Data Platforms: exploring the modern options for data management
By Carolina Piro
In today’s digital economy, data is one of the most valuable assets in an organization, crucial in every business area. Yet, with more and more data coming from different systems and devices, in different formats and frequency, keeping track of the existing data assets, their relationship, and who can access them has become harder than ever before. Organizations struggle to maintain visibility, data quality and govern their data, and this lack of control leads to inefficiencies, data silos, compliance risks, and ultimately hinders the true potential of data. The challenge is clear: how to efficiently manage, discover, and govern their data to drive value, and remain competitive?
Modern Data Catalogs come into play to assist in this matter. Evolving far beyond traditional metadata management systems, they have become powerful tools that allow organizations to not only catalog their vast data resources but also to streamline data discovery, enforce governance policies, and foster a data-driven culture across all levels of the organization.
In this blog post, we will analyze the solutions on the market known as modern Data Catalogs or Data Management Platforms, to know which are, among other details:
- their objectives
- the functionalities and benefits they offer
- their target users
Additionally, we will analyze which are the considerations and efforts different kinds of organizations need to make in order to integrate one of these platforms into their technological stack.
Introduction to Data Catalogs
Definition
A Data Catalog is a single source of truth for the metadata of all the data assets in an organization. It supports data governance and helps users search, understand, and trust the data.
- There are three kinds of metadata:
-
- Technical: schemas, tables, columns, file names, report names, anything that is documented in the source systems.
- Business: the business knowledge that users have about the assets, such as business descriptions, comments, annotations, classifications, fitness-for-use.
- Operational: refresh dates and times for the objects, ETL jobs responsible for creating and updating them, user access data, etc.
- These data assets can be Data Warehouses, Datalakes, Data Pipelines, BI Dashboards, queries, etc. So the Data Catalog can be viewed as an end-to-end map of the data available.
- The users for the Data Catalog have primarily been data professionals (data analysts, data engineers, etc.). Today, however, everyone in your organization, even business users, needs context about the data, metrics and reports they are using daily.
Data Governance
Data governance is everything an organization does to ensure data is secure, private, accurate, available, and usable. It includes actions, processes, and the technology that supports them throughout the data life cycle.
It involves:
- Setting internal standards, data policies, that apply to how data is gathered, stored, processed, and disposed of.
- Defining and controlling who can access what kinds of data and what kinds of data are under governance.
- Complying with external standards set by industry associations, government agencies, and other stakeholders.
Regarding Data Catalogs and Data Governance relationship, there are two important comments to make:
- Even though modern Data Catalogs support many of the processes needed to implement Data Governance in an organization, it cannot be said that they completely cover this wide and complex area.For example Data Access Control or Management, a crucial part of Data Governance, is not supported entirely in most tools. With today’s hybrid and multi-cloud environments, enforcing consistent centralized identity governance and administration policies across the enterprise is extremely challenging. For addressing that matter other tools are available in the market, often known as Data Access Governance Solutions. And there is also the possibility to use custom-developed services to address that matter, and other Governance related functionality needed.
- Additionally, the correct implementation of a Data Catalog as a centralized source for collaboration, makes it fundamental to count with Data Governance roles that define certain policies and standards to gather and use data and its corresponding metadata.
Evolution
Traditional Solutions
Data Catalogs have served as central sources of truth for the data for decades now.
- The first wave of Data Catalogs appeared between the 1990s and 2000s, with tools primarily addressing the IT departments, like Informatica and Talend.
The modern concept of metadata emerged at this time, when organizations began managing their data, and these tools collected information about the different data sources, such as tables and columns metadata, constituting the first data inventories. - In the 2010s data became mission-critical for organizations, leading to a broader recognition of its importance beyond the IT team.
New tools, like Alation and Collibra, put more control in the hands of data stewards (who are in charge of the data governance in an organization), emphasizing the need for dedicated teams to handle metadata. However, they also made it more accessible to users in general, bringing data closer to the people who own and use the data.
Also, data catalogs like Hive Metastore became an important component of many data lake systems.
