Deep Learning techniques for Automatic Text Summarization
By Sofía Pérez
Intro
We live in a world where data availability grows exponentially every day. Never before have we had so many text documents to process. While data is a very powerful currency, having too much data available directly affects our capacity to consume it. As an old saying goes, “too much information kills information”. This issue is commonly known as data overloading.
Manually dealing with such a gigantic amount of information is an extremely overwhelming task, which implies having a huge amount of time and resources destined to it. Also, as new information sources keep piling up on a daily basis, keeping track of meaningful topics and key points seems almost impossible. Wouldn’t it be great to be able to extract all relevant information without having to read a never-ending list of documents? This is where Automatic Text Summarization (ATS) comes in handy 😉
Automatic summaries not only significantly reduce processing and reading time, but also help to efficiently discover relevant information and consume it faster. What’s more, when compared to human performance, automatic summary systems tend to be less biased. The aim of this post is to present a walkthrough of some state-of-the-art abstractive summarization techniques and understand their main challenges.
What is ATS?
As mentioned before, Automatic Text Summarization (ATS) provides an effective way to solve data overloading. It is an NLP process that aims to reduce the amount of text of a given input while preserving its most essential information and contextual meaning. It focus on generating concise and readable summaries containing core information of an input text. Generally ATS is divided into two families of techniques: extractive and abstractive summarization.
Extractive summarization consists of selecting near exact sentences from the input text to create the final summary. It can be seen as a binary classifier whose goal is deciding whether or not to extract the sentence into the summary. These approaches are always consistent with the source document and do not modify the original text. Thus, these methods usually lack the ability to generate fluent and concise summaries.
Abstractive summarization on the other hand, aims to generate a completely paraphrased and concise summary from the input text, capturing its main idea, while being short and easy to read. By taking into account all the information given, abstractive summarizers generate new phrases to capture the document’s essence. We will focus on these models throughout the remainder of this post.
Abstractive Summarization is one of the most challenging tasks in NLP, as it involves understanding long segments, data compression and text generation. It can be formulated as a sequence-to-sequence task where the source text (input) is mapped to the target summary (output). Most recent approaches are based on Transformers, consisting of an encoder-decoder architecture.
How can we evaluate the performance of our models?
Evaluating summary quality is not a straightforward task. In the need of finding suitable automatic metrics to numerically qualify the faithfulness of a generated summary two types of metrics come into play: syntactic metrics based on n-grams such as ROUGE, and semantic metrics based on contextual embeddings such as BERTScore.
ROUGE
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) is a standard set of evaluation metrics oftenly used for summarization tasks. It aims to evaluate the similarity between the model-generated summaries and the annotated summaries. ROUGE scores are branched into ROUGE-N, ROUGE-L and ROUGE-S scores.
- ROUGE-N: measures the number of matching N-grams between reference and candidate summaries.
- ROUGE-L: measures the Longest Common Subsequence (LCS) words between reference and candidate summaries. By LCS, we refer to word tokens that are in sequence, but not necessarily consecutive.
- ROUGE-S: Also referred to as skip-gram concurrence metric, it’s by far the less popular ROUGE score. It allows searching for consecutive words from the reference text that appear in the model output but are separated by one-or-more other words.
Although ROUGE is a great evaluation metric, it comes with some drawbacks. In-particular, it does not take into account different words that have the same meaning — as it measures syntactical matches rather than semantics. It also fails to evaluate fluency, and so it performs badly in comparison to human evaluation. Let’s see this in more detail through some examples.
Suppose we have the following written phrase: “The quick black cat climbed into the old oak.”
And we want to evaluate it against similar generated sentences using ROUGE metrics.
Generated sentence 1: “The cat climbed into the oak.”
| ROUGE-1 | ROUGE-2 | ROUGE-L | Semantics |
| 80.0 | 46.2 | 80.0 | Accurate |
In this first scenario, ROUGE gives a good indication as the generated result is semantically accurate and achieves a high score.
Generated sentence 2: “The fast dark feline ascended the ancient tree.”
| ROUGE-1 | ROUGE-2 | ROUGE-L | Semantics |
| 23.5 | 0.0 | 23.5 | Accurate |
In this second example, the machine-generated summary is factually correct but the ROUGE score is actually very low and thus it wrongly qualifies it as a mediocre summary.
Generated sentence 3: “The quick black oak climbed into the old cat.”
| ROUGE-1 | ROUGE-2 | ROUGE-L | Semantics |
| 100.0 | 62.5 | 77.8 | Inaccurate |
In our last scenario we can see how ROUGE might wrongly give a high score to a generated summary that clearly is factually incorrect.
