By Sofía Pérez
Intro
NeMo Guardrails is an open-source toolkit developed by NVIDIA for seamlessly incorporating customizable guardrails to LLM-based conversational systems. It allows users to control the output of an Large Language Model (LLM), for instance avoiding political topics, following a predefined conversation flow, validating output content, etc.
Inspired by SelfCheckGPT, NeMo heavily relies on the utilization of another LLM for output validation. Some of its key features include:
- Programmable Guardrails: Define the behavior of your LLM, guiding conversation and preventing discussions on unwanted topics
- Seamless Integration: Easily connect your LLM to other services and tools (e.g., LangChain), enhancing its capabilities
- Customization with Colang: A specialized modeling language, Colang, that allows you to define and control the behavior of your LLM-based conversational system.
In this post, we’ll navigate through effectively using NeMo Guardrails with your LLM, particularly focusing on integration with Llama2 🦙 through practical examples.
What are LLM Guardrails?
Guardrails are a set of programmable safety guidelines that monitor and control a user’s interaction with an LLM application, such as a chatbot. They sit between the users and the LLM models, as a sort of “protective shield” which ensures the outputs follow certain defined principles. By implementing guardrails, users can define structure, type, and quality of LLM responses.
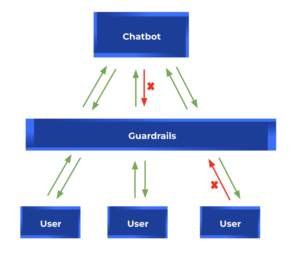
How does NeMo Guardrails work?
NeMo Guardrails’s architecture has an event-driven design, where specific events kickstart a step-by-step process.
This process is broken down into three main stages:
- Creating canonical user messages
- Deciding on next step(s) and taking action
- Generating bot responses
Each of the above stages can involve one or more calls to the LLM. For handling these interactions, the toolkit relies on LangChain.
Colang
NeMo simplifies setting up guardrails for LLMs with the introduction of a unique modeling language called Colang.
Colang is a modeling language specifically designed for describing conversational AI flows. Its goal is to provide a readable and extensible interface for users to define or control the behavior of conversational bots with natural language.
Colang has a “pythonic” syntax in the sense that most constructs resemble their python equivalent and indentation is used as a syntactic element. The core syntax elements are: blocks, statements, expressions, keywords and variables.
There are three main types of blocks:
- User message blocks: Consist of sets of standard user message (canonical form) linked to certain topics.
define user express greeting "hello" "hi" define user request help "I need help with something." "I need your help."
- Bot message blocks: Intended to define the content of bot messages canonical forms.
define bot express greeting "Hello there!" "Hi!" define bot ask welfare "How are you feeling today?"
define bot express greeting "Hello there, $name!"
- Flow blocks: They are intended to guide the conversation in the right direction. It includes sequences of user messages, bot messages and potentially other events.
define flow hello user express greeting bot express greeting bot ask welfare
NeMo Guardrails Workflow
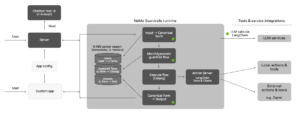
Given a user’s input, the first stage consists of doing a vector search over the user canonical forms available in the configuration. The system then uses the most similar matches (top 5 by default) to create a prompt and directs the LLM to generate the canonical user message. Upon generating the canonical form, the system creates a new UserIntent event.
By default, NeMo Guardrails uses the Sentence Transformers all-MiniLM-L6-v2 embedding model, and Annoy for performing the search.
The next steps can be determined in two possible ways:
- Either there is a predefined flow that can decide what happens next
- Or the LLM is used to make that decision
In the second approach, the system performs a new vector search to retrieve the most relevant flows from the guardrails configuration. It then includes the top 5 flows obtained in a prompt and uses this to instruct the LLM to predict the next step.
The next step chosen can imply one of the following:
- A
BotIntentevent: the bot has to give an answer - A
StartInternalSystemActionevent: the bot has to execute certain action
After an action is executed or a bot message is generated, the runtime will try again to generate another next step. The process will stop when there are no more next steps.
When the system generates the BotIntent event, it invokes the generate_bot_message action. Once again, it performs a vector search to find the most relevant canonical bot messages examples to include in a prompt and instructs the LLM to generate the utterance (i.e text) for the current bot intent. In the end, it triggers a bot_said event and returns the final response to the user.
Using open-source LLMs with NeMo Guardrails
By default, NeMo Guardrails is designed for use with OpenAI models, such as text-davinci-003. However, the framework also supports loading HuggingFace models.
