Exploring Unity Catalog OSS: Redefining Interoperability
By Felipe Plazas
In today’s IT world, tools, platforms, frameworks, and more are abundant. It seems that there is at least one solution to meet every need. This is why, when something promises to be “universal,” it sounds very promising. Unity Catalog defines itself as the universal data catalog. Let’s analyze the key features that support this claim.
Unveiling Unity Catalog OSS: An Overview of Data Governance
Unity Catalog organizes data in a three-level namespace: Catalog → Schema → Data Asset.
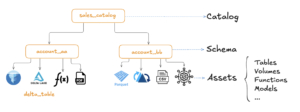
Image credit Unity Catalog 101
- Catalogs are the top-level unit, typically representing business units or broad categories.
- Schemas group data and AI assets into logical categories, often for specific projects or use cases (not to be confused with table schemas).
- Data assets include various objects like tables, volumes, models, and functions for processing and analysis.
Unity Catalog is multimodal, meaning it supports multiple formats, engines, and data assets.
- Support for multiple formats: CSV, JSON, Delta, Iceberg, among many others.
- Support for multiple engines: The premise is to enable the use of Unity Catalog from any processing engine.
- Multimodal: It not only centralizes tables but also integrates ML models, datasets, and functions.
Bridging Formats: How Unity Catalog OSS Connects Delta Lake and Apache Iceberg
The most popular formats in a data lakehouse architecture are currently Delta and Iceberg. A major advantage of Unity Catalog is the ability to use both formats and leverage the benefits of each while avoiding compatibility issues. The backbone of multi-format support is UniForm. This table format allows each table to include metadata in Delta and Iceberg formats, enabling them to be read by either of the two connectors.
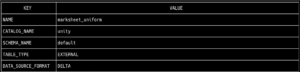
First, we verify that the table is in Delta format by running the command to retrieve the table metadata:
bin/uc table get --full_name unity.default.marksheet_uniform
Now, we will read the table using Apache Spark, but this time pointing to the data catalog through the Iceberg configuration, which will allow it to be read without any issues.
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("Iceberg with Unity Catalog") \
.config("spark.jars.packages", "org.apache.iceberg:iceberg-spark-runtime-3.4_2.12:1.3.1") \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config("spark.sql.catalog.iceberg", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.iceberg.catalog-impl", "org.apache.iceberg.rest.RESTCatalog") \
.config("spark.sql.catalog.iceberg.uri", "http://127.0.0.1:8080/api/2.1/unity-catalog/iceberg") \
.config("spark.sql.catalog.iceberg.warehouse", "unity") \
.config("spark.sql.catalog.iceberg.token", "not_used") \
.getOrCreate()
spark.sql(“select * from unity.default.marksheet_uniform”).show()
Empowering Machine Learning Pipelines: Managing Models with Unity Catalog OSS
One of the biggest challenges for data catalogs is truly integrating all assets within an organization. Unity Catalog stands out by allowing ML models to be registered as catalog objects, a fundamental component for any data-driven organization.
Once all tables, data sources, and files are registered, adding models and their versions becomes a straightforward task in Unity Catalog. Using the MLflow library, we can connect to the data catalog and register the trained model version seamlessly.
To do this, we will train a Random Forest model and, as a test, register it in our data catalog created for this purpose.
import mlflow
mlflow.set_tracking_uri("http://127.0.0.1:5000")
mlflow.set_registry_uri("uc:http://127.0.0.1:8080")
import os
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import pandas as pd
X, y = datasets.load_iris(return_X_y=True, as_frame=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
with mlflow.start_run():
# Train a sklearn model on the iris dataset
clf = RandomForestClassifier(max_depth=7)
clf.fit(X_train, y_train) #
# Take the first row of the training dataset as the model input example.
input_example = X_train.iloc[[0]]
# Log the model and register it as a new version in UC.
mlflow.sklearn.log_model(
sk_model=clf,
artifact_path="model",
# The signature is automatically inferred from the input example
# and its predicted output.
input_example=input_example,
registered_model_name="marvik.demo.iris",
)
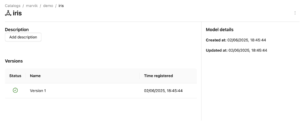
When navigating through the Unity Catalog UI, we will find the registered model with its corresponding version and active status, indicating that it is currently in use:
Challenges of OSS: Limitations Compared to Databricks’ Enterprise Version
- Preventing data lakes or lakehouses from becoming data swamps is essential, which is why lineage and a data dictionary are so important for effective governance. While the open-source version of Unity Catalog does not yet offer object tracing, this functionality is on the roadmap, aligning with best practices for maintaining a well-governed data environment.
- Lake Federation—a feature that simplifies the inclusion of external sources such as databases from different cloud providers or even Snowflake catalogs—is also planned for future releases of the open-source version. This will further streamline cataloging and governance across diverse data ecosystems.
- In terms of Data Governance, the current open-source version already supports user creation for accessing Unity Catalog, and future updates will expand on object-level permissions, row-level access, and other granular controls. These additions will help strengthen overall governance and security in the platform.
- While a global search bar is not currently available in the open-source version, users can still search within specific categories like catalogs, schemas, and tables. An enhanced search experience is in development to improve navigation for large data lakes, and additional UI improvements are planned to bring the open-source experience closer to the enterprise version.
Conclusions
It is true that Unity Catalog delivers on its promise of being universal—it can be used across multiple engines, supports various data formats, and organizes all organizational assets, including tables, files, functions, and even ML models.
However, the open-source version is still far from being production-ready. It remains a promising concept under development, currently at version 0.2. According to the official roadmap, version 0.5 may introduce key missing features compared to Databricks’ implementation, such as Lake Federation and Data Lineage
References

