Mastering Automatic License Plate Recognition in Wild Environments
By Juliana Faux
Introduction
Automatic License Plate Recognition (ALPR) refers to the task of accurately extracting license plate information from a variety of visual sources, which can range from high-resolution still images to real-time video streams from surveillance cameras.

Applications of ALPR are broad and impactful. ALPR systems are used for identifying stolen vehicles, tracking suspects, and managing parking enforcement. They also play a crucial role in toll collection systems, enhancing traffic flow by automating payments and reducing congestion at toll booths. Additionally, ALPR technology is used in security and surveillance, helping to monitor and control access to secure areas by recognizing authorized vehicles.
ALPR in the wild
When dealing with good images the ALPR task is pretty much solved: most state of the art models can easily achieve high accuracy. But wild environments are unpredictable by definition. Even when we have designed and deployed the perfect camera setup, weather conditions such as rain, fog, or glare can obscure license plates and complicate recognition. Hence, when developing pipelines for ALPR applications in wild environments, we need to take measurements to maintain accuracy even in adverse conditions.

Usual requirements
Implementing an effective Automatic License Plate Recognition (ALPR) system involves several key requirements, with accuracy being crucial. To achieve this, the hardware typically needs high-quality imaging equipment capable of capturing clear, detailed images of license plates in various conditions.
However, in many scenarios, cameras are already in place for other purposes such as surveillance. Leveraging these pre-existing setups can be advantageous, but it requires a robust pipeline that can handle challenges such as low-resolution and blurry images without compromising accuracy.
Requirements become even more demanding when operating in real-world environments. The camera setup must be stable enough to remain still in wind conditions. On the other hand, the processing pipeline must be adept at managing poor-quality images. Real-time applications have also time constraints, requiring fast cameras and an efficient processing pipeline.
Custom ALPR systems
General ALPR systems are designed to deliver satisfactory results across a wide range of environments. In contrast, custom systems can be specifically tailored to meet unique needs—be it for security, parking management, or traffic monitoring. This tailored approach allows fine-tuning models, significantly improving accuracy by optimizing performance for specific environments. Furthermore, custom systems can integrate with existing infrastructure and software, ensuring scalability as requirements evolve. Additionally, they offer the capability to implement specific data protection measures, effectively addressing compliance needs.
In this blog, we’ll explore the essential steps of custom ALPR pipelines that handle both high-quality and challenging images captured in wild environments.
Usual architectures
Architecture v1
A first approach involves working on a single, clear image of the vehicle where the license plate is both visible and legible. A basic pipeline to obtain the text would include the following steps:

