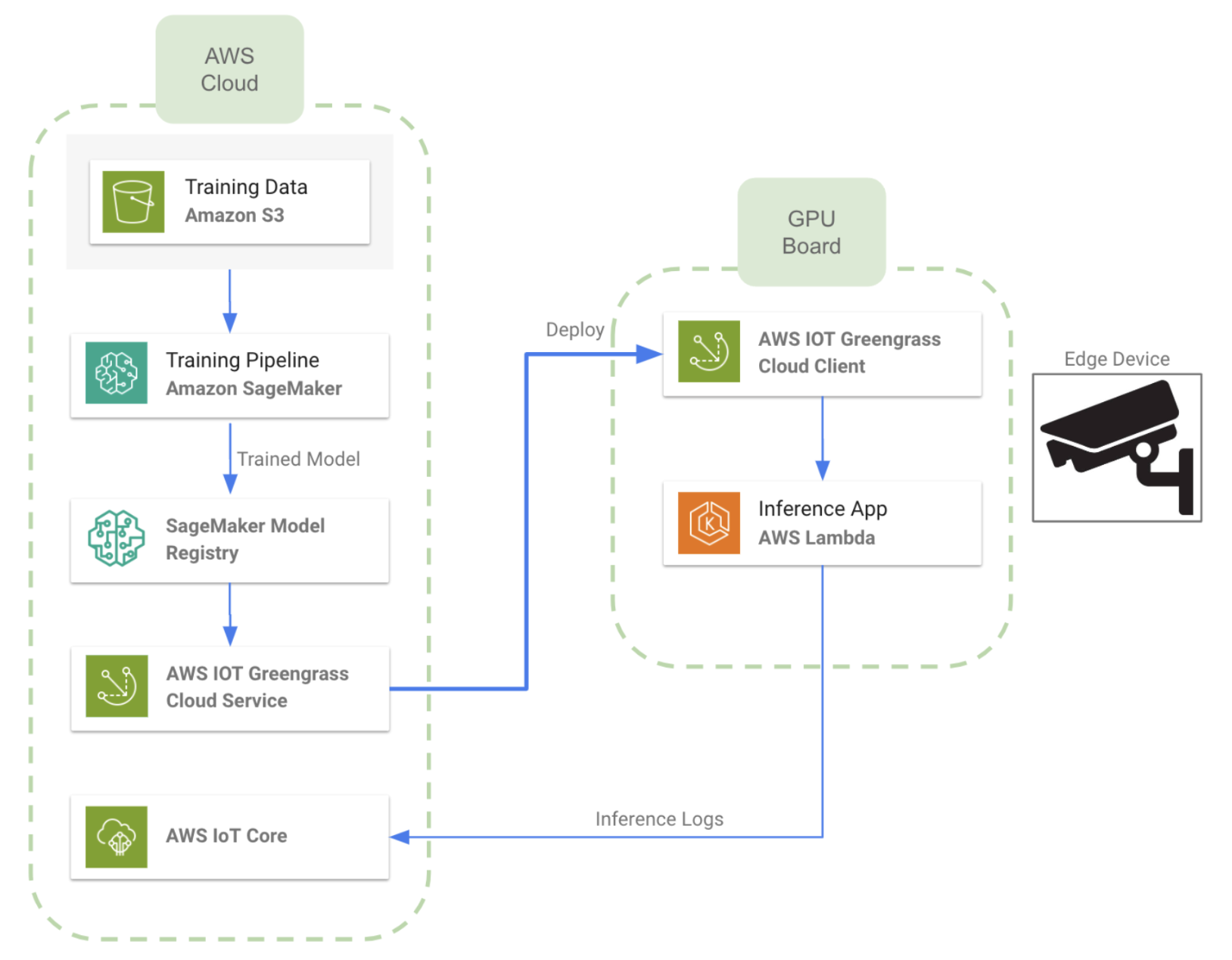
In a nutshell, the architecture includes training a model on the cloud with stored data, and then deploying it to multiple devices. By installing the AWS Iot Greengrass client on the edge devices, it is possible to perform this deployment seamlessly. Some key features of the architecture shown above are the following:
- We train the Machine Learning using a SageMaker pipeline and we use SageMaker Model Registry for model versioning and storing. It would be possible to replace this step with a more on-demand trained pipeline executed on an EC2 GPU instance.
