By María Noel Espinosa
Introduction
Have you ever wondered how we can determine the cause and effect relationships between different variables? Causal inference is the answer! It’s a fascinating field that allows us to uncover the hidden connections between different factors and predict how they will interact in the future. From social sciences to medicine and beyond, it is a critical tool for unlocking insights and making informed decisions.
In a world where machine learning is more common every single day, it is important to recognise its limitations. Machine Learning models only learn to predict outcomes, but have no idea how to alter reality to produce the desired result.
In this post, we’ll delve into the world of causal inference, exploring its power and potential. We’ll take a look at a real-world example where causal inference is useful. We are going to mention some models and tools that make it all possible. Whether you’re a curious learner or an expert data analyst, you won’t want to miss this thrilling adventure into the exciting world of causal inference!
What is causal inference? Why is it important?
Causal inference is a statistical framework useful to understand the relationship between a cause and its effect. The goal of this framework is to identify the causal effects of one or more variables on an outcome. This should be done while controlling for other factors that may influence the outcome.
Causal inference can help us understand the true causes of the phenomena we observe. By using rigorous methods to identify causal relationships, we can reduce uncertainty, improve efficiency, and ultimately make a positive impact on the world around us. The group of big companies that have used causal inference include Uber and Netflix.
For the remainder of this blog we’ll keep in mind the following problem: suppose a company has recently launched a new marketing campaign and wants to know if it was effective in increasing sales revenue. In this case scenario the marketing campaign will be the treatment and the sales revenue the outcome.
Types of causal inference: Experimentation vs. Observation
There are two main types of causal inference: experimentation and observation. Understanding the differences between these types is essential in order to accurately interpret data and draw valid conclusions.
Experimentation
Experimentation involves actively dividing subjects into a treatment and a control group. The goal is to control for all other variables that may be influencing the outcome besides the treatment. In this setting changes in the outcomes are exclusively a consequence of the treatment.
In our example this type of causal inference could be solved by a randomized controlled trial (RCT). RCT involves picking a randomly selected group of clients to be put through the campaign while another randomly selected group is left out of it. The goal of randomizing the selection is that the difference in the outcome between the groups is a consequence of the campaign and not of other factors. However, this may not be possible as clients may not want to participate in the campaign and that choice hinders the randomization process.
Observation
Observational studies, on the other hand, involve observing the natural variation in a variable and its effect on another variable. Unlike in experiments, the variables are not actively manipulated, and there is no control over outside influences. Observational studies are common in fields such as epidemiology and economics. In those fields it is usually impossible or unethical to manipulate variables in a controlled setting.
Going back to our example, this type of analysis could be carried by following a few steps. First, we would need to collect data on the application of the marketing campaign, the sales revenue, and other relevant variables that may influence the outcome of interest. These variables could include: the type and content of the marketing campaign, the market conditions during the study period, characteristics of the customers such as demographics, among others. Then, we would need to formulate a model that represents the causal relationships between the selected variables.
Finally, we would need to estimate the effect of the treatment while accounting for possible confounders. These confounders are the variables that influence both the outcome and the treatment. Confounding variables impact to whom the marketing campaign was given to and the sales revenue. Some confounder variables in this scenario may include the economic condition, age and geographic location of the client, among others.
Which to pick?
To sum up, while experimentation provides strong evidence of causation, observational studies can also provide valuable insights when experiments are not feasible. However, because of the potential for confounding variables, observational studies are weaker evidence than experimental studies. Ultimately, the choice between experimentation and observation depends on the research question, available resources, and ethical considerations.
For the rest of this blog we’ll focus on causal inference with observational data as it is often more readily available than experimental data and it can provide insights into how variables interact in real-world settings.
Causal inference from observational data
Causal models are a key tool for understanding and testing causal relationships between variables. A causal model is a formal representation of a causal system. It identifies the variables of interest, their causal relationship, and the mechanisms that link them together. The selection of a model is the first step for causal inference.
With the model picked the following is to pick a method. The method is going to depend on the data available, the goal of the analysis, the working hypothesis about the observed variables, and the relationship between treatment and outcome.
A great tool to analyze causal relationships is Directed Acyclic Graphs (DAGs). These type of graph are visual representations of causal relationships. In addition, when all confounding variables are observed, methods like Double ML, Doubly Robust Learning and Meta Learners can be used to estimate the causal effect. However, when this condition is not met, other approaches like instrumental variables can be used.
The final step for causal inference is to evaluate the causal effect estimation. Using appropriate statistical tests and sensitivity analyses we can assess the robustness and reliability of the results. Below we present a complete causal inference pipeline using observational data.
