Difference between Gemma and Gemini
By Arturo Collazo
Introduction
Google -particularly its DeepMind squad- has launched a set of lightweights models, called Gemma, the same that were involved in Gemini creation. It is available in two sizes, 2B and 7B. It comes with an outstanding Responsible Generative AI Toolkit, an SFT for several frameworks and ready-to-use libs and colabs.
Pre-trained models or customized ones are capable of running locally -yes, locally- or over GPU where Google’s team has improved performance for NVIDIA and Google Cloud TPU. Besides, its terms of use allow commercial use.
So, if you were wandering about your convenience or the fit between your use case and Gemma -in any of its flavors-, the answer is yes! Keep reading to know what is under the hood.
Build strategies and constraints
Gemma has been built following Responsible Generative AI Toolkit, which adds a safety layer regarding behavior to LLM applications. To accomplish this, not only personal information but sensitive information was also removed from training sets and both fine-tuning and Reinforcement Learning from Human Feedback (RLHF) was used to get instruction-tuned models responsible responses.
For the evaluation, several approaches were implemented. From manual red-teaming to automated adversarial testing and assessments of model capabilities for dangerous activities.
Gemma and Gemini
What is the difference between Gemma and Gemini? What are they each focused on? Mainly in its target audience, purpose and size. While Gemma is open source and lightweight, Gemini is proprietary and heavyweight. Also, Gemma is intended to be used by developers and researchers but Gemini for advanced AI research and large-scale apps. The next table shows a more detailed comparative:
| Gemma | Gemini |
| Open-source | Proprietary |
| JAX, PyTorch and TF -over keras 3.0- compatibility | Restricted to Google ecosystem |
Applications and architectures
Both Gemma and Gemini can be used for:
- Text generation: answer questions, generate text or summarize it
- Image processing: image captioning task, visual question and answering tasks
The two of them can be an entity in your solution, even if you are building with a microservice architecture or a monolithic one. The key differences rely on your responsibilities and capacity of customization.
Let’s consider that you are working based on microservices, where each one has a proper goal to serve.
Gemma use case
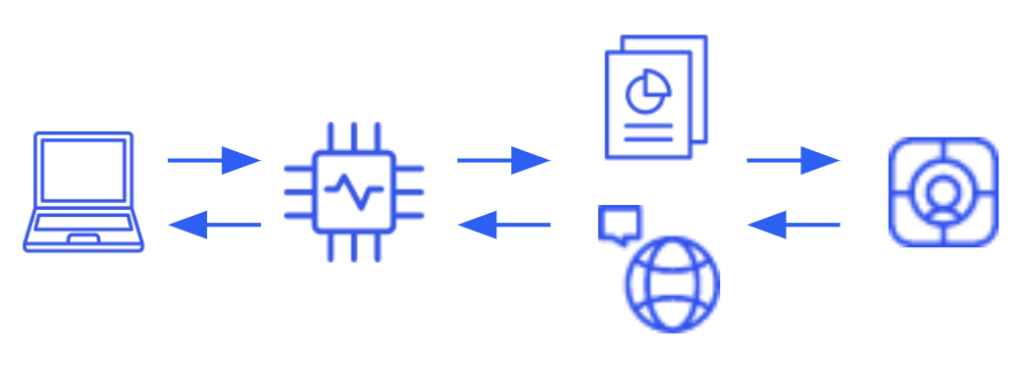
A typical architecture with Gemma requires at least a microservice, dedicated to host the model to interact with the incoming prompts. Besides, if you intend to improve your responses based on specific knowledge -RAG approach- a vector DB will be also required.
On one hand, this has the advantage of a practically infinite level of customization, from improving the model itself with specific data, to enhance its performance over adding context into the prompt – including the referred docs -.
On the other hand, there is always a catch, or at least something to consider and here is no exception. In this case, you are not only in charge of the development of the solution but also the infra required to run it where probably resources with GPU are required, which impacts in the billing as well.
Gemini use case
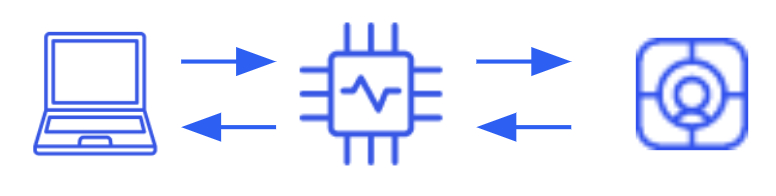
A typical architecture with Gemini is not as demanding as the previous one about the infra and roles required, because you could access the model as an external service -SaaS-. Centralizing the integration in one service or module will be enough.
This has the advantage of behold least duties in terms of amount of work hours, infra setup and access control, which is beneficial if a fast time to market is crucial, it is enough to access Gemini with proper credentials.
Nevertheless, you are resigning your capacity for customization. Even though you are able to work on your prompt, at the end they are a limited piece of text, so working with RAG to add domain specific documents to the model or retrain it for your requirements it is not an available alternative.
Gemma Model sets
Gemma
Gemma is an LLM, with great results in text generation tasks, including question answering, summarization, and reasoning.