- Image Acquisition: capture an image of a car/license plate.
- Image Preprocessing: prepare the image to improve license plate detection results.
- License Plate Detection: locate the license plates within the image.
- License Plate Preprocessing: prepare the license plate image to improve text recognition results.
- Optical Character Recognition (OCR): extract text from the license plates.
While this first approach is straightforward, its robustness is limited by its heavy reliance on the quality of the acquired image and the adequacy of the preprocessing step. If the acquired image is a clear, close-up shot of the license plate, subsequent steps will generally face fewer to no challenges at returning optimal results. We can obtain this high-quality image by strategically positioning a well-chosen camera. However, it is well known that wild environments are affected by uncontrollable factors such as weather conditions, illumination changes, human error and other unforeseen circumstances that impact the acquisition, even having a perfect camera setup. For this reason, it is crucial to have a robust preprocessing pipeline under our sleeve!
There are ongoing efforts in the literature aimed at addressing these situations by enhancing the preprocessing phase, which will be discussed later in this blog.
Architecture v2: a format-aware architecture
License plate datasets are usually gathered from vehicles within a specific country, state, or region. Consequently, the challenge often involve
 s recognizing text on license plates that adhere to a particular format or class, and are typically very different from each other. For instance, a dataset of US license plates might include Nevada plates, with black text on a sky-blue background and green/orange mountains at the bottom. These plates follow the NNN-ANN format, where “N” represents a number and “A” a letter. In contrast, Hawaiian license plates, characterized by their rainbow background and the AAA-NNN format, stand out clearly from Nevada’s . A machine learning model can effectively capture and differentiate these unique features, enabling accurate identification of each state’s plates.
s recognizing text on license plates that adhere to a particular format or class, and are typically very different from each other. For instance, a dataset of US license plates might include Nevada plates, with black text on a sky-blue background and green/orange mountains at the bottom. These plates follow the NNN-ANN format, where “N” represents a number and “A” a letter. In contrast, Hawaiian license plates, characterized by their rainbow background and the AAA-NNN format, stand out clearly from Nevada’s . A machine learning model can effectively capture and differentiate these unique features, enabling accurate identification of each state’s plates.
License plate layouts and formats are mostly known, so detected texts can be forced to comply with its corresponding standard. In order to implement this, a more advanced architecture would include two additional steps:
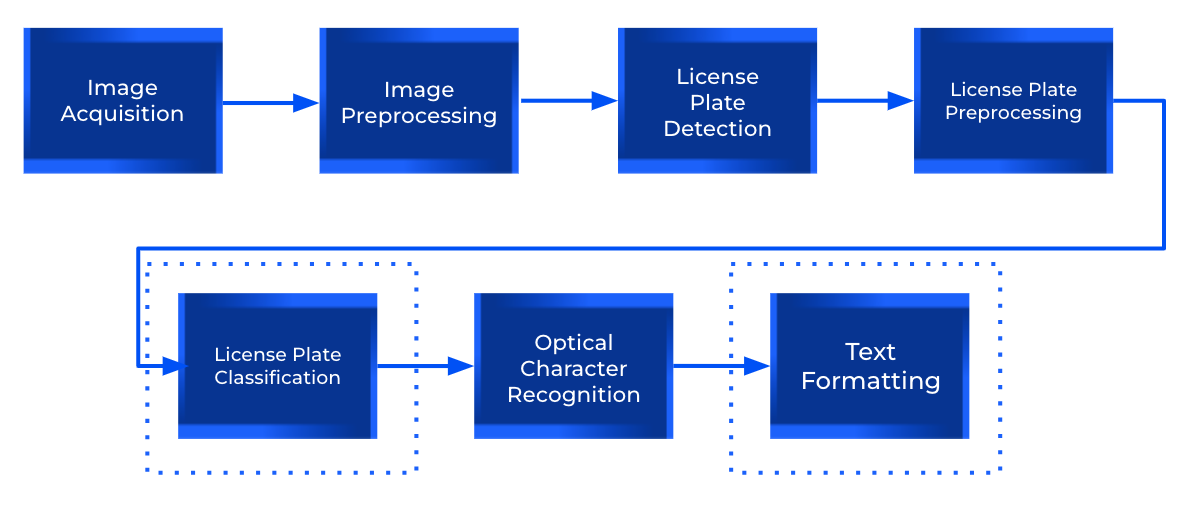
- License Plate Classification: classify the detected license plates based on previously known layouts, which may vary by geographical location or jurisdiction (e.g., country, state, or international formats).
- Text Formatting: convert the extracted text into a standardized format, appropriate for each license plate class (e.g., Mercosur or specific US states).
Architecture v3: leveraging video
License plate images are often captured by surveillance cameras, resulting in video footage rather than single images. These videos provide multiple frames of the same vehicle and license plate from various distances, illumination conditions, and angles, significantly enhancing text detection robustness. To integrate this information effectively, a typical architecture would include the following additional steps:
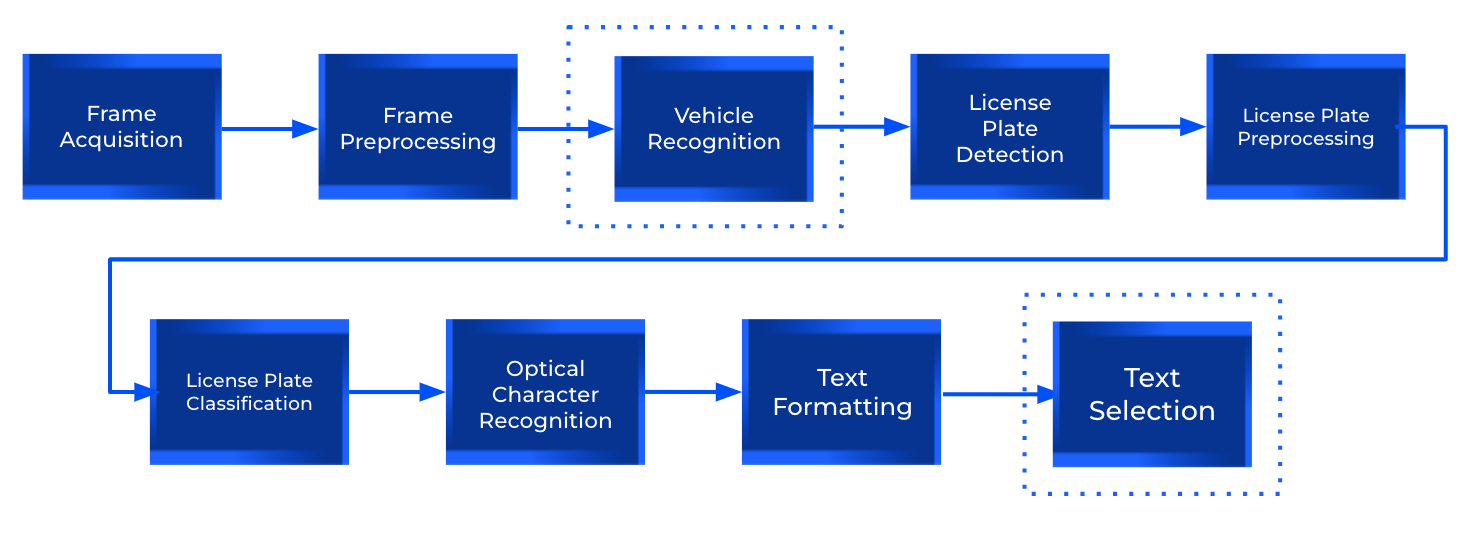
- Vehicle Recognition: identify and track vehicles within each frame, grouping multiple detections of the same vehicle together.
- Text Selection: choose the most accurate license plate text from potential candidates. This decision may be based on detection and classification confidence scores, text recognition confidence, and compliance with the expected format. Alternatively, we could select each character individually, using the most frequently occurring one from frames of the same vehicle.
Therefore, if there is at least one clear image of the license plate for each vehicle, this approach can accurately assign a license plate text to each one, without requiring extensive preprocessing.

