By Valentina Alonso
It’s no surprise that AI models are getting bigger, with an increase in training data and the number of parameters. For example, while OpenAI’s GPT-3.5 was trained with 175 billion parameters and over 570 GB of data from various sources, GPT-4 was likely trained on close to 1 trillion parameters and terabytes of data.
As great as this may sound, having such huge models may be challenging for real-world applications, where deployment is extremely difficult due to the intensive computational requirements and costs (especially on edge devices). It may also be an overkill… Sometimes, the performance isn’t worth the cost and latency.
This is where Model Distillation comes in handy. In this blog, we’ll explore what Model Distillation is, how it’s done, and how it’s used in different scenarios.
What is Model Distillation?
Also known as knowledge distillation, it’s a technique where a larger capacity teacher model with better quality, is used to train a more compact student model with better inference efficiency.1
Mainly, it involves transferring knowledge from a large, complex model to a smaller, more efficient one. This allows achieving similar levels of accuracy and performance, while being computationally less demanding, making it appropriate for deployment on devices with limited resources.
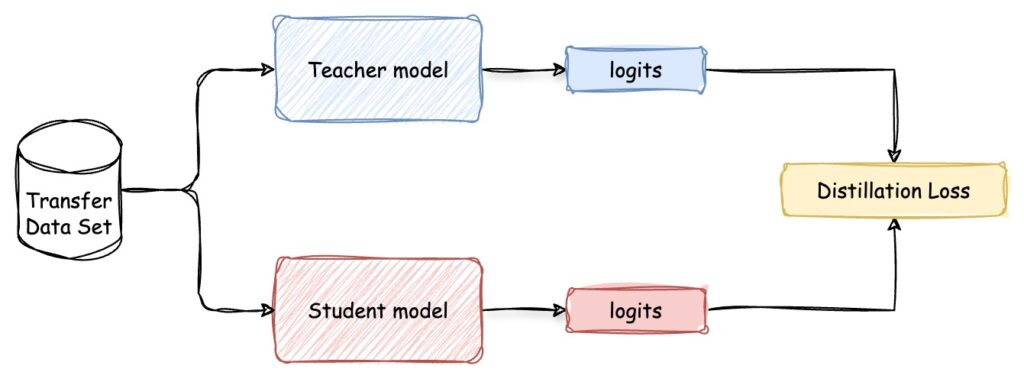
The Teacher-Student paradigm
So what’s with the teacher-student relationship? As you may have guessed, we’ll call the pre-trained model the teacher, like an LLM, from which the knowledge will be distilled. The student model will be the one that will learn the qualities and behaviours of the teacher model. Through distillation, one expects to benefit from the student’s compactness, without sacrificing too much on model quality.2
Figure 1 shows a general teacher-student framework for model distillation. It illustrates how the teacher model, which is a complex and pre-trained neural network, transfers its learned knowledge to a more compact student model through this process we call distillation. This involves utilizing a shared dataset to distill the essential knowledge from the teacher model, which is then transferred to the student model.

Ok… but how?
You get the concept. Now: how do we actually transfer knowledge? Even though many distillation methods have been proposed, there is no commonly agreed theory as to how knowledge is transferred, thus making this blog post slightly harder.
Let’s analyze some of them.
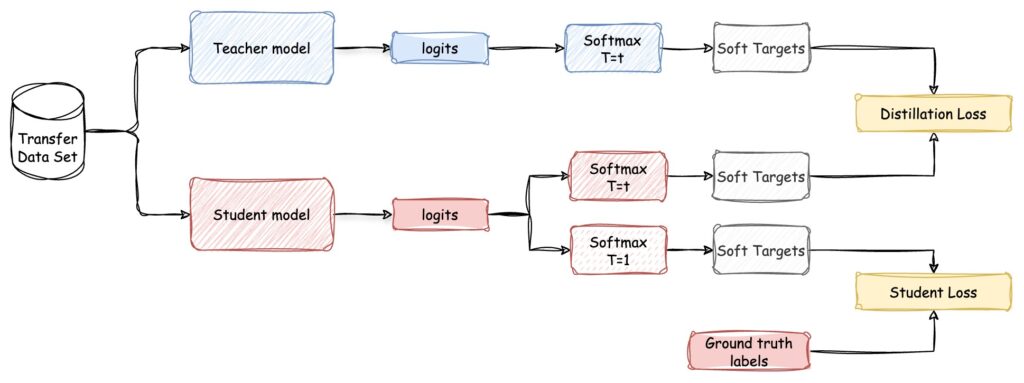
Response-based Model Distillation
This is the most common and easiest-to-implement type of model distillation that relies on the teacher-model’s outputs. Instead of making primary predictions, the student model is trained to mimic the prediction of the teacher model. It involves a two-step process, portrayed in Figure 2:
- First, training the teacher model. Or as we mentioned, you could also use a pre-trained model to distill it to a smaller one.