These traditional solutions took all the metadata and integrated it in another siloed location, without providing the users the context they need for the data they are exploring natively where they needed it.
Also, metadata was gathered passively, needing human intervention to collect, edit, and update it, leading to inaccuracies and outdated information.
Modern Data Catalogs
So, with the increase in data volume and use cases:
- A third-generation Data Catalogs appeared in the 2020s, often called modern Data Catalogs.
They are metadata management systems, built on the previous generation’s catalogs, but adding advanced features, which enable them to scale to handle massive volumes of data. Some of them are:
- More data assets are being inventoried, such as Airflow DAGs and Tableau or Power BI reports, and data lineage is provided.
-
- Modern Data Catalogs also take metadata context back to the tools the end users interact with on a daily basis, such as BI tools, Slack, Jira or dbt, to provide this information as part of their daily workflows.
- Active metadata: the tools leverage open APIs to continuously and automatically poll their data sources for the latest updates. And they use this metadata to trigger alerts and recommendations.
- Modern Data Catalogs also take metadata context back to the tools the end users interact with on a daily basis, such as BI tools, Slack, Jira or dbt, to provide this information as part of their daily workflows.
There is no standard nomenclature for these modern Data Catalogs (or Data Governance tools), as they are relatively new in the market and their offerings are heterogeneous.
- Some are still named Data Catalog, but they offer at least some of the enhanced features, such as Data Lineage, Automations, etc.
- Others are referred to as Data Intelligence or Metadata Platforms, for example.
In some literature, the concept of Data Observability can be found, which usually refers to the ability to gain comprehensive insights into the data. So, Data Observability Tool is another name for these modern Data Catalogs, as they encompass more than just a regular Data Catalog (a single source of truth for all metadata), they include, metadata monitoring, data lineage, and other monitoring features, providing a comprehensive approach to data management.
Benefits and Use Cases
The main advantages of having a Data Catalog are the following:
- Efficient metadata search: Using the Data Catalog can save a lot of time in finding the data needed for a specific project. As it provides a centralized view of all the data assets, there is no need to look into different systems or to contact different departments or people.
- Trustworthy data: In a Data Catalog data standards can be defined, clearly defined business metrics can be shared, and data quality measures and alerts can be exposed to all the users.
- Data Dictionary and collaboration: The Data Catalog forms a unified layer that integrates with multiple tools across your data stack, enabling connections between data in different systems and areas of the organization, as well as the reutilization of knowledge, assets, and data preparation efforts. It also allows for common expressions and formulas that form the organization’s vocabulary to be centralized and available to everyone.
- Unified artifacts management: Save metadata for analytics projects and machine learning or data science models, not only source data. And couple this with your existing metadata from raw sources and data warehouses or lakes to have a complete data lineage.
In summary, the Data Catalog allows the organization to make better use of their data, and manage it more efficiently, improving the workflow in most of its areas and so contributing to cost saving.
Data Catalog uses
They provide, for example, a tagging system, so all assets related to a topic or domain can be found together, from data sources to dbt models and dashboards. Additionally, sample queries can be added to Data Warehouse tables, helping users extract insights from the data easily.
A use case in which the need of a Data Catalog can clearly be seen is self-service analytics. Many business users make their own reports, and they often have trouble finding the right data to use for it. Also, they can have doubts regarding how the measures they find in the available tables and files are calculated and whether they are pertinent for their specific analysis. Furthermore, finding the relationships between different data sources can be a challenge as well.
Main Functionality Categories
The functionalities modern Data Catalogs usually provide can be grouped into the following categories or modules:
- Data Lineage
- Business Glossary or Vocabulary
- Data Quality Assurance
- Search and Data Discovery
- Data Management features
Additionally, they provide certain capabilities, used within or to support the main functionalities, which make metadata management and data governance easier:
- Deep integration with multiple data and analytics tools.
- Automation of different tasks (tests, for example, triggering alerts or warnings).
- APIs that allow users to contribute with metadata and documentation, and also expose its data and functionality.