Detecting wild license plates
Being able to extract a cropped image of a license plate is clearly a mission-critical step. This includes checking for the presence of a license plate and, if found, returning its bounding box coordinates along with a confidence score.
Pretrained detectors
Pretrained detectors offer a quick and efficient solution for license plate recognition with minimal coding effort, making them an attractive choice for many applications. They are designed to swiftly identify text within rectangular regions, which can be advantageous for rapid development. However, these detectors may sometimes incorrectly identify text in rectangles that are not license plates, leading to false positives. Additionally, they might struggle in specific conditions such as poor lighting, extreme weather, or complex backgrounds, where their performance can be significantly compromised. Consequently, while pretrained detectors offer a solid starting point, their limitations in certain scenarios may require additional customization or alternative approaches to ensure reliable recognition in diverse environments.
The following images correspond to detection results with YOLO detector over images extracted from OpenALPR dataset.

Examples above illustrate that while general detectors perform well in many situations, they often struggle when there is text on the vehicle that doesn’t correspond to a license plate. Additionally, the detection score often exceeds desired levels when non-license plate text is mistakenly identified as a license plate. This makes it an unreliable indicator. Fortunately, we can minimize these false positives through model fine-tuning.
Why custom detectors?
Custom detectors offer significant advantages by leveraging specific information about license plate layouts, which enhances recognition accuracy. Additionally, incorporating data augmentation techniques that include images taken in adverse weather conditions allows the model to become more robust and reliable in real-world scenarios. This tailored approach ensures that custom detectors are not only precise but also adaptable to a variety of challenging environments.
In the following section, we highlight an insightful paper that demonstrates the results achievable through model customization.
In focus: Image-Adaptive YOLO for Object Detection in Adverse Weather Conditions (2021)
General object detection models trained on high quality images often fail to achieve satisfactory results under adverse weather conditions. Moreover, applying enhancement techniques before detection may achieve better image quality, but it does not necessarily improve object detection. This paper proposes to adaptively enhance images to improve detection performance of YOLO in foggy and low-light conditions.
The proposed pipeline consists of a CNN-based parameter predictor (CNN- PP), a differentiable image processing module (DIP) and a detection network. The CNN-PP module predicts DIP module parameters from a downsampled (via bilinear interpolation) low resolution image, the DIP module is applied to the high resolution image to obtain a processed output and finally YOLOv3 model is applied on the processed output to detect objects.
