Guiding LLM Behavior: The Art of Prompt Engineering
By Juan Pablo Lago
Large Language Models (LLMs) have revolutionized the field of artificial intelligence and natural language processing. These powerful models possess an incredible ability to generate human-like text and perform a wide range of language-related tasks. However, to truly unleash their power and achieve specific goals, careful and strategic prompt engineering is essential. By crafting well-designed instructions, or prompts, we can guide the model’s output, ensuring accuracy and contextual appropriateness.
In this blog post, we’ll explore some of the most popular prompt engineering techniques that serve as effective tools for shaping the behavior of LLMs and enhancing their performance.
Thinking through tokens

From the talk State of GPT[1], by Andrej Karpathy
The slide from the (recommended) talk State of GPT by Andrej Karpathy presents an example of a process that a human would typically follow to answer the question “How does the population of California compare to that of Alaska?”. Specifically, the process involves breaking down the question into smaller parts, gathering information from external sources, using a calculator, conducting two verification steps (one for reasonableness and the other for spelling), and rectifying any mistakes. It’s important to note that this process is more intricate than simply obtaining the number (token) 53 in one go.
The training of Large Language Models (LLMs) consists of predicting the most likely next token based on statistics from a large corpus of data. However, most of this data isn’t structured in the same way as the complex thought process, research and verification steps involved in answering intricate questions. In simple terms: in the training data we will much more often see text like “The population of California is 53 times the population of Alaska” than the expanded reasoning process that we presented before. But what happens when the exact piece of information we are looking for isn’t present in the training data and must be obtained by combining and refining different pieces?
To ensure that LLMs follow a reasoning process to arrive at answers, we need to guide them by providing them with “tokens to think”. In other words, we must direct the LLM’s answer generation process to stimulate the thinking process through the output tokens. Prompt Engineering techniques will help us do just that.
Recommendations for dealing with LLM problems
The following is a possible set of steps to follow when working with LLMs extracted (with minor changes) from the talk State of GPT[1].
- Use prompts with detailed task context, relevant information and instructions.
- Experiment with Few Shot Examples that are: 1) relevant to the test case, 2) diverse (if appropriate)
- Retrieve and add any relevant context information to the prompt (Generated Knowledge Prompting)
- Experiment with Prompt Engineering techniques (CoT, Self Reflection, Decomposed Prompting, Self Consistency)
- Experiment with tools to offload tasks difficult for LLMs (calculator, code execution, search apis, etc)
- Spend quality time optimizing the pipeline/chain.
- If you feel confident that you maxed out prompting, consider data collection + supervised finetuning.
- Expert / fragile / research zone: consider data collection for a reward model + RLHF finetuning.
In the rest of this blog post we will be reviewing prompting strategies that are relevant to steps 2 to 4 of the process of developing a solution based on LLMs.
Prompt Engineering Techniques
In this section we will provide an overview of some of the most popular prompting techniques, offering concise explanations, examples of usage, and references for further reading. According to your use case, some techniques will be more relevant than others. Don’t restrict too much to the examples as they are not exhaustive: you should better think of the techniques as conceptual tools that could be applicable to your use case.
Few Shot Prompting
It involves providing examples to the model of the type of response we expect.
Example

Few shot prompting example
Generated Knowledge Prompting
It consists of incorporating relevant knowledge related to the instruction before generating the final response. It is analogous to conducting a research process prior to answering.
For the generation of relevant knowledge, both the model itself (net weights) and an external source (retrieval from a document database) can be used.
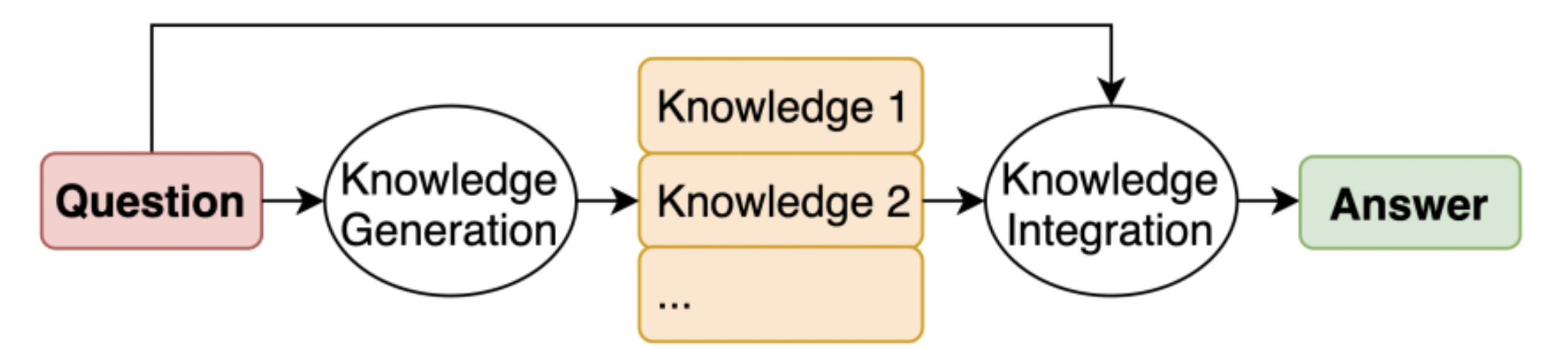
Image taken from the paper Generated Knowledge Prompting for Commonsense Reasoning[3]
The generation of knowledge is achieved using a Few-Shot prompt. For each instruction, M knowledge sentences are generated (where M = 20 in the article). These sentences are then concatenated with the instruction, resulting in M distinct responses. The final response is obtained by combining all the responses (in the case of classification, this is done by majority voting).
Example