These functionalities and capabilities enable the Catalog to become the de-facto data searching point in the organization, providing abstraction across all the persistence layers (such as Object Stores, Databases, Data Warehouses).
Data Lineage
Data Lineage is the process of tracking the flow of data throughout its lifecycle, providing a clear understanding of where the data originated, how it has changed, and its ultimate destination. It includes source information and any data transformations that have been applied during any ETL or ELT processes.
Documenting the data flow throughout the organization is important for many reasons, such as audit, compliance, and change management:
- For audits and to comply with government regulations, it may be needed to demonstrate the provenance of certain data (from which source the data artifact is being loaded), and/or which transformations are applied to the source data before reaching its final format.
- Users exploring tables, reports or files may be interested in understanding where the data they contain proceeds, and the transformations that have been applied to it. This knowledge is important when using these data assets in different projects or data analysis.
- From a change management perspective, it’s important to have visibility on how changes in different parts of a data pipeline affect each other.
Popular Data Catalog tools usually offer Data Lineage capabilities by table or data set, and often also offer it at column level.
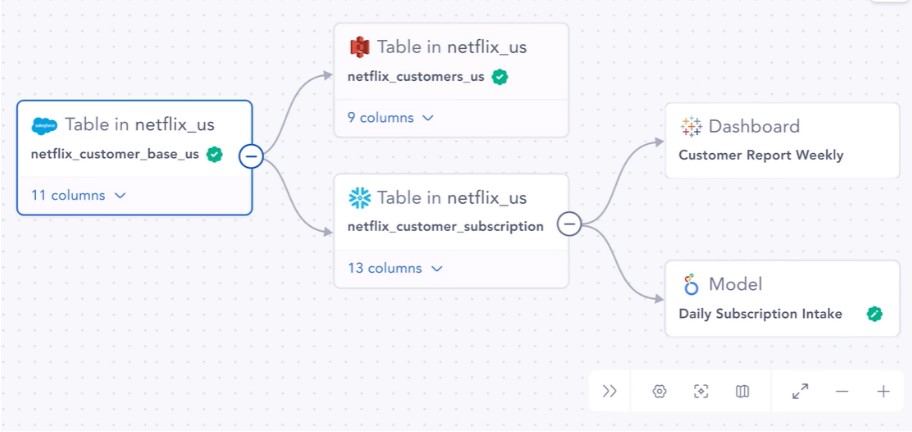
Dataset level lineage in Atlan Platform, extracted from Atlan’s product page.
Business Glossary or Vocabulary
Most organizations develop their own internal language, including names, terms, metrics, abbreviations, and other conventions all of its members use on a daily basis. The Data Catalog provides an adequate place to publish this organization’s vocabulary or glossary, as it is a unique source of truth and is available to all users.
The Catalog also allows establishing relationships between terms and data assets, such as tables or columns, which also has the following benefits:
- It enables users to understand which business concepts are relevant to which technical artifacts.
- It can be used to classify data assets along business concept lines, and then use business concepts instead of technical names for search and discovery.
This also contributes to increasing the users’ trust in the data, as they can see everything that’s related to each concept and asset.
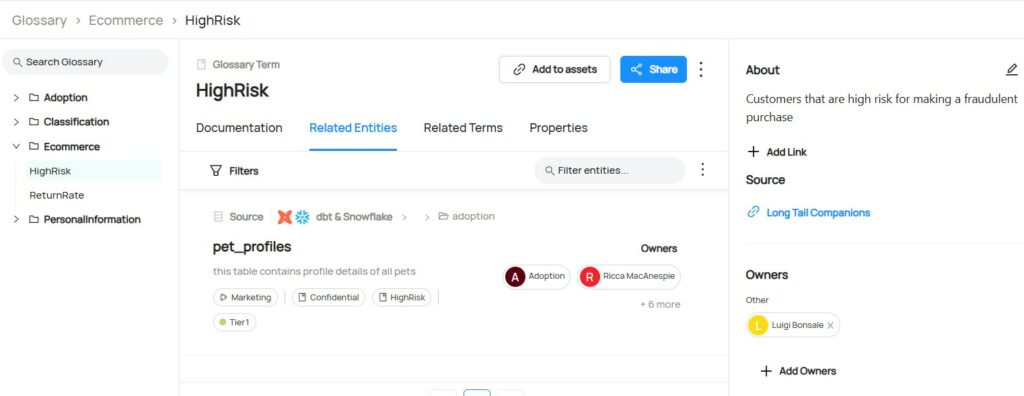
Glossary Term view, showing its related data assets, extracted from DataHub’s demo site.
