Deploying Llama2 with NVIDIA Triton Inference Server
By Sofía Pérez
Intro
NVIDIA Triton Inference Server is an open-source inference serving software that enables model deployment standardization in a fast and scalable manner, on both CPU and GPU.
It provides developers the freedom to choose the right framework for their projects without impacting production deployment. It also helps developers deliver high-performance inference across cloud, on-premise, and edge devices.
In this tutorial, we’ll focus on efficiently packaging and deploying Large Language Models (LLM), such as Llama2 🦙, using NVIDIA Triton Inference Server 🧜♂️, making them production-ready in no time.
Deploying Llama2 using Hugging Face
To deploy a Hugging Face model, e.g. Llama2, on NVIDIA Triton there are two possible approaches:
- Using Triton’s Python Backend
- Using Triton’s Ensemble models
Python Backend
For making use of Triton’s python backend, the first step is to define the model using the TritonPythonModel class with the following functions:
initialize()– This function is executed when Triton loads the model. It is generally used for loading any model or data needed. The use of this function is optional.execute()– This function is executed upon every request. It usually contains the complete pipeline logic.
Here is a complete example of Llama2 model implementation in Triton ecosystem:
import app
import os
import json
import triton_python_backend_utils as pb_utils
import numpy as np
import torch
from transformers import pipeline, AutoTokenizer, AutoModelForCausalLM,TextIteratorStreamer
import huggingface_hub
from threading import Thread
huggingface_hub.login(token="") ## Add your HF credentials
class TritonPythonModel:
def initialize(self, args):
self.tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-13b-chat-hf")
self.model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-13b-chat-hf",
load_in_8bit= True,
torch_dtype=torch.float16,
device_map='auto')
self.model.resize_token_embeddings(len(self.tokenizer))
def get_prompt(self, message: str,
chat_history: list[tuple[str, str]],
system_prompt: str) -> str:
texts = [f'<s>[INST] <<SYS>>\n{system_prompt}\n<</SYS>>\n\n']
# The first user input is _not_ stripped
do_strip = False
for user_input, response in chat_history:
user_input = user_input.strip() if do_strip else user_input
do_strip = True
texts.append(f'{user_input} [/INST] {response.strip()} </s><s>[INST] ')
message = message.strip() if do_strip else message
texts.append(f'{message} [/INST]')
return ''.join(texts)
def execute(self, requests):
responses = []
for request in requests:
# Decode the Byte Tensor into Text
inputs = pb_utils.get_input_tensor_by_name(request, "prompt")
inputs = inputs.as_numpy()
# Call the Model pipeline
DEFAULT_SYSTEM_PROMPT = """You are a helpful AI assistant. Keep short answers of no more than 2 sentences."""
prompts = [self.get_prompt(i[0].decode(), [], DEFAULT_SYSTEM_PROMPT) for i in inputs]
self.tokenizer.pad_token = "[PAD]"
self.tokenizer.padding_side = "left"
inputs = self.tokenizer(prompts, return_tensors='pt', padding=True).to('cuda')
output_sequences = self.model.generate(
**inputs,
do_sample=True,
max_length=3584,
temperature=0.01,
top_p=1,
top_k=20,
repetition_penalty=1.1
)
output = self.tokenizer.batch_decode(output_sequences, skip_special_tokens=True)
# Encode the text to byte tensor to send back
inference_response = pb_utils.InferenceResponse(
output_tensors=[
pb_utils.Tensor(
"generated_text",
np.array([[o.encode() for o in output]]),
)
]
)
responses.append(inference_response)
return responses
def finalize(self, args):
self.generator = None
The second step is to create a configuration file for the model. The purpose of this file is for Triton to understand how to process the model. It usually includes specifications for the inputs and outputs of the models, the runtime environment and the necessary hardware resources.
