NLP Transformer DIET explained
By Diego Sellanes
Transformers are a type of neural network architecture that has revolutionized the industry in the past years. Its popularity has been rising because of the models’ ability to outperform state-of-the-art models in neural machine translation and other several tasks. At Marvik, we have used these models in several NLP projects and would like to share a bit of our experience. In particular, in this article we are going to review and discuss RASA’s latest transformer architecture and the advantages this innovative architecture presents.
What is DIET?
DIET is a multi-task transformer developed by RASA, which works for entity recognition and intent classification. It’s highly adaptable to different scenarios and configurations. Thanks to its modularized architecture, it’s greatly tunable which makes it very useful in multiple applications. It even provides an interactive demo for its architecture modules.
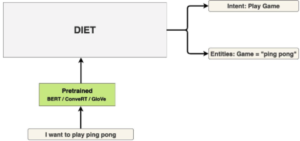
How does it work?
In this section we are going to describe the architecture, and how training and inference are executed. So as to explain how it performs both tasks (intent classification and entity recognition) at the same time.
Architecture
In the next diagram there is a high level architecture diagram which shows the different pieces of the model, and how they are connected.
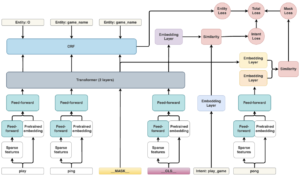
DIET architecture image from RASA’s blog
Modules
DIET’s architecture is based on modules, which have a multi-layer transformer as a key component of the architecture. The different modules will be described in this section.
Input preprocessing
The modules described below are in charge of preprocessing the input data so as to generate the features necessary for the transformer module.
Pretrained Embedding
The objective of this module is to provide an input to the transformer related to the token in a certain embedding. This is a ‘plug-and-play’ pretrained module, as there are many alternatives, among them are: BERT, ConVe, ConveRT, nearly any word embedding would work without writing any code. If a more lightweight version of the model is needed, this module can even be removed.
Sparse Features
This module generates sparse features for the tokens in training; it’s essentially a FFN, with sparse connections. The idea is that in addition to the embedding generated by the pretrained embedding module, more features are added as training data goes through the model, so as to give more information about the token to the transformer.
Feed Forward
This module consists of a fully connected neural network (NN) which may have different inputs depending on which part of the architecture it’s connected to, but its output is always a 256 size array.
There are 2 different Feed Forward Networks in the architecture, the input of the first one is the sparse features of some token, and the input of the second one is the pretrained embedding, concatenated to the output of the first FFN.
The use case is the same in both cases, to learn features about tokens which will be later used as inputs of the Transformer module.
Note that the inputs of the sparse features are sparse arrays, so to make the model lightweight a dropout of 80% of the connections is implemented by default (this is customizable and often recommended to increase to 90% if a lighter model is needed).
Mask & CLS tokens
These are not modules, but are key components of the architecture, because it’s how the model learns to do both tasks at the same time.
The mask token is applied randomly at a word of the sentence. This is then feeded to the transformer, which allows it to predict which token was masked, then allow learning through gradient descent.
The CLS token is a representation of the whole sentence, similar to an embedding of the whole sentence, and provides the ability to learn the intent of the sentence to the transformer.
Intent recognition
This task is done by essentially two components: the embedding layer and its loss, which are used during training.
Embedding Layer
The module is used in training, so as to generate the Mask loss, associated with the mask generated by the model. This basically generates a loss measurement between the token “predicted” or “filled in” by the transformers output, and the ground truth generated by the FFN which uses inputs from the pretrained embedding and the sparse feature modules from the token.
Intent loss
This module calculates the loss of the output of the transformer and the intent classification of the sentence (given by the similarity module). Then goes as an input to the total loss module, which will provide a measure of learning.
Entity recognition
This task identifies the entities in the initial sentence, both modules are used during training.
Conditional Random Field (CRF)
This module is used during training to calculate a loss for the entities recognized by the NLU pipeline and the output of the transformer; this loss measures the ability of the transformer to recognize entities related to the input sentence.
Entity loss
The entity loss module is provided the output of the CRF module described above, which will calculate the measure of how good the transformer is identifying entities in the sentence.
Similarity & Total loss Modules
There are 4 loss modules present in the architecture, the entity loss module, the mask loss module, the intent loss module and the total loss module.
The purpose of these modules is the same: compute the formula for each particular loss with its inputs and output the value of the loss. These modules are essential for training and provide one of the most important features of the DIET Model: the ability to infer intent and entity recognition at the same time.
The similarity module is just a particular case of a loss module, which is used for comparison of two different inputs, in one case, related to the mask, by comparing the output of the transformer with the output of the FFN of the masked token. Also, when comparing the CLS token for the whole sentence with the intent of the sentence. It’s output provides a measure of how similar its inputs are, essential for computing the losses previously described.
Transformer
This module is the key part of the architecture, it receives the processed features of the tokens (from the FFN and the pretrained embedding) and then outputs the value for each token, if it is an entity or not, and which is the word masked.
This module by default consists of 2 layers, but can be customized. This module is affected by all three losses during training.