Data Quality Assurance
Data Quality refers to the condition of a dataset, with regard to its accuracy, consistency, completeness, reliability, and timeliness among other characteristics. A related concept, Data Profiling, is the process of examining, analyzing, and creating useful summaries of data, which helps evaluate its quality.
Data Catalog tools offer Data Quality Monitoring and Data Profiling capabilities:
- Data Profiling features calculate and keep metrics to assess Data Quality, such as distribution statistics measures, completeness, valid values, etc.
- Data Quality Monitoring ensures the reliability and integrity of the data, as it involves continuously assessing data in its different metrics. This automated process helps identify and rectify issues such as data duplication, inconsistency, outdated information, and missing values. Also, based on these profiling results, data can be classified in quality labels in the catalog, indicating its level of trustworthiness.
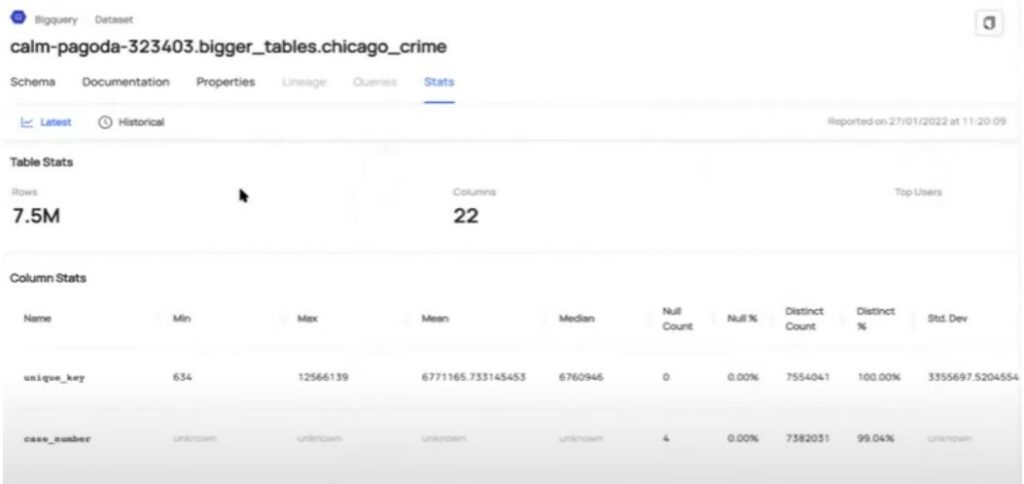
Statistics for a BigQuery table in DataHub, screenshot extracted from DataHub’s “DataHub 101: Data Profiling & Usage Stats” video.
Search and Data Discovery
Modern Data Catalogs have flexible searching and filtering options to allow users to quickly find relevant datasets for Data Science, Analytics, or Data Engineering projects.
- These capabilities include search by tags, keywords, and business terms. Natural language search capabilities are especially valuable for non-technical users. As the Catalogs allow linking business terms with physical assets, non-technical users can use their own vocabulary for search and discovery.
- Ranking of search results by relevance and by frequency of use are also useful and beneficial capabilities, as well as receiving relevant recommendations and/or warnings based on ratings and reviews from other users.
These features allow users to effectively search for the data they need, giving them context about it, but also help them discover additional data they may not be directly looking for.
