How to use Sapiens to Improve AI generated human images
By Nahuel Garcia
Computers are more powerful than ever before. This means we can do things with AI that we couldn’t do in the past. But, these new AI models need a lot of data to learn. This appetite for data has been successfully addressed in natural language processing (NLP) by self-supervised pretraining. The solutions are easy to understand: they remove a portion of the data and learn to predict the removed content. These methods now enable training of generalizable NLP models containing over one hundred billion parameters.
This idea, is natural and applicable in computer vision as well. In this blog we will study a family of models, Sapiens, developed by Meta based on this idea.

Model architecture
The foundational model of Sapiens is a masked autoencoder (MAE).
Masked autoencoders are self-supervised learners for computer vision. During training a significant part of the image is masked and the autoencoder is given the task of reconstructing the original image.
The MAE that is used in this case has an asymmetric encoder decoder design: The encoder only receives the non-masked patches of the image, while the decoder is lightweight and reconstructs the input from the latent representation (of the visible patches) and the masked patches of the image. Shifting the masked tokens to the small decoder greatly reduces computation, as only a part of the image has to be processed by the encoder. In the next image we have a visual representation of the architecture.
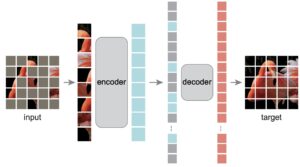
The foundational model, trained in the general task of reconstructing masked images, can be fine-tuned to solve more specific problems such as segmentation, depth and others. In the next section we will review some of the available use-cases.
Sapiens dataset
What type of data is most effective for pretraining? Given computational limits, should the focus be on gathering as many images as possible, or is it better to use a smaller, curated set?
To explore this, the authors created a dataset called Humans-300M, featuring 300 million diverse human images. Their findings showed that a well-curated dataset generally led to better performance compared to simply collecting a larger amount of data. We will explore some of these results in the next sections.
To create the dataset, they utilized a large proprietary dataset of approximately 1 billion in-the-wild images, focusing exclusively on human images. The preprocessing to create the final dataset involved discarding images with watermarks, text, artistic depictions, or unnatural elements. They also used a person bounding-box detector to filter images, with a detection score of less than 0.9 or bounding box dimensions smaller than 300 pixels.
Fine-tuned models
2D pose estimation
2D pose estimation is a technique in computer vision that involves detecting and locating key points on a human body (or other objects) in an image or video frame. These key points represent joints such as the shoulders, elbows, knees, and ankles. The ultimate goal of 2D pose estimation is to map the relative position of these points to form a skeletal structure or “pose” of the subject in a two-dimensional space.
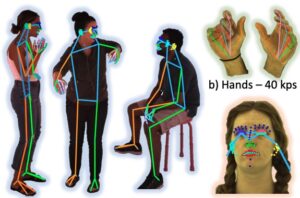
Utilizing an indoor capture setup, the authors created a dataset of 1 million images at 4k and manually annotated the keypoints, including 243 facial keypoints. Compared to the existing methods that utilize at most 68 keypoints, this method captures much more nuances in facial expressions in the real world. This dataset was then used to finetune the pretrained model to be able to solve this specific problem, achieving state of the art performance compared to existing methods for human-pose estimation. Possible use cases for pose estimation could be Human-Computer Interaction (HCI), animation and augmented reality

Body-part segmentation
Human body-part segmentation involves dividing an image or video of a person into distinct regions, where each region corresponds to a different part of the body (e.g., head, torso, arms, legs). Essentially, the goal is to label every pixel in an image with its corresponding body part, allowing the model to differentiate between the various anatomical structures of a person.
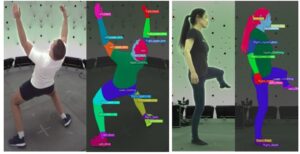
For finetuning for this task, the authors used a dataset consisting of 100K images with a segmentation vocabulary of 28 classes. In this case, the smallest model (0.3B parameters) outperformed the existing state-of-the-art methods. This shows the impact of the higher resolution and human-centric pretraining. Possible use cases for body-part segmentation could be pose estimation, virtual try on, augmented reality, medical imaging, animation and visual effects.

Depth estimation
Depth estimation involves predicting the distance of objects from the camera in a 2D image or video. It provides a three-dimensional perspective, allowing us to determine how far away each point in the scene is relative to the camera.

For finetuning for this task, they rendered 500,000 synthetic images using 600 high resolution photogrammetry human scans. A random background was selected from a 100 HDRI environment map collection, and a virtual camera was placed within the scene, randomly adjusting its focal length, rotation, and translation to capture images and their associated ground-truth depth maps at 4K resolution (see image above). . It is remarkable that the model trained only on synthetic data outperformed the prior state-of-the-art results in all the analyzed scenarios. Some use cases for depth estimation are virtual reality, virtual try on, robotics, surveillance and security

Surface normal estimation
Surface normal estimation is a computer vision task focused on determining the orientation of surfaces in a 3D scene. In simpler terms, a surface normal is a vector that is perpendicular to a given surface at a specific point.

For finetuning in this case the used the same dataset they constructed for the depth model. Once again, this finetuned model outperformed the state-of-the-art human-specific surface normal estimators. Normal estimation can be used for 3D reconstruction, medical imaging, autonomous vehicles and robotics.

Out of distribution examples
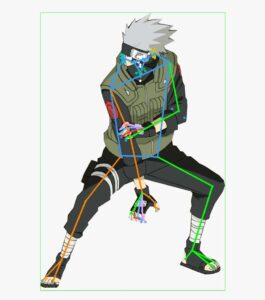
All the models, including the foundational model, were trained using images of real humans. It is not clear what the model would do if we introduced an image of a human generated by AI or even an animated image. In this section we will study a few examples of this and see how the models do in them.
In this first example we can see that the pose estimation model works well even in this case, but the segmentation model works poorly and the depth estimation gives an error because it expects an image with a background. Given that the dataset used for the pose estimation model is the biggest of them all, the poor performance of the segmentation model might be related to the amount of data.


In the next examples we take the same image but we add a random background, as they did to create the depth estimation model. In this case all the models work correctly.




What happens if we take a human generated with AI? Impressively, the models are still able to correctly identify the pose, depth and segmentation of the person in the image, as with the animated character. This could be used as a method to increase the dataset size.




Sapiens use-case
Virtual try on
Given how accurate the clothes segmentation is, we can use it to create masks over clothes that we would like to replace. This segmentation could be used for example to create a virtual try on, as we will see in the examples. We will be using Stable Diffusion XL for inpainting over the masked zone and replacing the clothes with new ones. We will use AI generated persons for the try ons.
Using the depth map we got from Sapiens as input for ControlNet we will be able to preserve the body shape of each individual.
In each case we create a mask over the clothes that we want to replace using the segmentation that we obtained with Sapiens. The masked image is then sent to Stable Diffusion XL for inpainting.



In the first image we replaced the sweater the woman was wearing with a new one. In the second image we replaced the jeans. We notice that the body shape is well preserved in both cases.


For the next example we used the same subject created with SD that we used in the previous section.
In the first image we replaced his jacket with a new one. In the second one he is now wearing grey jeans. Notice how the rest of the image is left the same, this is the result of the very precise segmentation obtained with Sapiens.


Final thoughts
This article explored the new family of models created by Meta “Sapiens,” examining the 4 key fine-tunings provided. These tools were then used to create a virtual try-on for AI-generated images. Experiments were also conducted with out-of-distribution images, AI-generated and animated characters, and it is impressive to see how well the models performed on those. The possibilities this opens up for future developments are exciting.