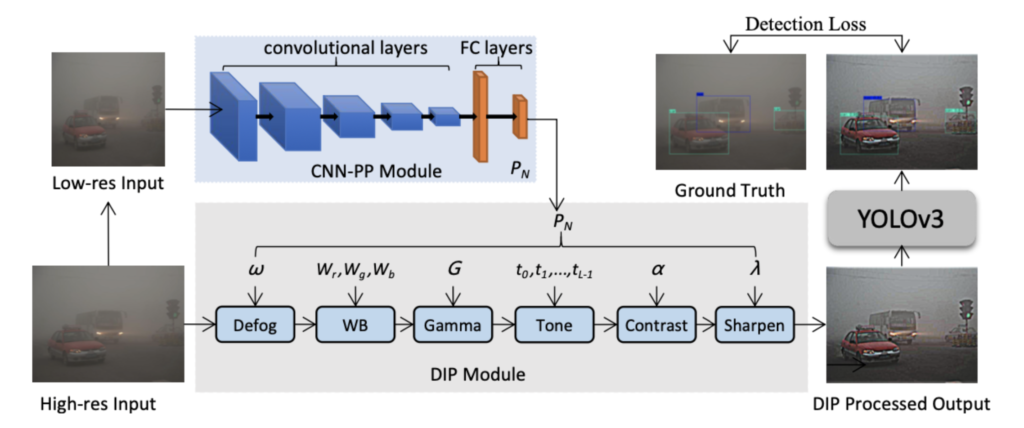
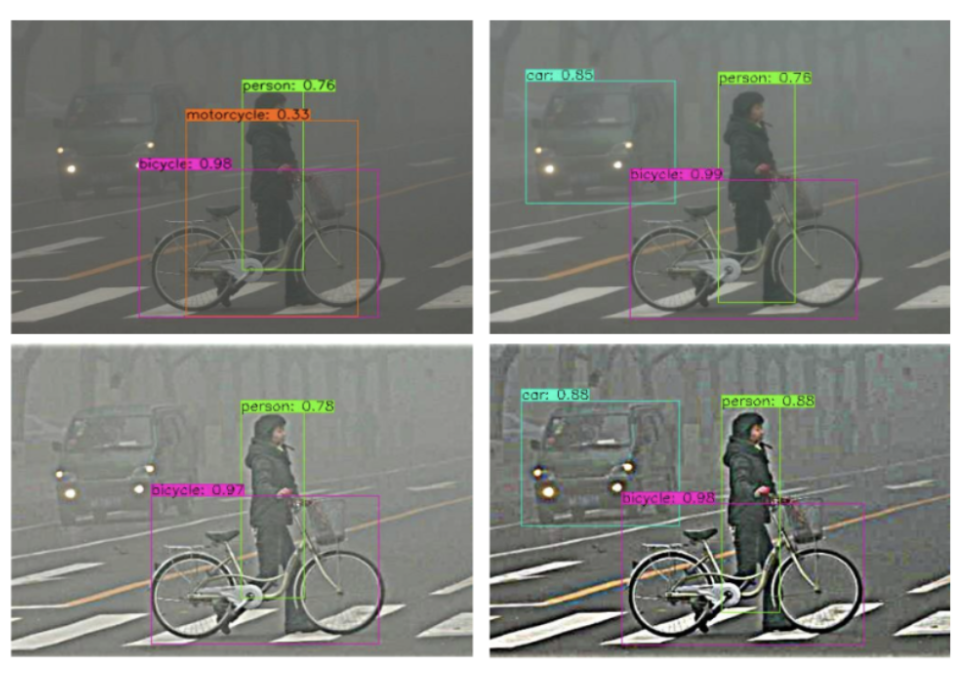
The image below illustrates how tailored preprocessing can significantly enhance the detection of obscured objects using this strategy. Results are shown for DIP-processed outputs with combinations of defog, pixel-wise and sharpen filters.
Preprocessing wild license plates
The main purpose of this step is to deliver the best possible license plate image to the OCR module. Preprocessing is always recommended, but it becomes mandatory when dealing with lower-quality license plate images, such as those taken in wild environments by surveillance cameras.
But why is it necessary to preprocess the license plate crop, if it has already undergone the initial preprocessing step? And what does “best possible license plate image” actually mean?
Preprocessing the region of interest
Local preprocessing targets specific regions of an image, such as the area containing a license plate. Preprocessing parameters are determined using only pixels in the cropped image, which is the adequate approach for tasks requiring fine-grained detail in specific areas.
In contrast, global preprocessing applies transformations across the entire image. While this approach can be useful for some tasks, it is less effective for scenarios requiring precision in specific areas and can also be inefficient for real-time applications.
Hence, to avoid overlooking the specific characteristics of the license plate area, incorporating a license plate-specific preprocessing step is essential. This is especially important if the OCR module lacks its own preprocessing capabilities.
Best possible image
Each OCR module has specific preprocessing requirements for optimal performance, so those that incorporate built-in preprocessing (such as PaddleOCR) are generally preferable. This variation means there isn’t a one-size-fits-all standard for what constitutes a good license plate image, but there are key factors that are important across all OCR systems.
The following images were extracted from OpenALPR dataset.
- First row: these images are optimal for OCR performance. They feature front views of plates that are in focus, almost free from blurring, distortions, or occlusions in text. The illumination is even, exposure is appropriate, and there is high contrast between the text and background, ensuring accurate recognition results.
- Second row: these images present scenarios where OCR modules can still perform well despite some imperfections. They may exhibit mild blurring, tilting, low resolution, poor illumination, slight focus issues and minor distortion due to perspective.
- Third row: these images, while legible, are more challenging for OCR. Severe issues such as low resolution, high noise levels, and low contrast may hinder accurate text recognition.