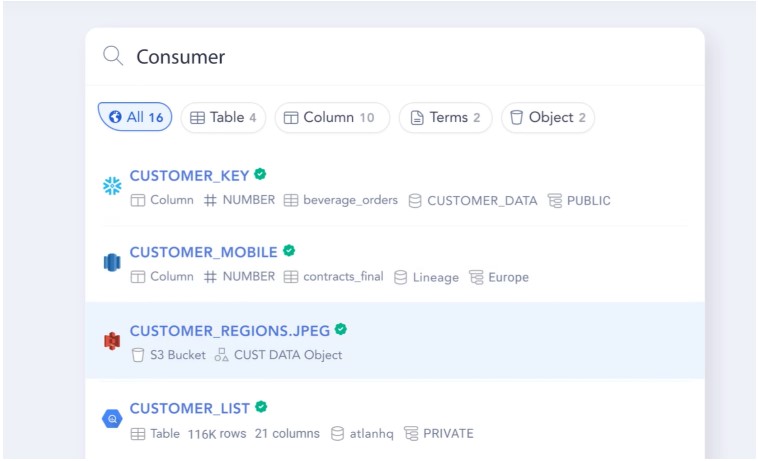
Natural Language search example in Atlan, extracted from Atlan’s product page.
Data Management features
Some of the functionalities that can be grouped in this category are:
- Specifying owners for the data assets.
- Managing permissions to the Data Catalog tool and the metadata and delivering personalized experiences using Roles and Policies.
- Defining Data Contracts for the assets, to enforce formats, tests, data quality levels and other standards.
- Providing Data Usage information, for example: number of users querying it, top users, most frequent queries referencing the asset, etc.
Available Tools
In the market, two main types of modern Data Catalogs can be found: specialized platforms, and specialized services in several Cloud Providers.
Also, data governance and most of the modern Data Catalogs features can be found as individual Cloud Services or within Data and Analytics tools, such as dbt, Power BI, etc.
Data Catalog Platforms
There are many specialized products in the market, and it can be difficult to assess all the possibilities. So, based on Forrester’s market analysis chart, Gartner’s Peer Insights site, and several articles, the following short list of popular tools was gathered as an example:
- Atlan
- Informatica Cloud Data Governance and Catalog
- Collibra Data Intelligence Platform
- Alation Data Intelligence Platform
- DataHub
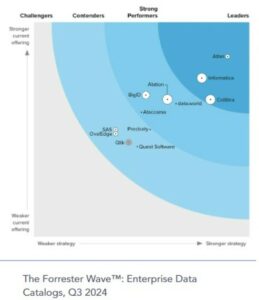
Forrester’s graph on Data Catalogs in Atlan’s site landing page.
In general, the characteristics shared by this type of platform are the following:
- Comprehensive cross-cloud integration:
They are designed to work across multiple environments (clouds, on-premises, and hybrid systems) and they are vendor-agnostic, integrating with a wide range of data sources and platforms, from databases to ETL and BI tools, machine learning platforms and orchestration tools. This makes them suitable for organizations with complex, multi-cloud, or hybrid environments. - Advanced features:
They usually offer enterprise-level capabilities and Data Governance features such as:- Policy Management, workflows for approvals and policy enforcement.
- Data Quality Management.
- Detailed Data Lineage which spans across different services.
- Compliance Tracking for external standards.
- Metadata Enrichment and Discovery focus:
They enable a detailed understanding of data beyond technical metadata, including business and user-generated context (tags, annotations, etc.). Additionally, they incorporate AI/ML features to automatically classify data and suggest relevant datasets, among other tasks, which help scale Data Discovery across large and diverse datasets. - Additional Infrastructure and Implementation costs:
In a multi-cloud or hybrid environment, hosting these platforms can mean additional costs, and the implementation process is a complex and risky project.
Implementation Options
The majority of modern Data Catalogs provide several options for hosting, which can include:
- On-premise: Installed in the organization’s infrastructure, co-located with their on-premise data sources.
- Cloud: Deployed to a cloud provider account, such as Amazon Web Services (AWS) or Microsoft Azure, alongside the organization’s other cloud-based services.
- Software as a Service (SaaS): Deployed and hosted by the Data Catalog vendor, with secure integration points to the organization’s on-premises or cloud services.