BERT Score
BERT Score is an automatic metric for text generation. Unlike existing popular methods (such as ROUGE) that compute token level syntactic similarity, BERTScore focuses on computing semantic similarity between tokens of candidate and reference sentences by incorporating contextual embeddings. The main idea underlying this approach is to first understand the meaning of the generated text and its corresponding reference, and then perform the comparison.
The method consists of passing both reference and candidate texts through a pre-trained BERT model, in order to generate contextual embeddings for each word. This is followed by a pairwise cosine-similarity calculation of each of the words from reference to each of the words in the candidate.
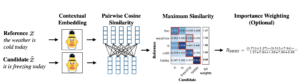
BERT Score computation diagram extracted from the original paper [1]
The idea of these metrics works fine on paper, but in reality it may be misleading as most times they fail to reflect the actual quality of the generated output. Human evaluation is still necessary in order to assess the model’s model’s true performance.
Short sequence summarizers
When it comes to short documents, state-of-the-art abstractive summarizers are usually based on a classical Transformer type architecture, combining encoder-decoder blocks with a self attention mechanism for text generation.
Transformer’s self-attention mechanism compares all the elements of an input sequence with each other, measures their similarity to obtain weights and combines these weights to give an output. Thus, the algorithm scales quadratically with respect to input size. If you want to get more familiarized with how Transformers work you can refer to our previous post for more detail.
Most common examples of abstractive summarizers include BART, PEGASUS and T5, among others. Architecturally these models are very much alike, what usually changes is the objectives used in pre-training. For instance, PEGASUS uses Gap Sentence Generation while BART uses text infilling and sentence permutation transformations.
We’ve chosen to use T5 to illustrate the performance of these types of models.
Example summary with T5
Suppose we want to summarize the following news regarding Jeff Bezos new property acquisition in Manhattan. To summarize this 300 word long piece, we’ve used a large version of T5 model pre-trained on XSum dataset and achieve the following result:
|
So far so good, by running the T5 model we were able to successfully capture the article’s main idea in just a few lines.
Now, think about the variety of text that we deal with on a daily basis, such as reports, surveys, articles, books, and so on. Most of them consist of longer documents that often have much more internal data variance and topic swings.Now, what happens if we have longer input texts? Can we still use the T5 model to summarize these long input texts? Well, actually due to quadratic self attention mechanisms, these types of models are limited to short sequences, usually up to 512 tokens.
A simplistic approach to address this shortcoming could be to split the input text in smaller text chunks. Is this effective? Chunking algorithms control how much of the larger document we pass into a summarizer based on the max tokens the model allows. Smaller chunks allow for more understanding per chunk but increase the risk of split contextual information.
Example with chunking
Suppose we now want to summarize this piece, which has around 1200 words. To be able to process it, we’ve split the text into three chunks. The T5 model was run on each chunk and its outputs were then concatenated, reaching to the following result:
|
We could also try to re-apply our model to the result in order to see if we can improve narrative and make the text more fluent.
| France have urged their players to enjoy the final match of the 2018 World Cup as they prepare for Sunday’s final against Argentina in Doha, Qatar on Sunday night (July 2022). Read more about Didier Deschamps. |
Clearly this approach has not generated accurate results. Some contextual relationships are lost during the splitting. Also, it involves higher inference time as the model needs to be run several times.
Is there a better way to overcome the input length constraint? Fortunately YES 😎
Long sequence summarizers
In order to be able to process longer sequences, models such as LED or Long T5 have modified traditional transformer architecture with a self-attention operation that scales linearly with the sequence length. Both models use similar strategies; they are able to combine local attention with global attention by using applying the following techniques:
LED was introduced in the paper Longformer: The Long-Document Transformer. It introduces an attention mechanism that combines local windowed attention with task-motivated global attention.
The mechanism consists of three main parts:
- Sliding Window: It employs a fixed-size window attention surrounding each token. Given a fixed window size w, each token attends to 1/2w tokens on each side.
- Dilated Sliding Window: The sliding window can be “dilated”, which means the kernel is expanded by inserting gaps (of size dilatation d) between its consecutive elements. This technique enables a larger receptive field without increasing computation.
- Global Attention: To gain flexibility, “global attention” is added on a few pre-selected locations. This mechanism is symmetric, that is, a token with a global attention attends to all tokens across the sequence, and all tokens in the sequence attend to it.
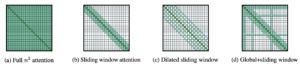
LED attention mechanisms [6]
LED’s Longformer can handle sequences 32 times larger than what was previously possible with traditional transformer self-attention.