Below is the configuration file for our Llama2 example:
name: "llamav2"
backend: "python"
input [
{
name: "prompt"
data_type: TYPE_STRING
dims: [1]
}
]
output [
{
name: "generated_text"
data_type: TYPE_STRING
dims: [1]
}
]
instance_group [
{
kind: KIND_GPU
}
]
Finally, the files should adhere to the following structure:
model_repository/ |-- 1 | |-- model.py |-- config.pbtxt
Ensemble models
An ensemble model represents a pipeline of one or more Machine Learning models whose inputs and outputs are interconnected. This concept can also be applied for the pre and post-processing logic, by treating them as independent blocks/models which are then assembled together on Triton.
This approach requires first converting the model into a serialized representation, such as ONNx, before deploying it on the Triton server. Once converted, there are two ways of deploy the model onto Triton server:
- Client-side tokenizer: Only the model is deployed onto the Triton server, while the tokenization is handled entirely on the client side.
- Server-side tokenizer: Both the tokenizer and the model are deployed on the server.
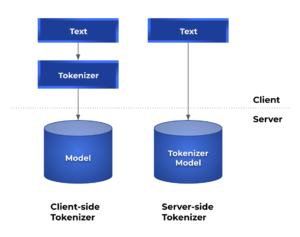
The model repository should contain three different folders with the following structure:
model_repository/ |-- ensemble_model | |-- 1 | |-- config.pbtxt |-- model | |-- 1 | |-- llamav2.onnx | |-- config.pbtxt |-- tokenizer | |-- 1 | | |-- config.json | | |-- model.py | | |-- special_tokens_map.json | | |-- tokenizer.json | |-- config.pbtxt
Let’s go over the contents and purpose of each of these folders:
- ensemble_model: This folder should contain a sub-folder named
1(denoting the model’s version), along with aconfig.pbtxtfile. The file outlines the logic of how an inference request is passed through the different elements of the ensemble pipeline (in this case the tokenizer and the model).name: "ensemble_model" max_batch_size: 0 platform: "ensemble" input [ { name: "prompt" data_type: TYPE_STRING dims: [ -1 ] } ] output [ { name: "output_0" data_type: TYPE_FP32 dims: [-1, 2] } ] ensemble_scheduling { step [ { model_name: "tokenizer" model_version: -1 input_map { key: "prompt" value: "prompt" } output_map [ { key: "input_ids" value: "input_ids" }, { key: "attention_mask" value: "attention_mask" } ] }, { model_name: "model" model_version: -1 input_map [ { key: "input_ids" value: "input_ids" }, { key: "attention_mask" value: "attention_mask" } ] output_map { key: "output_0" value: "output_0" } } ] }
- model: This folder should also contain a sub-folder named
1which contains the serialized representation of the model, and theconfig.pbtxtfile which contains the models configuration details.name: "model" platform: "onnxruntime_onnx" backend: "onnxruntime" default_model_filename: "llamav2.onnx" max_batch_size: 0 input [ { name: "input_ids" data_type: TYPE_INT64 dims: [ -1, -1 ] }, { name: "attention_mask" data_type: TYPE_INT64 dims: [ -1, -1 ] } ] output [ { name: "output_0" data_type: TYPE_FP32 dims: [ -1, 2 ] } ] instance_group [ { count: 1 kind: KIND_GPU } ]
- tokenizer: This folder contains a sub-folder named
1which contains the*.jsonand*.txtfiles generated by HuggingFace and amodel.pywhich contains the logic for invoking the tokenization of the text.import os from typing import Dict, List import numpy as np import triton_python_backend_utils as pb_utils from transformers import AutoTokenizer, PreTrainedTokenizer, TensorType class TritonPythonModel: tokenizer: PreTrainedTokenizer def initialize(self, args: Dict[str, str]) -> None: """ Initialize the tokenization process :param args: arguments from Triton config file """ # more variables in https://github.com/triton-inference-server/python_backend/blob/main/src/python.cc path: str = os.path.join(args["model_repository"], args["model_version"]) self.tokenizer = AutoTokenizer.from_pretrained(path) def execute(self, requests) -> "List[List[pb_utils.Tensor]]": """ Parse and tokenize each request :param requests: 1 or more requests received by Triton server. :return: text as input tensors """ responses = [] # for loop for batch requests (disabled in our case) for request in requests: # binary data typed back to string query = [ t.decode("UTF-8") for t in pb_utils.get_input_tensor_by_name(request, "TEXT") .as_numpy() .tolist() ] tokens: Dict[str, np.ndarray] = self.tokenizer( text=query, return_tensors=TensorType.NUMPY ) # tensorrt uses int32 as input type, ort uses int64 tokens = {k: v.astype(np.int64) for k, v in tokens.items()} # communicate the tokenization results to Triton server outputs = list() for input_name in self.tokenizer.model_input_names: tensor_input = pb_utils.Tensor(input_name, tokens[input_name]) outputs.append(tensor_input) inference_response = pb_utils.InferenceResponse(output_tensors=outputs) responses.append(inference_response) return responsesIt also should include the
