Pandas & Polars: is it time to migrate? definitely maybe 🤔
By Arturo Collazo
Where are we? 🗺️
If you are a data scientist, machine learning engineer, or otherwise involved in a data-driven project, it is highly likely that you have used pandas to clean, sanitize, filter, and prepare the data to be used as input for your chosen methods, models, or algorithms.
In this early step, which usually takes a non-trivial fraction of the total project schedule, you are not running CPU-intensive instructions, but the execution is not as fast as you would like. In addition, if the dataset you are working on is large, hardware limitations – such as memory – are imminent.
These limitations are a result of 2 things, Python is generally awesome (but maybe thread concurrency management is not its peak) and Pandas has eager execution (this means that an instruction is being read and executed at the moment, we will go into this later).
This is where polars comes in! Built in Rust, it is much faster than good old Pandas. Unlike Python, Rust is great at concurrency and with the game changer that is lazy execution, a lot of optimisations can be applied before execution.
A new alternative has come! 🆕
To see what’s under the hood, we experimented with both libraries, exploring the times required for their operations on the AirBnb listings dataset for NYC 🗽. In our test scenario the improvement to working with Pandas was around a factor of 5 🤯 and it can be even higher depending on the context (data involved) size and volumes.
We recreated a regular data source pre-processing assignment of a project, loading the set into memory, applying filtering, dropping unused columns from the frame, performing some math operations, joining with other related dataset and ending up sorting the final result, comparing the libraries APIs in each case (the repo can be found and downloaded here).
In the sections below, you may see how the execution time is performed per operation.
Let’s start 💪
We’ll walk through a set of operations with this configuration and datasets specs:
- System memory: 8GB
- CPU: Mac M1 (MacBook Pro)
- Python == 3.9.13
- Pandas == 1.4.3
- Polars == 0.16.11
- listings (41533, 75)
- reviews (1088372, 6)
Read CSV
The first to do in order to get the data available is to load it into memory as a variable, this is made by
Pandas:
pd.read_csv(file_pathname, low_memory=False)
Polars (eager):
polars.read_csv(dataframe_filename)
Polars (lazy):
polars.scan_csv(dataframe_filename, ignore_errors=True)
and the times to retrieve them are:
| Source File | Polars (s) | Pandas (s) | |
| Eager | Lazy | ||
| listings | 0.20 | 2.00e-03 | 1.02 |
| reviews | 6.34e-01 | 3.18e-04 | 4.11 |
Here we can see that in both dataframes, Polars is way faster in any of its flavors.
Filter (by columns value)
Then, we move on to filter the data with some fixed values. Specifically we decided to focus on some Manhattan neighbors (‘East Village’, ‘Greenpoint’, ‘Upper East Side’, ‘Lower East Side’, ‘Upper West Side’), outstanding hosts -superhosts- and rent that are for the entire place. The code executed in each case are:
Pandas
filtered_pd = listings_dataset_pd[ (listings_dataset_pd['neighbourhood_cleansed'].isin(desirable_neighboors)) & (listings_dataset_pd['host_is_superhost'] == 't') & (listings_dataset_pd['room_type'] == 'Entire home/apt') ]
Polars (eager):
filtered_pl_eager = listings_dataset_pl_eager.filter(
(polars.col('neighbourhood_cleansed').is_in(desirable_neighboors))
&
(polars.col('host_is_superhost') == 't')
&
(polars.col('room_type') == 'Entire home/apt')
)
Polars (lazy):
filtered_pl_lazy = (
listings_dataset_pl_lazy
.filter(polars.col('neighbourhood_cleansed').is_in(desirable_neighboors))
.filter(polars.col('host_is_superhost') == 't')
.filter(polars.col('room_type') == 'Entire home/apt')
)
Note: check that the syntax is not exactly the same but similar enough to be understood easily.
The obtained times for each approach are those shown below:
| Source File | Polars (s) | Pandas (s) | |
| Eager | Lazy | ||
| listings | 7.60e-05 | 1.9e-02 | 2.8e-02 |
Once again, polars was materially better in how to filter the unwanted columns. Remember that our scope is short and we are avoiding great numbers, just comparing magnitudes.
Sort
Sorting is perhaps a feature most desired by data scientists than machine learning engineers or data engineers, regarding capturing some outliers or insight. Besides that, we sort the data with:
Pandas:
sorted_pd = filreted_pd.sort_values(by=[column_name])
Polars (eager):
sorted_pl_eager = filtered_pl_eager.sort([column_name])
Polars (lazy):
sorted_pl_lazy filtered_pl_lazy.sort([column_name])
and the retrieved times are:
| Dataset | Polars (s) | Pandas (s) | |
| Eager | Lazy | ||
| listings | 4.00e-03 | 1.79e-05 | 8.80e-04 |
Remove (drop) columns
Another manipulation that we want to try is to remove, due to the vastness of the data that is loaded into our pipeline, notebooks or event listeners. We choose some non-core columns, such as (‘source’, ‘name’, ‘description’, ‘picture_url’, ‘host_location’, ‘host_about’). This way, from now on the loaded datasets are lighter.
The codes to do that are:
Pandas
sorted_pd.drop(columns = columns_to_remove, inplace=True)
Note: use inplace when possible, is a little more efficient regarding memory.
Polars (eager)
for column in not_wanted_columns:
sorted_pl_eager.drop_in_place(column)
Polars (lazy)
sorted_pl_lazy = sorted_pl_lazy.drop(columns)
The times for each execution were:
| Datasets | Polars (s) | Pandas (s) | |
| Eager | Lazy | ||
| listings | 2.67e-04 | 2.81e-05 | 2.21e-03 |
Join
For the purpose of building a richer dataset, we looked up to join the two that are being allocated in memory, listings and reviews. From a mutual column ‘listing_id’, which needs a little pre-processing in listings, we have to extract the id from ‘listing_url’ that is accomplished with map, lambda and a little regex -check the source code for details-.