Example taken from the paper Generated Knowledge Prompting for Commonsense Reasoning[3]
Chain of Thought (CoT) Prompting
It involves instructing the model to decompose the answer process into intermediate steps before providing the final response. The simplest way to achieve this is by including the instruction “Let’s think step by step” (Zero Shot CoT, see Large Language Models are Zero-Shot Reasoners[4]), but it can also be of value to include examples of the decomposition of the answer (Few Shot CoT, see Chain-of-Thought Prompting Elicits Reasoning in Large Language Models[5]).
Examples

Zero-shot CoT example from the paper Large Language Models are Zero-Shot Reasoners[4]

Few-shot CoT example from the paper Large Language Models are Zero-Shot Reasoners[4]
Self Reflection
It involves adding a verification layer to the generated response to detect errors, inconsistencies, etc.
It can be used in an Iterate-Refine framework, where the model is asked if the generated response meets the instruction (or if it contains errors), and if not (if yes), a refined response is generated.
Example

GPT4 response, from Can LLMs Critique and Iterate on Their Own Outputs?[6]
Decomposed Prompting
It involves generating a decomposition of the original prompt into different sub-prompts and then combining the results to provide the final response.
An example use case is for multi-hop QA retrieval (questions that require combining different sources of information to provide an answer).
In the original paper[7], the sub-prompts are generated based on a specific Few Shot prompt for the use case.
Example

Decomposed prompting example
Self Consistency
This approach involves increasing the model’s temperature (higher temperature equals to more randomness of the model’s answers) to generate different responses to the same question and then providing a final response by combining the results. In the case of classification problems this is done by majority voting.
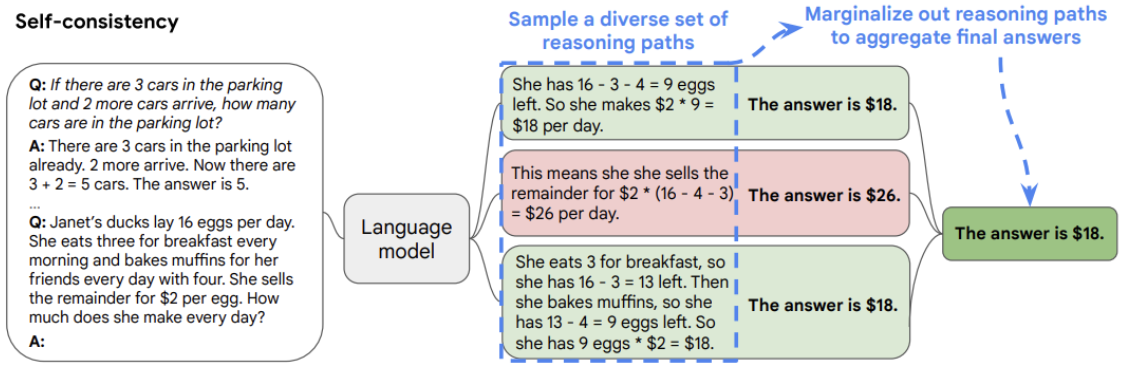
Image taken from the paper Self-Consistency Improves Chain of Thought Reasoning in Language Models[8]
The list goes on…
The recent surge in Large Language Models has led to the publication of numerous papers in the last year, focusing on different prompt engineering techniques. One of the notable approaches is called “Tree of Thoughts”. In this technique, the authors deconstruct the response process into steps, similar to Decomposed Prompting. For each step, multiple potential responses are generated, as in Self Consistency. Finally, the selection of the best responses is determined through the model’s self-evaluation, like in Self Reflection. Don’t hesitate to read more about it in the paper[9] if you are interested.
Conclusion and final thoughts
With the advent of LLMs, the field of artificial intelligence and natural language processing has witnessed a remarkable transformation. These powerful models have revolutionized text generation and language-related tasks with an extraordinary capability to create text that closely resembles human language. However, to unlock their true power, the use of prompt engineering is techniques is essential. By understanding the intricacies of prompt design and replicating elements of the human thought process, we can provide LLMs with the necessary “tokens to think”. This way we can direct their reasoning process to arrive at more accurate and contextually appropriate answers. Remember the examples list provided here is not comprehensive: think of the techniques as conceptual tools that might or might not have sense in your specific scenario. Have fun engineering!
References
- State of GPT, talk by Andrej Karpathy, founding member of OpenAI.
- An onboarding guide to LLMs, great post to better understand LLMs.
- Generated Knowledge Prompting for Commonsense Reasoning.
- Large Language Models are Zero-Shot Reasoners.
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.
- Can LLMs Critique and Iterate on Their Own Outputs?.
- Decomposed Prompting: A MODULAR APPROACH FOR SOLVING COMPLEX TASKS.
- Self-Consistency Improves Chain of Thought Reasoning in Language Models.
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models.

