Finetuning LLMs: Enhancing Product Descriptions Efficiently
By Juan Pablo Lago
Going on with our blog series on Large Language Models (LLMs) today we will talk about a successful finetuning case. While a well-crafted prompt can get the job done in many scenarios, there are times where it might not be enough. Finetuning steps in when we need results of higher quality compared to using prompts alone. It also allows us to train the model on a more extensive set of examples, surpassing the limits of prompt-based approaches. In this blog we will explore a LLM finetuning application to generate e-commerce product descriptions.
The use case
E-commerce platforms can handle thousands of new products for sale every day. Writing commercially attractive product descriptions is not an easy task. Nevertheless, large language models can assist in crafting appealing descriptions tailored to a specific target audience. By prompt engineering Llama V2 13B Chat we developed a pipeline to generate descriptions based on a product list of attributes and its original (often unattractive) description.

The pipeline we developed includes two consecutive inferences with the model, combining multiple instructions to comply with the quality and format expected for the outputs. The results met the quality requirements that we were expecting. However, two inferences meant the time of generation doubled, reducing the generation throughput and increasing costs.
Why finetune
The decision to embark on finetuning stemmed from an important objective: to augment the throughput of the model while simultaneously reducing inference costs. The primary aim was to streamline the process, achieving the desired outcomes with a single inference in a more compact model. Finetuning, in this context, became the approach to improve the balance between performance and resource utilization resulting in a more efficient and cost-effective solution.
Building the dataset
We built a diverse dataset of 1000 generated descriptions together with their source products attributes and original descriptions. The products were chosen to cover a wide range of categories and original descriptions lengths. New descriptions were generated with the Llama V2 13B pipeline, involving two consecutive inferences to the model.
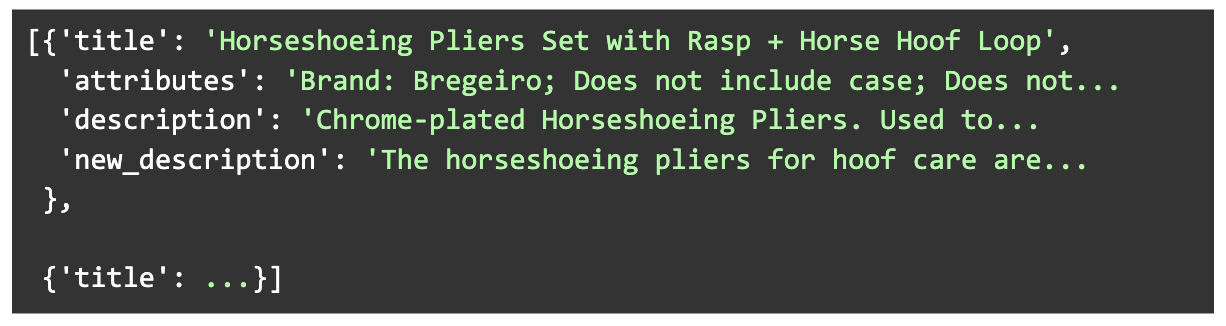
Also, to comply with hardware memory availability, we further filtered the dataset so that the total number of tokens of the input + output of the examples didn’t exceed a given limit.
Setup
For the training we used Ludwig which is a high level Python interface for building AI models. It allows for training of Large Language Models by just providing a configuration file and getting the training data in the right format (while using Pytorch and HuggingFace under the hood).
The model we chose to fine-tune was Llama V2 7B Chat. We used the 4 bit quantization version of the model and performed LORA (Low Rank Adaptation) parameter efficient finetuning. LORA is a finetuning technique where instead of training all the model parameters, low-rank layers are injected and only these layers are trained. In our case, this means a training size just 0.06% of the full model. Combining the 4 bit quantization with LORA for training (QLORA) is a highly memory-efficient approach that doesn’t sacrifice task performance.
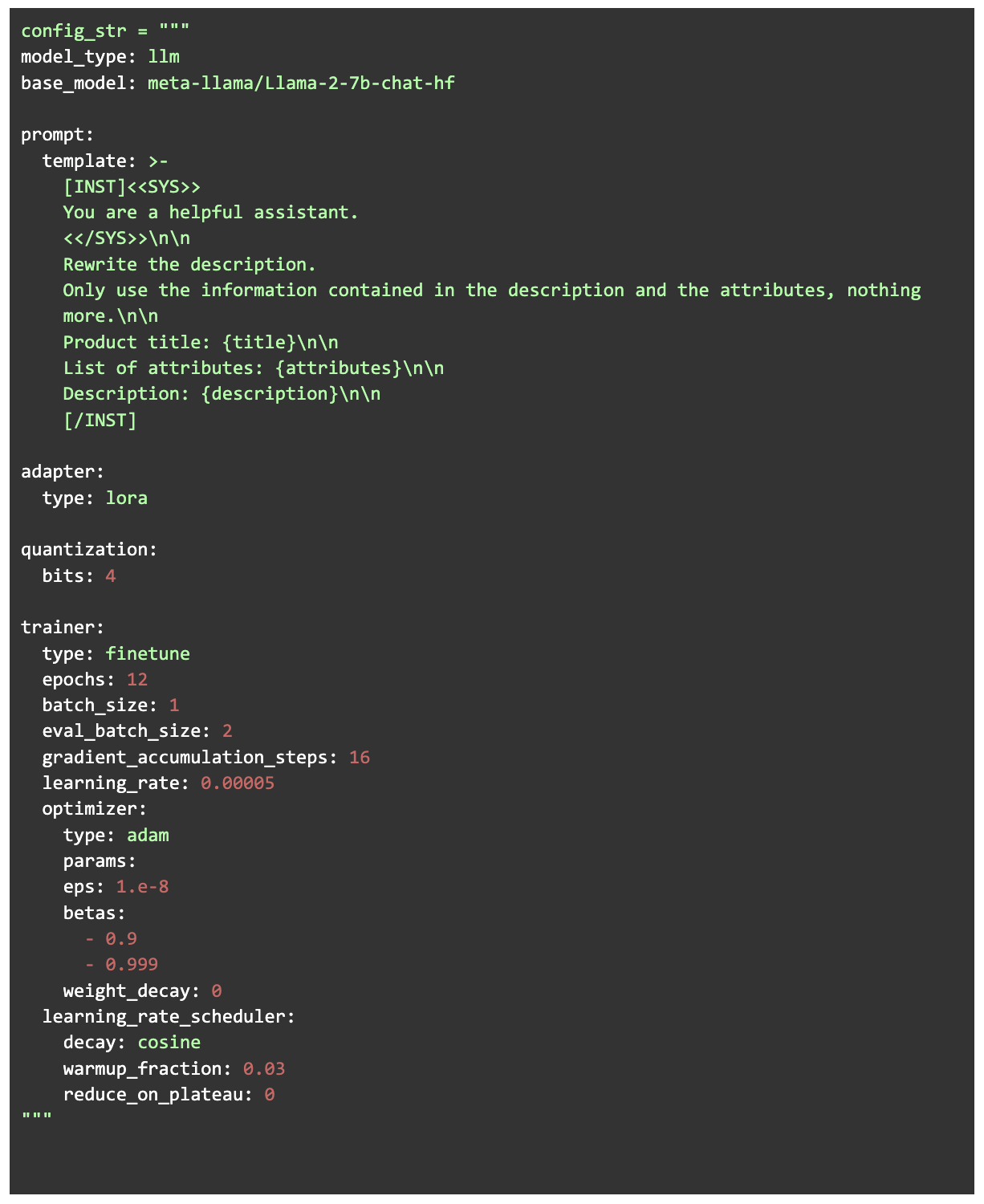
Training process
The training was done for 12 epochs on a A100 GPU with 40GB of RAM, with a total training time of about 3 hours. One of the things the model learned first was to replicate the style of the output, answering in paragraphs of the expected length. However, the model went through some ‘vices’ in the first epochs, which were overcome as the training advanced.