PaliGemma
PaliGemma is a lightweight open vision-language model (VLM), so it takes both images and text as inputs and can answer questions about images with detail and context. Therefore, the model is capable of performing analysis of images providing captioning for images and short videos, object detection, and reading text embedded within images.
There are two flavors of PaliGemma, a general purpose one -PaliGemma- and a research-oriented one -PaliGemma-FT-. The first one is a great option as a starting point for fine-tuned models to a variety of tasks, the second one is already tuned on specific research datasets.
Some features of PaliGemma include multimodal comprehension, simultaneously understanding both images and text, and the possibility to be fine-tuned on a wide range of vision-language tasks.
CodeGemma
CodeGemma is a collection of models that can perform a variety of coding tasks like fill-in-the-middle code completion, code generation, natural language understanding, mathematical reasoning, and instruction following.
In this case, there are 3 configurations at disposal. A 7B pretrained variant that specializes in code completion and generation from code prefixes and/or suffixes, then a 7B instruction-tuned version for natural language-to-code chat and instruction following, and finally a 2B pretrained one that provides faster code completion.
Within the advantages of CodeGemma there are capabilities such as code completion and generation on multi-language proficiency – the stack includes Python, JS, Kava, Kotlin, C++, C#, Rust, Go among others.
RecurrentGemma
RecurrentGemma is an open model based on Griffin, as plain Gemma is well-suited for text generation tasks, including question answering, summarization, and reasoning but with some extra benefits, in particular reduced memory usage, higher throughput and high performance.
Specs and arch overview
Gemma take off from Gemini program, including code, data, architecture, instruction tuning, reinforcement learning from human feedback, and evaluations. There are a few aspects that are worth mention, such as: Multi-Query Attention instead of the original multi-head attention is used, RoPE Embeddings in each layer, GeGLU activation instead of ReLU and Normalizer Location – normalize input and output of each transformer sub-layer using RMSNorm.
Comparative
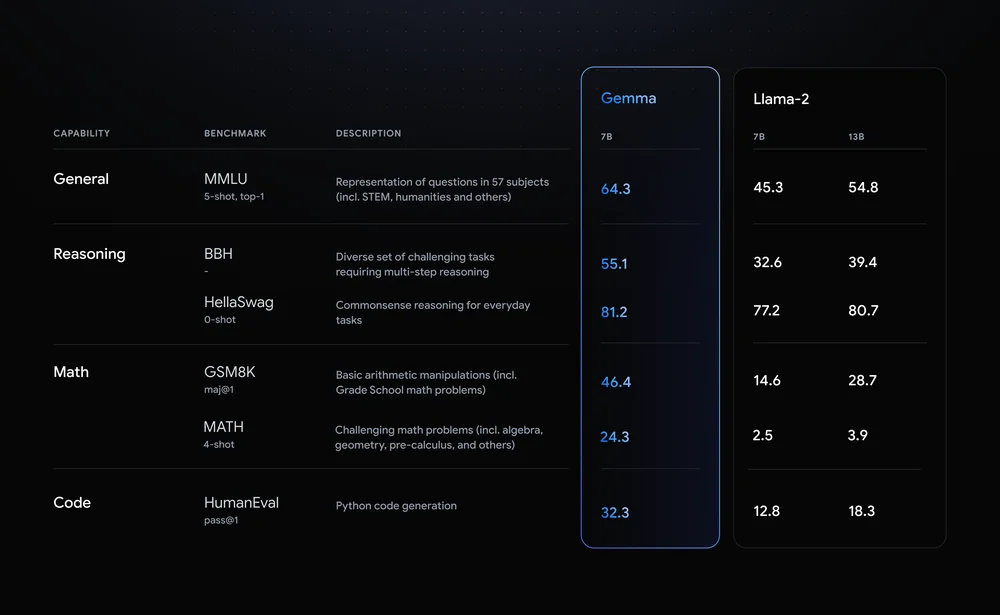
So far, so good. But if in your projects, initiatives or whatever you are working on you are already using other open source models like Llama, you may wonder why make the effort to pivot. Here is the reason: Google compared Gemma 7B with Meta’s Llama 2 7B across various domains like reasoning, mathematics, and code generation.
Take a look at the table below, where Gemma outperformed Llama-2 all across the board.
Integration & Adoption
As already mentioned, integration between Gemma models and main frameworks are ready to use, from naive exploration over Kaggle to fully production deployments. Nevertheless, that is not all, you could combine Gemma with HuggingFace for fine-tuning and inference task through its Transformers, with NVIDIA to fine-tune as well, with LangChain to build app with LLM -backed by Gemma-, with MongoDB to build RAG system and others.
Conclusion
A new model family is available and you should take a look, and probably start using it regarding adding value to your idea/business or research! This set is open source, with a great and pushing community and as resource saver as possible, so the takeoff seems promising.
Anyways, the roadmap must always be considered in order to not fail. Here is where the tools for initial approximations -a.k.a available notebooks- come into the scene, they are a good sandbox environment to interact with Gemma!