- We establish a remote connection between the cloud and the edge device by means of AWS IoT Greengrass service, which needs to be installed on all devices.
- We deploy the model into a Lambda Function within the GPU board on the edge’s device side.
- Additionally, we can use the AWS IoT Core service to if send inference logs back to the cloud.
Microsoft Azure deployment using IoT Edge
When analyzing the available services, we can note that an architecture almost equivalent to the one described for AWS can be developed using IoT Edge, which is a service that extends the capabilities of Azure IoT solutions to edge devices. It allows us to run cloud intelligence directly on IoT devices, enabling real-time data analysis and decision-making at the edge. The image below shows how the architecture would look like when developed in Azure:
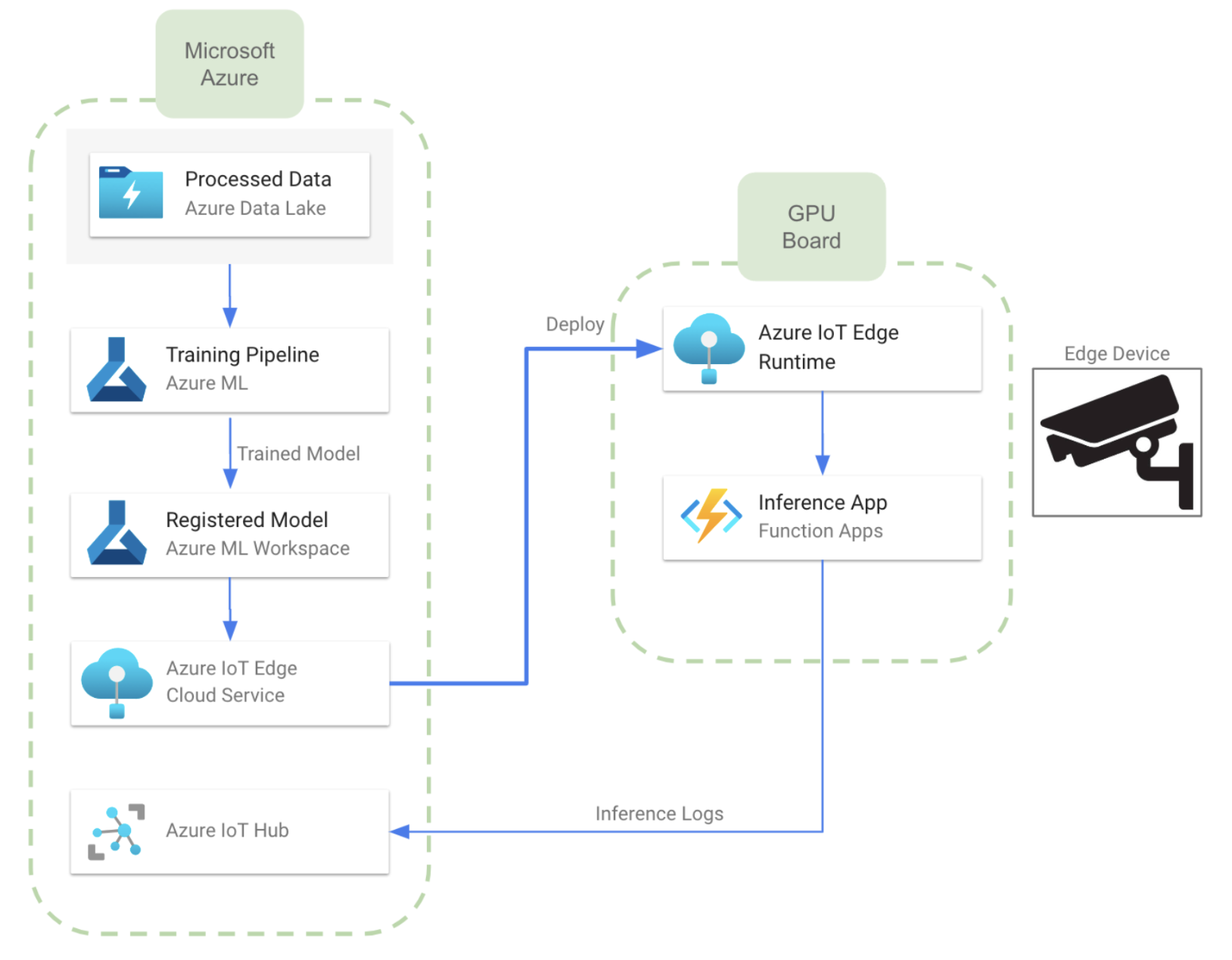
- In this case, we can train the model using Azure ML capabilities. We can also use an Azure ML Workspace for model versioning and storing. This will allow the user to manage different versions of the same model, or event different models
- The communication between the cloud and the edge devices is carried out by Azure IoT Edge service. To this end, we will need to install IoT Edge runtime in all edge devices.
- Once we transfer the model to the devices, we can deploy them in an Azure Function, as in the diagram above. It is also possible to use a containerized docker application.
- Similar to the AWS case, we can send inference logs to the cloud leveraging Azure IoT hub. This provides bidirectional connection between the cloud and the edge device.