- Second, prompt it to generate “soft targets”. A distillation algorithm is then applied to train the student model to predict the same soft labels as the teacher model, and minimize the differences in their outputs (also known as Distillation Loss, but we’ll come back to it later). This involves learning from the outputs of the teacher model rather than directly from the training data. By doing so, the student model can achieve similar levels of accuracy while being more efficient in terms of computational power and memory usage.
Here comes a crucial aspect of model distillation: the use of soft targets. Unlike traditional training methods that use hard targets (one-hot encoded class labels), model distillation employs soft targets, which are probability distributions over all possible classes.
Imagine you are training a model to classify images of animals into four categories: cow, dog, cat, and bird. In traditional training with hard targets, the labels for each image are one-hot encoded. For an image of a dog, the label would be ([0, 1, 0, 0]).
However, when training with soft targets, the teacher model provides a probability distribution over all classes. For an image of a dog, the soft targets might be ([10-6, 0.9, 0.1, 10-9]), reflecting the teacher model’s confidence in each class.
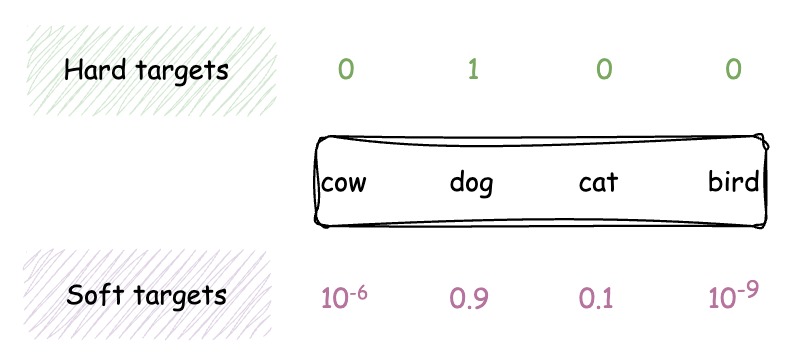
These soft targets provide more subtle information about the relationships between different classes, allowing the student model to learn more effectively.
Each probability can be estimated by a softmax function that depends on a temperature factor T to control the softness of each target. The temperature is applied to the logits of the teacher model before converting them to probabilities. A higher temperature produces a softer probability distribution, while a lower temperature makes it sharper.
The student model is then trained to minimize the difference between its predictions and those of the teacher model. This is, minimizing the Loss Function, which typically combines two components:
- The already mentioned Distillation Loss: defined as the difference between the soft targets produced by the teacher model and the predictions of the student model, both calculated using the same temperature factor. It’s often calculated using the Kullback-Leibler divergence or cross-entropy.
In the previous example, the Distillation Loss between ‘dog’ and ‘cat’ would be smaller than the loss between ‘dog’ and ‘bird’, as the teacher model assigns a higher probability to ‘cat’ (0.1) compared to ‘bird’ (10-9). - Student Loss: defined as the standard cross-entropy loss between the ground truth label and the soft logits of the student model.
Let’s complete the diagram above to have the full picture:
Sounds good, doesn’t it?