config.pbtxtspecifying the tokenizers configuration details.name: "tokenizer" max_batch_size: 0 backend: "python" input [ { name: "prompt" data_type: TYPE_STRING dims: [ -1 ] } ] output [ { name: "input_ids" data_type: TYPE_INT64 dims: [-1, -1] }, { name: "attention_mask" data_type: TYPE_INT64 dims: [-1, -1] } ] instance_group [ { count: 1 kind: KIND_GPU } ]
Running inferences
Once the model is deployed, we can proceed to setting up Triton Server. This can be accomplished quite easily by using the pre-built Docker image available from the NVIDIA GPU Cloud (NGC).
Server setup
Below are the steps to get your Triton server up and running.
- Run docker container for Triton Server using the following command:
docker run --gpus=all -it --shm-size=1g --rm -p8000:8000 -p8001:8001 -p8002:8002 -v ${PWD}:/workspace/ -v ${PWD}/model_repository:/models nvcr.io/nvidia/tritonserver:23.08-py3 basTriton exposes three ports by default, which are specified in the docker run command:
- 8000: HTTP REST API requests
- 8001: gRPC requests
- 8002: Metrics and monitoring via Prometheus
- Once inside the container, install the necessary dependencies to run your model:
pip install app pip install torch pip install transformers pip install huggingface_hub pip install accelerate pip install bitsandbytes pip install scipy
- With the dependencies in place, execute the following command to run Triton Server:
docker run --gpus all -it --rm -v ${PWD}:/work -w /work nvcr.io/nvidia/tritonserver:23.08-py3 ./gen_vllm_env.sh
Client setup
As for the client setup, clients can interact with Triton Server using either HTTP/REST protocol or GRPC protocol. The endpoint depends on the protocol and API version we are using.
- For HTTP we will need to use the
localhost:8000endpoint, include the model name in the URL and the input data in the request body. Here is an example using curl:
curl --location --request POST 'http://localhost:8000/v2/models/llamav2/infer' \ --header 'Content-Type: application/json' \ --data-raw '{ "inputs":[ { "name": "prompt", "shape": [1], "datatype": "BYTES", "data": ["Hello"] } ] }' - For gRPC we will need to use the localhost:8001 endpoint.
Setting up Triton Client can also be done by setting up a pre-built Docker image, as shown below:
- Run docker container for Triton Client
docker run -it --net=host -v ${PWD}:/workspace/ nvcr.io/nvidia/tritonserver:23.08-py3-sdk bash - Then run your inference script. Here is an example Python script using HTTP requests:
from tritonclient.utils import * import tritonclient.http as httpclient import time import numpy as np tm1 = time.perf_counter() with httpclient.InferenceServerClient(url="localhost:8000", verbose=False, concurrency=32) as client: # Define input config input_text =[["Where is Uruguay?"], ["Who is George Washington?"], ["Who is Lionel Messi?"], ] text_obj = np.array(input_text, dtype="object")#.reshape(2,1) inputs = [ httpclient.InferInput("prompt", text_obj.shape, np_to_triton_dtype(text_obj.dtype)).set_data_from_numpy(text_obj), ] # Define output config outputs = [ httpclient.InferRequestedOutput("generated_text"), ] # Hit triton server n_requests = 1 responses = [] for i in range(n_requests): responses.append(client.async_infer('llamav2', model_version='1', inputs=inputs, outputs=outputs)) for r in responses: result = r.get_result() content = result.as_numpy('generated_text') print(content) tm2 = time.perf_counter() print(f'Total time elapsed: {tm2-tm1:0.2f} seconds')
Concurrent model execution
With Triton, you can run multiple models or several instances of the same model using the same GPU resources. To enable this, just add the following line in the model’s configuration file, right under the instance_group section:
instance_group [
{
count: 2
kind: KIND_GPU
}
]
You can change the count of allowed inferences for the same model instance and observe how it affects performance.