As an additional comment, an alternative approach would be to use Azure Stack Edge, which is a cloud-managed edge computing platform that combines proprietary hardware and software components to bring Azure services and capabilities to the edge. Stack Edge hardware includes compute acceleration hardware that is designed to improve performance of AI inference at the edge, and since both hardware and cloud services are provided by the same vendor, integration is expected to be seamless but cloud interoperability (with other vendors) might be difficult.
Edge deployment on Google Cloud Platform
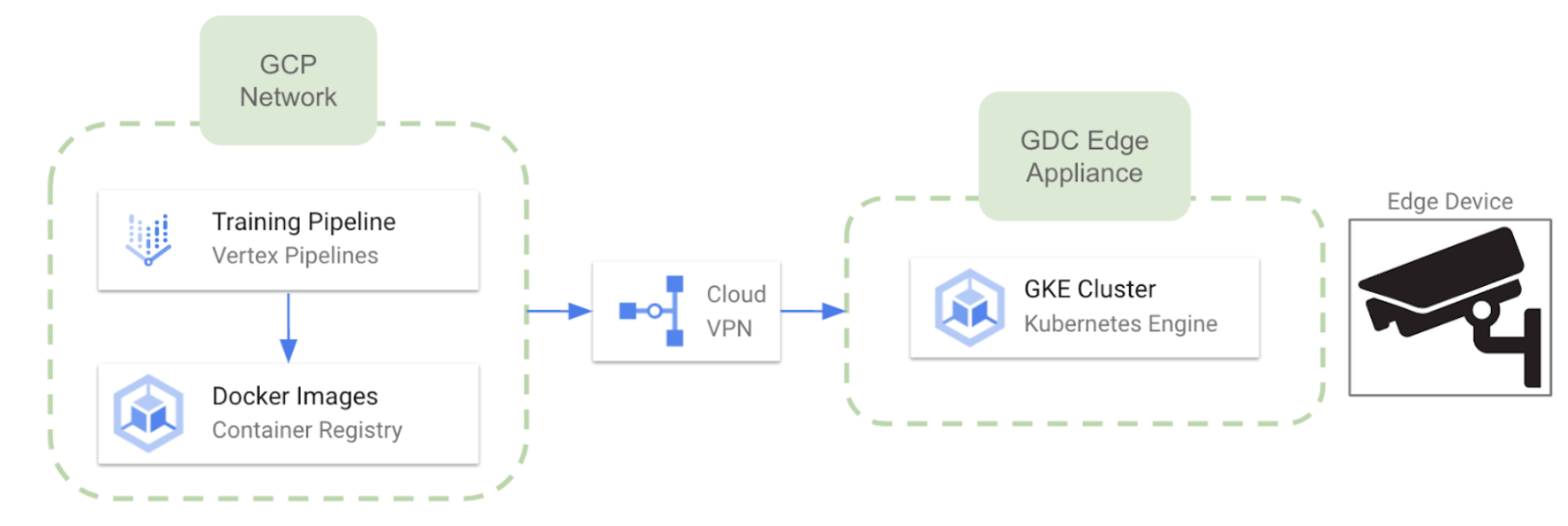
Since Google has recently decided to deprecate its IoT Core services, we can expect bit more difficult connection with edge devices compared to the other cloud providers. Nevertheless, it is possible to leverage Google Distributed Cloud Edge which enables to run Google Kubernetes Engine clusters on dedicated hardware provided and maintained by Google. Google delivers and installs the Distributed Cloud Edge hardware on your premises (with region limitations at the moment). Some relevant features about this approach are the following:
- The dedicated hardware is Google Distributed Cloud Edge Appliance
- Once the hardware is ready, we can deploy multiple GKE clusters in the Edge from the GCP environment.
- Bidirectional communication between the cloud and the appliances is available
Hardware alternatives for edge computing applications
As commented earlier, performing Machine Learning inference in the edge devices involves the use of some kind of GPU accelerator. To this end, NVIDIA and Google Coral offer several hardware alternatives to select, depending on different performance needs. The main goal of these devices is to bring powerful computing capabilities to the edge while maintaining a compact form. The following is just a list of possible hardware alternatives available in the market:
NVIDIA Jetson Series
- Jetson Nano: Positioned as an entry-level device, the Jetson Nano boasts a CUDA-enabled GPU, enabling the parallel execution of multiple neural networks. Packed with various I/O interfaces, its price starts at $100.