Training
A general loss function is used to train the shared FFN, Pretrained embeddings, CRF, Transformer and Embeddings. This is done by combining three types of different losses into one metric: the mask loss, the entity loss and the intent loss into the general loss.
The idea is that these different losses will trigger modifications of weights through gradient descent in different steps or iterations, when some part of the pipeline makes a mistake, in order to correct and improve its performance.
For example, if the transformer failed to recognize some entity, this will be reflected in the ‘entity loss’ generated from the output from the CRF module, which will then lead to an adjustment of the weights of the transformer and the layers before (FFN, Pretrained embeddings).
As another example, if the transformer fails to predict correctly the masked word, this will be reflected in the ‘Mask loss’ calculated from the similarity module. As a result of the embedding layers, similarly to the previous example, gradient descent will take care of this, by adjusting the weights of the modules involved.
Finally, after training the module, additional data could be used for fine tuning the model consisting of different examples for each intent, which will be then processed. This will provide the model with some domain of the language and a more precise idea of the classification needed for the predictions.
nlu:
- intent: greet
examples: |
- hey
- hello
- hi
- hello there
- good morning
- good evening
- moin
- hey there
- let's go
- hey dude
- goodmorning
- goodevening
- good afternoon
- intent: goodbye
examples: |
- cu
- good by
- cee you later
- good night
- bye
- goodbye
- have a nice day
- see you around
- bye bye
- see you later
- intent: affirm
examples: |
- yes
- y
- indeed
- of course
- that sounds good
- correct
- intent: deny
examples: |
- no
- n
- never
- I don't think so
- don't like that
- no way
- not really
- intent: mood_great
examples: |
- perfect
- great
- amazing
- feeling like a king
- wonderful
- I am feeling very good
- I am great
- I am amazing
- I am going to save the world
- super stoked
- extremely good
- so so perfect
- so good
- so perfect
- intent: mood_unhappy
examples: |
- my day was horrible
- I am sad
- I don't feel very well
- I am disappointed
- super sad
- I'm so sad
- sad
- very sad
- unhappy
- not good
- not very good
- extremly sad
- so saad
- so sad
- intent: bot_challenge
examples: |
- are you a bot?
- are you a human?
- am I talking to a bot?
- am I talking to a human?
Example of fine tuning data for training model.
Inference
After the fine tuning step, we require an inference model. The only input needed is a sentence, which will be then provided to the model described above. The output will be the intent of the sentence (a class among the ones listed during fine tuning) and the entities recognized in the sentences.
Inference is 6x faster than BERT trained on the same tasks. This is because of the modular architecture, which allows for a lightweight model. Time of execution may vary with different configurations.
{"text":"That is amazing!","intent":{"name":"mood_great","confidence":0.9996907711029053},"entities":[],"text_tokens":[[0,4],[5,7],[8,15]],"intent_ranking":[{"name":"mood_great","confidence":0.9996907711029053},{"name":"deny","confidence":0.0001600375398993492},{"name":"bot_challenge","confidence":5.5457232519984245e-5},{"name":"affirm","confidence":3.597023169277236e-5},{"name":"greet","confidence":2.746816971921362e-5},{"name":"goodbye","confidence":2.5115507014561445e-5},{"name":"mood_unhappy","confidence":5.233784577285405e-6}],"response_selector":{"all_retrieval_intents":[],"default":{"response":{"responses":null,"confidence":0.0,"intent_response_key":null,"utter_action":"utter_None"},"ranking":[]}}}
Example of response from the model.
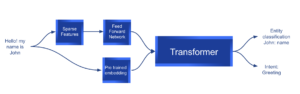
This diagram shows an example of the model at inference time.
Advantages compared to similar models
DIET presents various improvements and advantages with respect to similar models performing the same tasks:
- Its ability to adapt to different scenarios:
- hardware is restrictive (i.e running on a raspberry pi)
- inference time is crucial (real-time application)
- Faster than competition (x6 faster than BERT)
- Computation of entity recognition and intent at the same time
- It also provide some models which are fine tuned, ready to use for certain domains
When low resources are restricting the model that can be used, DIET provides different alternatives to deal with scenarios such as eliminating the pretrained embedding module, reducing the amount of layers in the transformer and increasing the dropout parameter in the FF networks. These help reduce the amount of memory used and decrease the inference time.
DIET in practice
At Marvik we experimented with this model to recognize and classify certain sentences with loosely defined labels (real world stuff, and not lab simulations 🙂 ). We had the chance to test this as a second step in an article processing pipeline and in chatbot applications, as part of an automatic retraining loop. Results were promising, even when compared to other transformer architectures, and we recommend its use when simpler classifiers are not up to the task.
Final Thoughts
RASA’s DIET transformer has a very powerful architecture. It proposes a new way of understanding state-of-the-art transformers, with a clever loss function which sums up every aspect of the model. It’s highly customizability and adaptability to different scenarios makes us believe that it is a very promising alternative in many cases and applications.
If you would like to know more about DIET and how to apply it in your own application, do not hesitate to contact us!