To summarize, OCR systems tend to achieve optimal performance on images that meet the following conditions:
- Even illumination
- High text-background contrast
- In-focus text
- Horizontally aligned text
- Frontal view
Let’s dive deeper into the preprocessing steps we can apply to obtain such images.
Traditional pipeline
A traditional pipeline for license plate preprocessing would include the following steps:
- Gaussian filtering
- RGB to grayscale conversion
- Binarization
- Morphological operations
Below are two examples demonstrating the results of the traditional preprocessing pipeline using identical parameters. While the pipeline enhances the first license plate, it degrades the second one.

This traditional approach may perform well on certain images but is likely to fall short with many others. Additionally, fine-tuning the parameters of this conventional pipeline for optimal results is both challenging and time-consuming, often lacking generalizability. Employing machine learning techniques for preprocessing can offer superior results and effectively address a broader range of challenges.
Preprocessing license plates with ML
Various machine learning techniques are widely used for preprocessing to enhance OCR accuracy. Convolutional Neural Networks (CNNs) and autoencoders, in particular, have demonstrated great performance for denoising tasks. We can specifically train them to clean and improve the quality of license plate images in the dataset, leading to significantly better OCR results.
Why custom ML preprocessors?
Using custom preprocessors for license plate recognition is crucial for fine-tuning the system to handle particularities of the dataset. Weather elements like rain, fog, or glare can obscure license plates and complicate recognition, while varied backgrounds, such as urban settings or rural environments, can introduce distractions that confuse pretrained models. We can tailor custom preprocessors to address these challenges for specific environments, license plate layouts and fonts. This ensures that the recognition system remains accurate and reliable, improving overall performance and reducing error rates.
In the following subsections we will present some state of the art approaches to preprocessing techniques for improving OCR performance, developed specifically for license plate detection in low-quality images and bad weather conditions.
Enhancing License Plate Super-Resolution: A Layout-Aware and Character-Driven Approach (2024)
A common challenge for OCR in low-quality images is characters blending with the background or adjacent characters. To address this, the authors develop strategies to produce license plate images that are not only of high quality and resolution but also more accurately identifiable by OCR models.
They introduce a novel loss function, designed to integrate character recognition directly into the super-resolution process: the Layout and Character Oriented Focal Loss (LCOFL), which accounts for factors such as resolution, texture, and structural details, optimizing the super-resolution process to enhance LPR accuracy. Additionally, they enhance character feature learning through deformable convolutions and shared weights in an attention module.
They employ an OCR model as the discriminator in a GAN-based strategy to guide and refine the super-resolution process, and train their model using pairs of images, as shown below:

They conduct experiments on the RodoSol-ALPR dataset, yielding notable results, as demonstrated in the following figure:

SNIDER: Single Noisy Image Denoising and Rectification for Improving License Plate Recognition (2019)
Denoising and rectification of license plates tend to be addressed separately. This paper focuses on solving both problems jointly, using a Denoising Sub-Network (DSN) and a Rectification Sub-Network (RSN), both having U-Net as backbone. The proposed approach consists of three parts: denoising + rectification, count classification + binary segment prediction and text detection + classification.
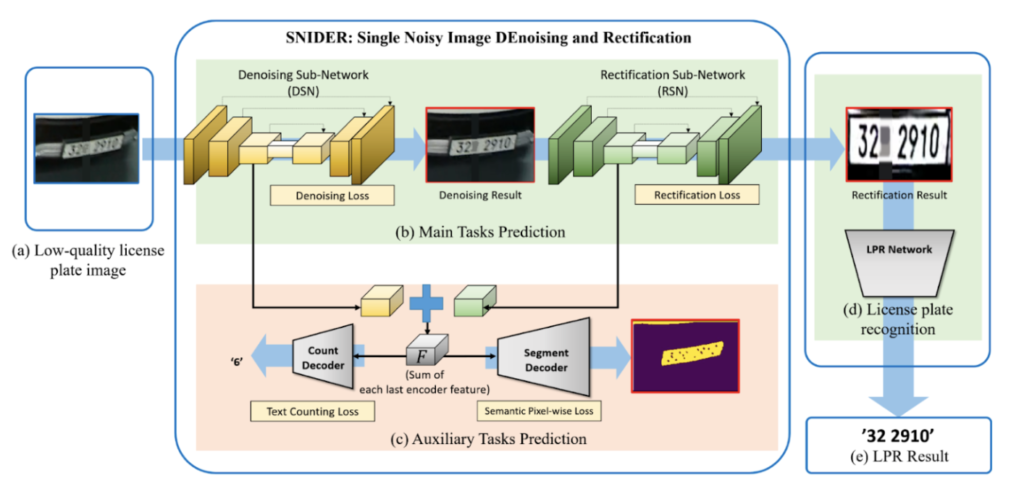
They propose using a weighted sum of losses as the training loss metric, incorporating rectification, denoising, segmentation, and counting losses. This ensures that the network addresses all these tasks comprehensively. The paper presents promising results, including the recovery of license plates that are unreadable to humans, as shown below.

Recognizing not-so-wild text
We got here with a nicely preprocessed license plate, containing readable, not-so-wild text. In this case, it is very likely that a general OCR framework (e.g. Tesseract, EasyOCR, PaddleOCR) outputs accurate texts with high recognition scores, and our work ends here. But if we are getting low recognition scores, we need to keep up the good work.