In addition, so far we have been stacking operations in the lazy track postponing its actual execution, in fact they are different data types, polars.LazyFrame is not the same as polars.DataFrame (and is not the same as pandas.DataFrame -which can be a little confusing at first-). This approach grants the best of Polars, optimizing the transformations over a dataset, that projection is a group of sorted step merged if possible to perform better, here is ours:
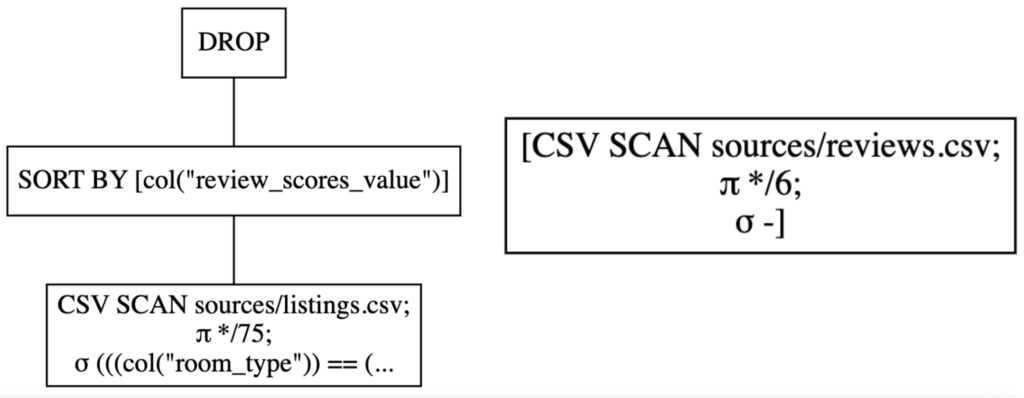
Projected transformation for each dataset when applying stacked transformations, listing at the left and reviews at the right. These graphs were generated with the show_graph() method.
Above, you may see that the advantage with the lazy approach is reached if you end up with a few blocks, where operations are combined from one to other, that is the case for listing but not for reviews.
The codes to do so are:
Pandas
sorted_pd.join(reviews, on = joining_column_name, lsuffix='_left', rsuffix='_right')
Polars
sorted_pd.join(reviews, on = joining_column_name, lsuffix='_left', rsuffix='_right')
The times for each execution are:
| Dataset |
Polars (s) |
Pandas (s) | |
| Eager | Lazy | ||
|
both |
5.50e-02 | 9.36e-01 | 3.40e-02 |
For the first time in this exploration, Pandas beat Polars. That occurs due to the pre required steps to join, for the lazy execution including collect (as it is called in the library) the data operations, all of them!
Wrapping
This step is “mandatory” if your adoption of Polars is going to be gradual (which we recommend – we will talk more about this later). Polars and Pandas data types can be converted back and forth between them, so here we will do a small conversion from Polars to Pandas, in order not to interfere with other tasks already in prod or advanced application.
Using a single line command is enough!
The code for wrap up the variable is:
migrated_dataset = joined_pl.to_pandas()
The change of data type insumes the below time:
| Dataset | Polars (s) – Eager |
| joined set | 3.88e-02 |
Overall execution times ⌚
Summarizing all involved times for all the operations (filter, sort, remove, join and wrap) we can see two clear things, the first one is about the no big difference between or gain between lazy and eager execution, but do not forget that our scope was small one and if the data transformation is quite larger this distance will grow up. The second one is the mind blowing improvement factor, we are able to get the same result x5 faster!
| Polars (s) | Pandas (s) 🥉 | |
| Lazy 🥇 | Eager 🥈 | |
| 0.93 | 0.95 | 5.19 |
Besides, if we validate it from a more granularity perspective, case to case based, we obtain:
| Operation | Library | Polars Eager | Polars Lazy | Pandas |
| Read CSV | 0.83 | 2.32e-03 | 5.13 |
| 2nd | 1st | 3rd | |
|
Filter |
7.60e-05 | 1.90e-02 | 2.80e-02 |
| 1st | 2nd | 3rd | |
| Sort | 4.00e-03 | 1.79e-05 | 8.80e-04 |
| 3rd | 1st | 2nd | |
| Remove col | 2.67e-04 | 2.81e-05 | 2.21e-03 |
| 2nd | 1st | 3rd | |
|
Join |
5.50e-02 | 9.36e-01 | 3.40e-02 |
| 1st | 3rd | 2nd | |
| Wrap | 3.88e-02 | – | – |
| Disclaimer: this operation is out of the comparison due to being executed by one of the alternatives. | |||
Assigning points based on the ranking of each if the above tasks (3 for the 1st, 2 to the 2nd and 1 to the 3rd), we obtain 11 points for Polars Eager, 12 for Polars Lazy and 7 for Pandas, which also reflects the benefits in terms of time execution of working with any of the Polars flavors instead of Pandas.
How should we proceed? 🤔
As we could see on this exploration, Polars seems like a great alternative to save (a lot of) time on project tasks due to its implementation and available optimizations. But, is it safe to move all current projects, pipelines, notebooks or assets that use pandas to Polars? It does not seem like a clever idea to do that so suddenly. However, with an iterative approach, working with polars in new projects (maybe the small ones at first) using the wrapper method will allow the team to gain traction over the library and be satisfied with its impact, seems like a worthwhile investment.
In case you are interested in a more exhaustive comparison, you can check this github site where a lot (all of them great) tools are compared.
A little bonus
Do not hesitate on explore other blogs where we have been working on about data and ai in general.