- Jetson Xavier NX: Going further in performance capabilities, the Jetson Xavier NX can handle multiple neural networks and supports 4K video encoding and decoding. Its price starts at approximately $400.
- Jetson AGX Xavier: At the top of NVIDIA’s offerings, the Jetson AGX Xavier better hardware capabilities compared to the Xavier NX. This high-end module comes with a price tag of around $1000.
Google Coral’s Edge Computing Platform
- Coral Dev Board: The Coral Dev is single-board computer, similar to a Raspberry Pi. Priced at approximately $130, it serves as a development platform for running and prototyping AI models at the edge. It is equipped with an integrated Edge TPU, which facilitates efficient on-device inferencing.
- Coral USB Accelerator: It a USB-based hardware solution that can be connected to existing devices, including Raspberry Pi boards. Priced around $60, it mirrors the Edge TPU capabilities of the Coral Dev Board, providing an economical option for accelerated on-device inferencing.
Conclusions
One of the main challenges in the field of edge computing AI is to deploy a trained model or application in multiple devices coordinately. We have addressed some alternatives to develop a deployment strategy in different cloud vendors. Additionally, we have explored some hardware alternatives that play a crucial role in this kind of architecture. Whether it’s real-time object detection, face recognition, image segmentation, or other computer vision tasks, the goal is to harness the power of GPU accelerators and bring machine learning closer to the camera devices. This approach not only streamlines data processing but also enhances the overall efficiency of on-site machine learning inference.


Normally I do not read article on blogs however I would like to say that this writeup very forced me to try and do so Your writing style has been amazed me Thanks quite great post