If you have access to multiple GPUs, you can also change the instance_group settings to place multiple execution instances on different GPUs. For example, the following configuration will place two execution instances on GPU 0 and three execution instances on GPUs 1 and 2.
instance_group [
{
count: 2
kind: KIND_GPU
gpus: [ 0 ]
},
{
count: 3
kind: KIND_GPU
gpus: [ 1, 2 ]
}
]
Dynamic Batching
Triton provides dynamic batching feature, which allows combining multiple requests on the same model execution, substantially increasing inference throughput.
The diagram below depicts how this feature works.
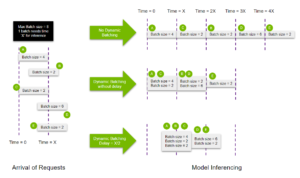
Enabling dynamic batching groups consecutive sequences together within the maximum batch size limit, leading to more efficient packing of requests into the GPU. Also, you can allocate a limited delay for the scheduler, allowing it to collect more inference requests for the dynamic batcher to use.
Here is a configuration example of dynamic batching for our Llama2 model:
name: "llamav2"
backend: "python"
max_batch_size: 8
input [
{
name: "prompt"
data_type: TYPE_STRING
dims: [-1]
}
]
output [
{
name: "generated_text"
data_type: TYPE_STRING
dims: [-1]
}
]
instance_group [
{
kind: KIND_GPU
}
]
dynamic_batching {
preferred_batch_size: [2, 4, 8]
max_queue_delay_microseconds: 300
}
- The
max_batch_sizeproperty sets the maximum batch size allowed by the model - The
[-1]in the input and output dimensions indicates that those dimensions are in fact dynamic and could change from one request to another. - The dynamic_batching section enables dynamic batching for the model. It also allows to configure further properties, such as:
- The preferred_batch_size property which indicates the batch sizes that the dynamic batcher should attempt to create.
- The
max_queue_delay_microsecondsproperty determines the maximum delay time allowed in the scheduler for other requests to join the dynamic batch.
Ragged Batching
Requests can be dynamically batched together when all inputs share the same shape. In situations where input shapes frequently differ, padding must be applied to ensure the shapes match and to be able to use dynamic batching.
Ragged batching is a feature that allows us to avoid this padding, by specifying which of the inputs doesn’t require the shape check in the model configuration file:
input [
{
name: "prompt"
data_type: TYPE_STRING
dims: [ -1 ]
allow_ragged_batch: true
}
]
Deploying Llama2 using vLLM
vLLM is an open-source LLM inference and serving library. It utilizes PagedAttention, a new attention algorithm that effectively manages attention keys and values, making it achieve exceptionally high throughput without requiring any model architecture changes. It also supports continuous batching of incoming requests allowing higher GPU utilization.
What is continuous batching about?
The idea was first presented in the paper Orca: A Distributed Serving System for Transformer-Based Generative Models. Instead of waiting for all sequences in a batch to finish generation, it employs iteration-level scheduling, where the batch size is determined for each iteration. As a result, once a sequence in a batch is completed, a new sequence can be inserted in its place, enabling greater GPU usage.
The image intends to further illustrate the difference between static and continuous batching. Each cell corresponds to a token. Yellow cells depict prompt tokens, blue cells depict generated tokens, and red cells represent end-of-sequence tokens.