What to do when OCR fails: making changes on the OCR module
The first thing to try out is to run experiments with another OCR module. As stated before, different modules have different preprocessing requirements. OCR modules that come with a built-in preprocessing feature are easier to use and generally perform better across a variety of images. Moreover, some OCR modules are more sensitive than others to LP preprocessing. This means that even minor adjustments in preprocessing parameters can lead to significant changes in the results, which is an undesirable behavior.
After selecting the OCR module that performs best, we can enhance its robustness by fine-tuning it. This allows the module to better handle specific layouts, text fonts, and conditions unique to the data. Data augmentation is also worth exploring: by adding effects like blur, tilt, and other artifacts to the images, we can help the model become more robust in dealing with challenging situations.
Changing and fine-tuning the OCR library can significantly boost performance with minimal code adjustments, but it is still very likely that some important cases might need some extra attention. To address those wild cases, we may need to revisit and tune the preprocessing stage. Tuning traditional image preprocessing techniques can be quite time-consuming and may not generalize well across different scenarios. For more robust results in varied environments, fine-tuned machine learning processors are the best choice.
Another interesting strategy is the use of a cascade of OCR modules. Starting with the simplest and fastest module, if it doesn’t yield satisfactory results (i.e. returns a low text confidence score, or no text at all), proceed to the next one in the sequence. Modules can be prioritized based on their performance and speed to align with the requirements of the ALPR system, ensuring both efficiency and accuracy.
Bonus track: format compliance enforcing
Initially, we could just check for compliance (e.g., ensuring a Hawaiian plate adheres to the AAA-NNN format), and discard detections that don’t comply. Taking it a step further, we could also force the detection to comply, correcting simple OCR mistakes.
Basic formatting using heuristics
The first approach to detection formatting involves defining two dictionaries. One dictionary maps characters to integers, while the other maps integers back to characters. Two dictionaries are needed, as confusions between characters and integers may not be symmetric. We can determine these dictionaries with heuristic rules, according to common confusions among OCR modules.

For example, a frequent error is misinterpreting a “4” as an “A” and vice versa. If a license plate in the NAA-NNN format begins with an “A”, it is almost certainly a mistake, with the correct character likely being a “4”.

Advanced formatting using tailored dictionaries
While the strategy outlined above improves results significantly, it relies on general dictionaries of OCR confusions across diverse datasets. This dictionaries won’t take into account that specific font types may avoid or lead to specific confusions. For example, Mercosur license plates feature a “D” that resembles an “O”, leading to recognition errors in some OCR modules. Therefore, an advanced formatting strategy should include tailored dictionaries for each license plate font.
We can implement this advanced strategy as follows:
- Classify license plates: categorize them based on their layout (e.g., Nevada, Hawaii).
- Run text detection: identify and extract text from the plates.
- Create confusion matrices: compare detected text with ground truth, to create confusion matrices for each layout and understand character recognition issues for each class.
- Generate the dictionaries: create dictionaries for each license plate class, focusing on common character-integer confusions identified in the matrices.
Conclusions
In this blog, we’ve highlighted the importance of developing ALPR pipelines that can effectively handle challenging images in wild environments, where robustness is critical. This approach helps minimize the impact of uncontrollable events on accuracy.
We’ve introduced three versatile architectures commonly used for ALPR, each adaptable to various camera inputs and system requirements. When working with video, we can employ vehicle recognition strategies to extract the clearest license plate image for each vehicle.
Additionally, we’ve explored the importance of fine-tuning strategies for the detector, preprocessor, and OCR to ensure that each step optimally supports the next, ultimately boosting accuracy. We also discussed how implementing data augmentation strategies can greatly enhance the system’s robustness.
Finally, we’ve shown how a license plate classifier can use knowledge of format standards to correct common errors from tailored confusion matrices, further improving accuracy and reliability.
References
- PP-OCR: A Practical Ultra Lightweight OCR System
- Autoblog: A partir de marzo se empadronará con la patente Mercosur
- License plate recognition in low quality image by using Latent Diffusion YOLOv7
- A Fair Evaluation of Various Deep Learning-based Document Image Binarization Approaches
- Real-time license plate detection and recognition using deep convolutional neural networks
- A CNN-Based Approach for Automatic License Plate Recognition in the Wild
- License Plate Detection and Recognition in Unconstrained Scenarios
- Enhancing License Plate Super-Resolution: A Layout-Aware and Character-Driven Approach (2024)
- SNIDER: Single Noisy Image Denoising and Rectification for Improving License Plate Recognition
- OpenALPR
- RodoSol-ALPR
- LPR database
- License Plate Detection and Recognition using YOLO V8 EasyOCR