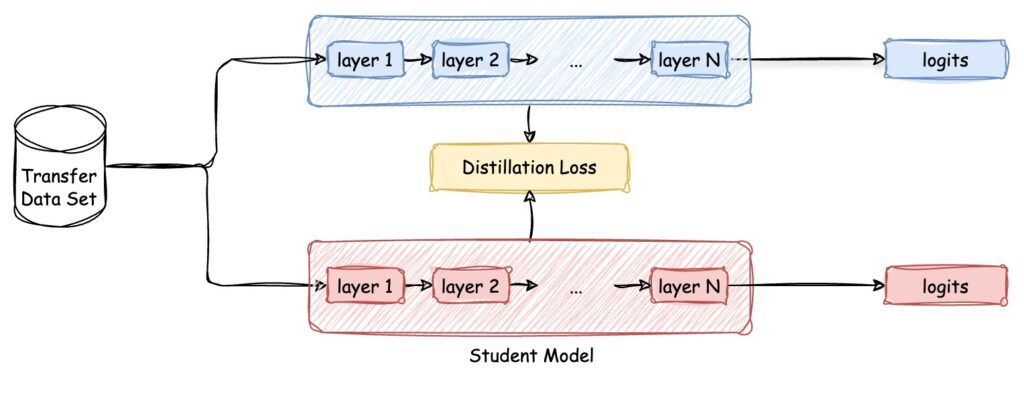
Feature-based Model Distillation
Response-based is useful when you need a straightforward and quick method for distillation. It only relies on the output of the last layer. But when the task requires capturing complex patterns and relationships, such as object detection or segmentation, Feature-based model distillation is your go-to.
In Feature-based model distillation, both the output of the last layer and the output of intermediate layers can be used as hints to improve the training of the student model, directly matching the feature activations of the teacher and the student. We say hints but actually we mean that the output of a teacher’s hidden layer supervises the student’s learning.
This method is designed to transfer knowledge even when the teacher and student model have different architectures, depths, or layer counts. The core idea is to align the internal representations (features) learned by the teacher with those of the student, as long as certain strategies address the architectural differences.
In summary, the transfer data set is used to extract feature representations from both the teacher and the student model. The Distillation Loss will now be computed based on the difference between these feature representations to train the student model.
Our new diagram will look like:
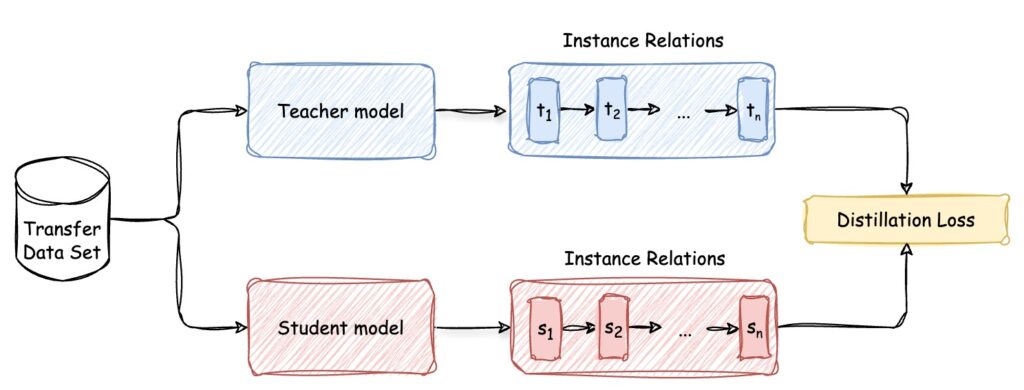
Relation-based Model Distillation
Last but not least, Relation-based model distillation focuses on exploring the relationships between different layers, both in the teacher and the student model. It’s useful in tasks where understanding the relationships between data points is crucial, such as recommendation systems or graph-based models.
The Instance Relations are calculated using the inner products between features from two layers. These capture the pairwise similarities or interactions between data points, providing a richer representation of the underlying structure of the data. This way the student model can better mimic the teacher model’s performance.
Finally, the Distillation Loss will be computed based on the difference between these relational representations to train the student model.
Applications of Model Distillation
So there’s the theoretical basis of model distillation. To illustrate its practical impact, let’s highlight some existing applications.
NLP
As we previously mentioned, the application of model distillation for NLP applications is especially important given the broad adoption of large capacity models like LLMs. This means we could create a lightweight LLM, that retains much of the accuracy and capability of the original LLM, but that is more suitable for deployment in resource-constrained environments.