Long T5 extends the original T5 encoder to handle longer inputs of up to ∼16k tokens. Specifically, the model integrates attention mechanisms from long-input transformers (ETC), and pretraining strategies from summarization pretraining (PEGASUS) into the T5 architecture.
Two attention mechanism variations were presented for Long T5:
- Local Attention: Replaces the encoder self-attention operation in T5 with a sparse sliding-window local attention. Given a local radius r, the algorithm attends r tokens to the left and right of each token. The paper suggests using r=127.
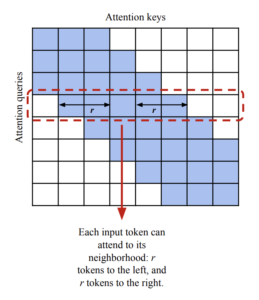
Long T5 local attention mechanism [7]
- Transient Global Attention (TGlobal): Is a modification of ETC’s global-local attention in a “fixed blocks” pattern. It divides the input sequence into blocks of k tokens, and for each block computes a global token by summing (and then normalizing) the embeddings of every token in the block.
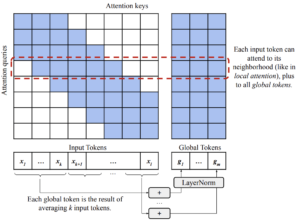
Long T5 Tglobal attention mechanism [7]
The following table compares LED and LongT5 in terms of input sizes and number of trainable parameters.
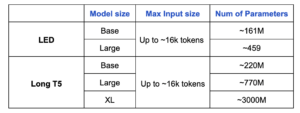
Let’s see these models in action shall we?
Base models
Example Long T5 base – pre trained on BookSum
|
Example LED base – pre trained on BookSum
|
Large models
Example Long T5 large – pre trained on PubMed
|
Example LED large – pre trained on BookSum
|
From the examples presented above we’ve derived the following observations:
- In larger models, the quality of the resulting summaries is widely improved.
- LED Large results showed better narrative, while Long T5 Large seems to be more extractive. This could partly be attributed to the fact that the latter one was pre-trained on medical articles (PubMed) dataset and not books.
- LED Large arrived at some misleading details. For instance, the phrase “The opening goal is the fastest ever scored by a substitute” is not accurate:
- It was in fact the second goal the one that was scored by a substitute
- And this goal was in fact the goal was the third-quickest goal for a substitute
What about GPT-3?
When it comes to Large Language Models (LLMs), Generative Pre-trained Transformer 3 (GPT-3) is one of the first things that pops into our minds. It is one of the largest transformer models available leveraging deep learning to generate human-like text. GPT-3 has ~175B of parameters and has been trained with about 45 TB text data from multiple sources covering a vast variety of application fields. It can handle very long input sequences (up to 4096 tokens) and naturally manages large amounts of data variance.
In order to further evaluate Long T5 and LED performances, we’ve run the same example in the GPT-3 Playground and use this as our baseline.
|
From the result presented above, GPT-3 (text-da-vinci-003) clearly outperforms both Long T5 and LED approaches. But this is not really a fair comparison at all. Learning happens based on parameters. As the number of parameters increases, the model gains more granular knowledge and is able to improve its predictions. GPT-3 has in fact a thousand times more parameters than the LongT5 and LED versions we’ve tested. So it sounds about right that it manages to achieve by far a better performance.
Final thoughts
Certainly there is still a long way to go in terms of automatic text summarization when it comes to long documents. Here are some key takeaways:
- While GPT-3 dominates this field, the fact that it is not open source encourages people to find other solutions.
- LED and LongT5 have shown to be able to produce decent results considering they do have way less parameters than GPT-3.
- Model size matters. As we’ve observed, the performance of our models notoriously increases when we switch from base to large versions. Larger models achieve better narrative and are able to reflect entity relationships more accurately. However, larger models demand higher computational resources, which translates into higher costs.
- Model performance is very sensitive to pre-training. As observed when comparing PubMed and BookSum versions, narrative style and model’s general performance are strongly affected by the data used during the pre-training phase.
- Most times, automatic scores do not truly reflect the quality of the summary. Manual inference is recommended in order to assess model performance.
I hope you’ve enjoyed this post. Keep tuned for more!
References
- [1] BERTScore: Evaluating Text Generation with BERT
- [2] Google Research reimplementation of ROUGE
- [3] BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
- [4] PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
- [5] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- [6] Longformer: The Long-Document Transformer
- [7] LongT5: Efficient Text-To-Text Transformer for Long Sequences