It essentially uses Langchain’s HuggingFacePipeline class to achieve this. Here is a configuration example:
- Load the HuggingFace model and create a pipeline
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf") model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf") pipe = pipeline( "text-generation", model=model, tokenizer=tokenizer, max_length=4096, do_sample=True, temperature=0.2, top_p=0.95, logprobs=None, top_k=40, repetition_penalty=1.1 ) - Wrap the pipeline using Langchain
HuggingFacePipelineclass
from langchain.llms import HuggingFacePipeline llm = HuggingFacePipeline(pipeline=pipe)
- Wrap the
HuggingFacePipelineusing Nemo’sget_llm_instance_wrapperfunction and register it usingregister_llm_provider.
from nemoguardrails.llm.helpers import get_llm_instance_wrapper from nemoguardrails.llm.providers import register_llm_provider HFPipeline = get_llm_instance_wrapper( llm_instance=llm, llm_type="hf_pipeline_llama2" ) register_llm_provider("hf_pipeline_llama2", HFPipeline)
⚠️ Most existing RAIL examples are crafted using prompts that work well with ChatGPT, but not as well with other models.
Using a custom knowledge base with NeMo Guardrails
To use a custom knowledge base, you need to create a kb folder inside the configuration folder and store your document there.
├── config │ └── kb │ ├── file_1.md │ ├── file_2.md │ └── ...
⚠️ Currently, the framework only supports Markdown format.
Use cases
We will now center around two common use cases:
- Topic guidance and safety measures
- Guardrails to prevent hallucinations
Topic guidance and safety measures
The idea behind this use case is to guide the model to stick to certain topics and avoid answering certain questions. In other words, the Guardrail layer examines every user input and filters them accordingly.
To achieve this, the first step involves gathering utterances (text) that represent both typical and off-topic questions. The Guardrail will use those definitions to determine which flow to follow given a new question.
Here is a configuration example where we prevent the model from answering sports-related questions:
# define niceties
define user express greeting
"hello"
"hi"
"what's up?"
define flow greeting
user express greeting
bot express greeting
bot ask how are you
# define limits
define user ask sports
"what is your favorite football team?"
"who is Rafael Nadal?"
"football player"
"tennis player"
"match result"
define bot answer sports
"I'm a shopping assistant, I don't like to talk of sports."
define flow sports
user ask sports
bot answer sports
bot offer help
When asked about a match result or a football player, the chatbot effectively evades the question as designed:
res = await rails.generate_async(prompt="Do you know who is Lionel Messi?") print(res)
[Out]: I'm a shopping assistant, I don't like to talk of sports. Is there anything else I can help you with?
Using Guardrails to prevent hallucinations
NeMo Guardrails present two different methods for handling hallucinations:
- Fact checking
- Hallucinations
The first method consists of asking the LLM to re-check whether the output is consistent with the context. In other words, ask the LLM if the response is true based on the documents retrieved from the knowledge base.
The second method targets situations where no knowledge base is available. It involves requesting the LLM model (with temperature = 1) to re-generate the answer. The system then passes the new answers as context to the LLM, and the model evaluates whether it’s a hallucination based on the number of different answers generated.
⚠️Prompts are engineered for OpenAI and do not work transparently with other LLM such as Llama2. You can change them by modifying the general.yml file located in the nemoguardrails/llm/prompts/ folder.
For the first method, Llama2 worked fine by adding some few shot examples in the prompt as shown below:
- task: fact_checking
models:
- hf_pipeline_llama2
content: |-
You are given a task to identify if the hypothesis is grounded and entailed to the evidence.
You will only use the contents of the evidence and not rely on external knowledge.
Your answer MUST be only "YES" or "NO".
Here are some examples:
"evidence": The Eiffel Tower is an iron lattice tower located on the Champ de Mars in Paris, France. It was named after the engineer Gustave Eiffel, whose company designed and built the tower.
"hypothesis": The Eiffel Tower is located in Rome, Italy.
"entails": NO
"evidence": Albert Einstein was a theoretical physicist who received the Nobel Prize in Physics in 1921 for his discovery of the law of the photoelectric effect.
"hypothesis": Albert Einstein was awarded the Nobel Prize in Physics in 1921.
"entails": YES
"evidence": Adult humans typically have 206 bones, while newborns have around 270. Over time, some bones fuse together.
"hypothesis": The capital of Japan is Tokyo.
"entails": NO
"evidence": Neil Armstrong was an astronaut on NASA's Apollo 11 mission and became the first person to walk on the moon on July 20, 1969.
"hypothesis": Water boils at 100 degrees Celsius at sea level.
"entails": NO
"evidence": {{ evidence }}
"hypothesis": {{ response }}
"entails":
⚠️For the second method, we need to recreate the hallucination.py as by default it only accepts OpenAI models.
Check line 57 of nemoguardrails/actions/hallucination/hallucination.py
if type(llm) != OpenAI:
log.warning(
f"Hallucination rail can only be used with OpenAI LLM engines."
f"Current LLM engine is {type(llm).__name__}."
)
return False
You can check out this implementation in our repo 🔗.
Closing remarks
Wrapping up, NeMo Guardrails empowers users to seamlessly implement safeguards for Large Language Models (LLMs) within conversational applications. In this blog, we have explored practical insights on using NeMo Guardrails with Llama2 🦙, highlighting two key use cases: topic guidance and preventing hallucinations.
We hope this post provides you with the necessary tools to make the most of NeMo Guardrails in your conversational AI applications. Stay tuned for more! 💪