- Hybrid: A combination of the above three scenarios.
These options vary in price, convenience, and compliance with internal policies for the organizations implementing them.
Data Catalog Services within Cloud Providers
Most of the Cloud Providers nowadays offer at least some of the modern Data Catalog’s features, whether it is as a unique or several different services. Some of the most popular of such services are:
- Unity Catalog (+ Lakehouse Federation) in Databricks
- DataZone (and Glue Data Catalog) in AWS
- Data Catalog in Google Cloud Platform
As characteristics that this type of Data Catalogs share, we can mention the following:
- Cloud-specific focus:
They are designed primarily for the specific cloud provider’s ecosystem (e.g., AWS Glue Data Catalog is tailored for AWS services, Google Cloud Data Catalog integrates well with GCP). While some may support limited external sources, they excel in their native environments. - Basic Governance with tight Integration:
Some of the Data Catalog’s features they provide are tightly integrated with the provider’s native services, for example: basic metadata management within Data Lakes, and Data Lineage within the Data Integration Service. This reinforces the seamless integration within their respective cloud ecosystem and limitations in multi-cloud or hybrid setups. - Less customization:
They typically offer less customization and extensibility compared to specialized platforms. They are designed to be simpler to use, but they may lack advanced governance features that large enterprises require. - Cost efficiency and simplicity:
They may be more cost-effective for organizations that already operate primarily within a single cloud provider. They are typically easier to set up and maintain in these environments compared to third-party platforms.
Integrate a Data Catalog into an organization
Implementing a modern Data Catalog in an organization is complex, it requires careful planning and clearly defined roles for Data Governance and Management activities.
In this section, we will explore how the Data Catalog integrates with the organization’s existing architecture, what roles and processes are necessary to successfully implement it, and finalize a list of tasks needed to do it.
Architecture
Although every Data Catalog Platform supports a different set of functionalities and uses different technologies, the architecture of such tools can be summarized in the following diagram:
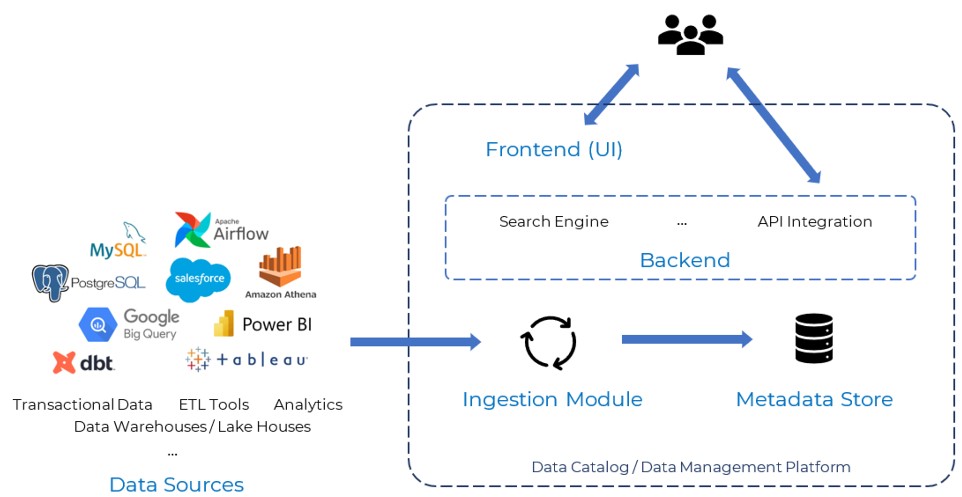
There are 4 main components in this architecture:
- The Data Sources represent all the databases, data lakes, BI tools, and other services containing data assets that exist in the organization. The Ingestion Module is responsible for the communication with these sources and for automating the metadata extraction processes from them.
- The Metadata Store models a unified storage layer for all the extracted metadata. It is often a relational database, but other technologies are also used, alone or in conjunction, such as graph databases, to link entities within and across data sources.
- The Backend provides processing power to support all the Catalog features, such as:
- The Search Engine enables full-text search including entity and field names, descriptions, and more.