⚠️ Allow me to add a disclaimer here:
We could create a general-purpose smaller model that fully encapsulates all the knowledge of an LLM, but there is typically a trade-off between the size of the distilled model and its performance. LLMs achieve their performance due to their capacity to capture a huge amount of linguistic knowledge, representations, and patterns from extensive training data. Compressing all this knowledge into a significantly smaller model often leads to a poorer performance.
Therefore, it seems fitter to use model distillation for task-specific models, where the goal is to optimize the student model for a specific task or a set of tasks. By focusing on particular outputs or behaviors of the teacher model relevant to the task, the student can achieve performance close to or even surpassing the teacher on that task.
Edge computing
Model distillation plays a vital role in enabling AI models to run on edge devices such as smartphones, IoT devices, and embedded systems. By reducing model size and computational requirements, it becomes feasible to deploy sophisticated AI capabilities directly on these devices, improving privacy, reducing latency, and enabling offline functionality. If you’re curious and want to learn more, check out this awesome blog.
For instance, most of the model distillation methods were developed for image classification, and then extended to other visual recognition applications such as:
- face recognition,
- image/video segmentation,
- object detection,
- lane detection,
- pose estimation,
- visual question answering, and
- anomaly detection.
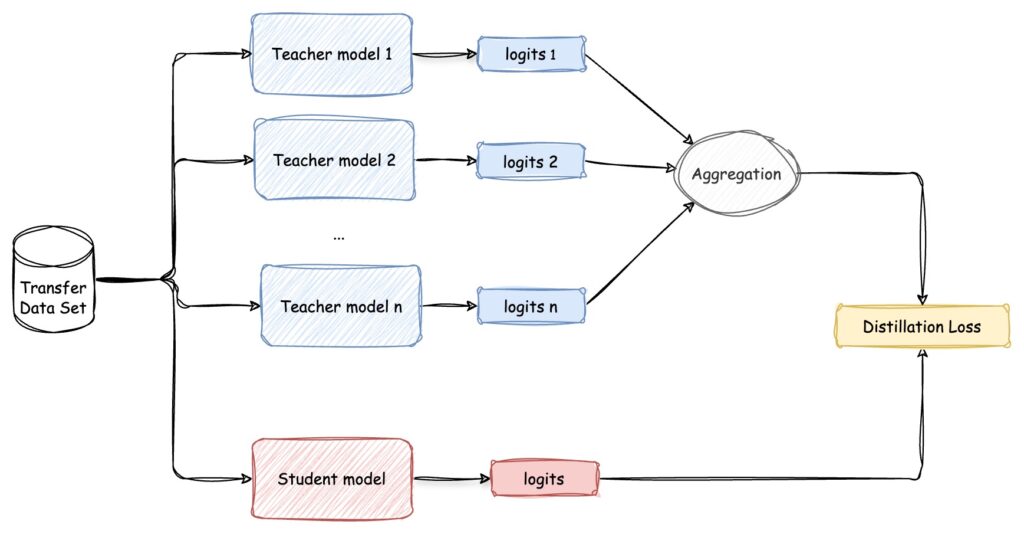
Ensemble Compression
Finally, model distillation can be used to compress an ensemble of models into a single, more efficient model that approximates the ensemble’s performance. This technique, sometimes called “ensemble distillation” allows for the deployment of ensemble-level performance with the computational cost of a single model.
What’s next?
If you read up to this point you’ve hopefully learned what Model Distillation is, how it’s done, and maybe even imagined different scenarios where it could be beneficial.
All in all, model distillation not only opens up the possibility of deploying LLMs in a cost-effective way, but it also addresses a critical challenge in resource-constrained environments. By creating task-specific, smaller models, deployment on edge devices is feasible. This approach minimizes computational demands while maintaining performance, making it ideal for a wide range of scenarios.
If you’re interested in getting hands-on experience with model distillation, there are several tools and platforms available to help you get started:
- OpenAI’s API provides a flexible interface to experiment with various distillation techniques,
- Azure and AWS also offer comprehensive machine learning services that can facilitate the implementation of model distillation in real-world applications.