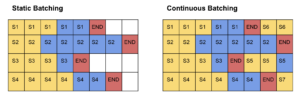
In static batching, the generation process concludes when the last sequence (i.e., sequence S2) finishes, resulting in underutilization of the GPU’s capacity.
On the other hand, continuous batching operates differently. As soon as a sequence emits an end-of-sequence token, we can seamlessly insert a new sequence in its place, ensuring optimal GPU utilization. This can be seen in the insertion of sequences S5, S6, and S7.
Downsides of vLLM:
- Does not allows multiple GPU usage
- Does not allows quantization
Running inferences with vLLM
The procedure is similar to the one we have seen before.
- Build a new docker container image derived from
tritonserver:23.08-py3docker build -t tritonserver_vllm .
- Prepare model repository and files:
- Files should follow the following structure:
model_repository/ |-- vllm |-- 1 | |-- model.py |-- config.pbtxt |-- vllm_engine_args.json - The
vllm_engine_args.jsonfile should contain the following:
{ "model": "meta-llama/Llama-2-7b-chat-hf", "disable_log_requests": "true" } - Here is an example of the configuration file, note that Triton dynamic batching is disabled (
max_batch_size = 0) to let vLLM handle the batching on its own.
name: "vllm" backend: "python" max_batch_size: 0 model_transaction_policy { decoupled: True } input [ { name: "PROMPT" data_type: TYPE_STRING dims: [ -1 ] } ] output [ { name: "generated_text" data_type: TYPE_STRING dims: [ -1 ] } ] instance_group [ { count: 1 kind: KIND_MODEL } ] - The
model.pyfile intends to define the model using the TritonPythonModel class as in the Python Backend approach. Here you can find an example on how to set up a model using vLLM.
- Files should follow the following structure:
- Start the Triton server:
docker run --gpus all -it --rm -p 8001:8001 --shm-size=1G --ulimit memlock=-1 --ulimit stack=67108864 -v ${PWD}:/work -w /work tritonserver_vllm tritonserver --model-store ./model_repository - Start the Triton client and run your inference script.
docker run --gpus all -it --rm -v ${PWD}:/work -w /work nvcr.io/nvidia/tritonserver:23.08-py3 ./gen_vllm_env.sh
Here is a Python script example using the gRPC client library.
Results
We have performed and measured Triton’s inference capabilities for both HuggingFace and vLLM model implementations. In particular we made special focus on testing Triton’s concurrent model execution and dynamic batching features. To accomplish this, we used Meta’s model Llama chat 7B and deployed it on an EC2 g5.xlarge instance, equipped with a 24GB GPU.
Concurrent execution performance
| 1 instance | 2 instances | |
|---|---|---|
| Execution time | 9.79s | 6.72s |
| Throughput | 10.6 token/s | 15.5 token/s |
(*) In order to fit the model’s instances on the available GPU, we had to do 8 bit quantization
Dynamic batching performance
| Batch size = 1 | Batch size = 8 | |||
|---|---|---|---|---|
| HF | vLLM | HF | vLLM | |
| Execution time | 9.79s | 2.06s | 17.07s | 3.12s |
| Throughput | 10.6 token/s | 50 token/s | 66.5 token/s | 363 token/s |
Final remarks
Throughout this tutorial, we have reviewed various techniques for deploying machine learning models under the Triton ecosystem, which allowed us to accelerate inference time up to x7 without losing accuracy.
The following are some of the key results obtained during our tests:
- By exploiting Triton’s concurrent model execution feature, we have gained a x1.5 increase in throughput by deploying two parallel instances of the Llama2 7B model quantized to 8 bit.
- Implementing dynamic batching added an additional x5 increase in model’s throughput.
- Finally, the incorporation of the vLLM framework outperformed the dynamic batching results with a x7 increase. As a downside, vLLM does not allow for model quantization, therefore we weren’t able to test simultaneous instances of Llama2 7B under this framework due to computational requirements.
For a deeper dive into these examples, take a look at our repo! 🔗