- The API Integration allows technical users to interact with the cataloged data assets programmatically.
- And other functionalities.
- The Frontend is the application accessed by the users, where they can see the Business Glossary, use Search and Discovery functionality, and much more.
Data Governance processes and roles
In order to start a Data Catalog implementation project, building a dedicated team is the first step. Roles with expertise in data governance, architecture, engineering, and business domain knowledge are necessary for a successful implementation.
Also, Data Governance activities and processes need to be implemented in the organization for its members to take full advantage of the Data Catalog functionalities, and to guarantee the implementation process’s success.
So, Data Governance roles will be involved in the implementation, in tasks like designing the Catalog’s Data Architecture. But they will also have brother responsibilities, as they will also maintain and administer the Data Catalog.
Some Data Governance processes are:
- Defining clear roles and responsibilities: for data stewards, data owners, and data consumers.
- Enforcing Data Access policies: outlining who can access what data and under what circumstances.
- Establishing and monitoring Data Quality metrics: such as accuracy, completeness, consistency, timeliness.
- Managing Data Lifecycle: defining processes and policies to obtain, store, share and archive or delete data.
Furthermore, the Data Governance team can standardize some processes needed for developing code in different areas. Some examples could be: pre-configure logging and make code templates or Docker images available and ready for the developers to build their work on.
Implementation Considerations
The implementation process is not linear and involves several steps, making an iterative approach fundamental.
Some important considerations before starting an implementation project are the following:
- It is a good practice to start with a small scope targeting, for example, a specific business domain or use case with high impact and well-defined data needs.
- When choosing the Data Catalog tool (and deployment/hosting option), some of the most important considerations are compatibility and integration of the tool with your existing data assets and infrastructure.
- The Data Catalog’s main settings need to be configured, such as the metadata ingestion processes details and the metadata structure and hierarchy. And then the Catalog also needs to be enriched with additional business metadata.
- Before starting, and during the implementation process, promotion of the Data Catalog needs to be addressed, to ensure the adoption of the new tool among all its users. Some related tasks are: communicating its benefits, providing training, etc.
Conclusions
Modern Data Catalogs, or Metadata Platforms are gaining a prominent role in today’s multi-cloud and hybrid technological environments, helping organizations to manage and leverage their data effectively. Their features not only help data stewards and engineers with metadata management and data governance, but also empower business users across the organization to collaborate and make more informed decisions based on trusted, well-documented data.
There is an extensive offer in the market, and the tools and functionalities are continually evolving. Each tool offers unique strengths, and selecting the right one depends on specific business needs, data volumes, and governance requirements.
Additionally, it is important to bear in mind that implementing a specialized Data Catalog means adding a new tool to the organization’s technical stack, and that the process is complex, requiring careful planning and a dedicated and diverse team. Also, mature Data Governance processes and policies need to be in place in the organization or to be implemented in parallel.
Sources
- What is a Data Catalog & How to Choose One in 2023? #LearnWithAtlan
- What Is Data Catalog? | Oracle
- What is Data Governance? | Google Cloud
- What is a Data Catalog? Everything You Need to Know in 90 Seconds
- Modern Data Catalogs: What They Are, How They’ve Changed
- The Evolution of Data Catalogs: Navigating the Complexities of Data Management
- What Is Data Lineage? | IBM
- 6 Reasons Why Data Quality Needs a Data Catalog
- How To Plan, Design, And Deploy A Data Catalog In Your Organization – FasterCapital
- How to Implement a Data Catalog: A Practical Guide | by Luis Arteaga | Medium
- How to Build A Data Catalog: Get Started in 8 Steps
- The #1 Open Source Metadata Platform | DataHub
- Data Catalog Architecture: Components, Integrations, & More
- The Convenience And Security Risks Of Relying On SaaS Platforms
- Data Contracts in DataHub
- Access Policies | DataHub
- Active Data Governance | Atlan
- Dataset Usage & Query History | DataHub
- Similar Blogs | Marvik