As a funny note, by epoch 5 the model was systematically following a particular answer style, by beginning the description with a creatively formed product phrase starting with ‘Nobody’. Some LLMs show a particularly creative flavor in their responses, Llama V2 Chat being definitely one of them. (We are planning a future blog post with a compilation of funny LLM answers we’ve been coming through – stay tuned!)
Results and human evaluation
We were very happy with the results! The fine-tuned model (Llama V2 7B, quantized in 4 bit) is about 25% the size of the original model we used to generate the ground truth outputs (Llama V2 13B, quantized in 8 bit). Nevertheless, the new outputs are very similar in quality, and in some cases even better than the original ones.

To quantify the comparison of the outputs of the two models we performed human evaluation. We presented teammates that have worked in domain related projects with shuffled and randomly picked answers of the two models to choose for the preferred one (or ‘tie’). These were the results.
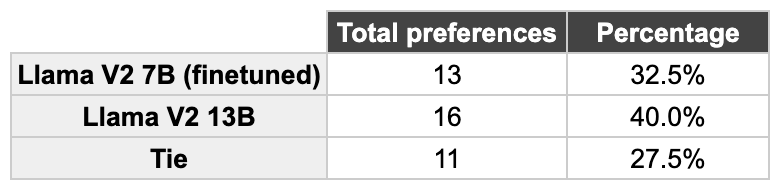
In 60% of the examples there was a tie or the Llama 7B answer was preferred. Also, there is just a 7.5% difference between the preference of the Llama 13B compared to the Llama 7B. These are very tight results, for a model that’s four times smaller than the original one!
Objective fulfilled
By making the description generation in a single inference with a smaller model, compared to the two inferences required with the original bigger model, we achieved a 4x throughput gain. Also, the 75% reduction in total inference memory allows for optimizing the infrastructure required to host the model and utilize smaller (and thus cheaper) virtual machines. These optimizations were achieved in a way that high output quality is not sacrificed and thus allow for a reduction of more than 80% of the cost of each generated description. We were really satisfied with the outcome.
Conclusion
Our exploration into finetuning Large Language Models (LLMs) revealed a promising application in generating e-commerce product descriptions. By carefully building a high quality dataset, finetuning can elevate result performance beyond the capabilities of prompts alone.
Strategically finetuning the Llama V2 7B Chat model achieved a remarkable balance between performance and resource usage. By implementing QLORA in a 4-bit quantized model version, we significantly optimized memory utilization and computational efficiency. This approach not only substantially reduced inference costs but also kept the high quality of generated outputs, showing that finetuning LLMs can be an invaluable tool for transferring knowledge from larger, more complex models to smaller ones, greatly optimizing resource utilization.