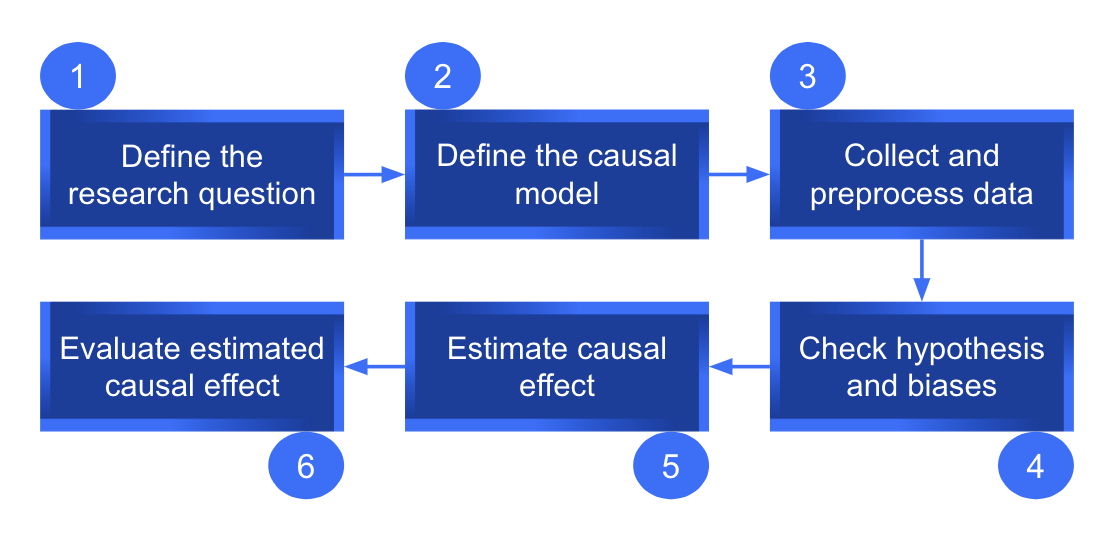
Causal inference pipeline using observational data.
How much data do I need?
The amount of data required for performing trustworthy causal inference depends on several factors. Some of them are: the complexity of the causal relationships, the number of confounding variables, the type of analysis method used, the degree of heterogeneity and variability in the data, and the desired level of statistical power and precision.
In general, having a larger sample size is beneficial for causal inference. Bigger datasets increase the precision and reduce the risk of bias in the estimated causal effect. However, there is no strict rule for the minimum sample size for causal inference problems. The amount of data required may vary depending on the specific context and research question.
Python Tools for Causal Inference
Some relevant tools for causal inference with Python are:
- DoWhy: Python library, by Microsoft Research, that aims to spark causal thinking and analysis. DoWhy provides a wide variety of algorithms for effect estimation, causal structure learning, and diagnosis of causal structures. It includes root cause analysis, interventions and counterfactuals.
- Econ ML: Python package, by Microsoft Research, that applies the power of machine learning techniques to estimate individualized causal responses from observational or experimental data. Is compatible with DoWhy. Provides state of the art methods for estimation in the causal analysis.
- CausalML: Python package created by Uber that provides a collection of uplift modeling and causal inference methods using machine learning algorithms.
- Causalinference: Software package that implements various statistical and econometric methods used in the field variously known as Causal Inference, Program Evaluation, or Treatment Effect Analysis.
- Causallib: Python package for Causal Analysis developed by IBM. The package provides a causal analysis API unified with the Scikit-Learn API. Therefore a complex learning model can use the high level fit-and-predict method.
- Causalimpact: Python package for causal inference using Bayesian structural time-series models.
Challenges in Causal Inference
Causal inference involves making inferences about the causal relationship between variables based on observational data. There are several challenges in performing causal inference, including confounding bias, selection bias, measurement error, and limited data.
On the one hand, confounding bias can arise when exposure and outcome share an uncontrolled common cause. This would happen in our example if we could not observe demographic information that affected whether or not the clients are submitted to the campaign and the amount of purchases they make.
On the other hand, selection bias occurs when the selection of units into the treatment or control group is related to the outcome variable. In our example this would be the case if the company showed the campaign only to the most loyal customers. Here, there would be a systematic difference between the clients who receive the treatment and those who don’t.
Measurement error takes place when the observed values of variables are not an accurate reflection of their true values. In our example this could happen if the company cannot identify which customers were exposed to the marketing campaign. Finally, limited data can make it difficult to estimate the causal effect with precision. This is especially important when there are many confounding factors or the treatment effect is small.
Addressing these challenges requires careful consideration of the research question, the available data, and the assumptions underlying the chosen method for causal inference. It is important to acknowledge these challenges to ensure causal inference provides valid and reliable results.
Final thoughts
Causal inference is a powerful tool for understanding the relationships between variables and predicting how they will interact in the future. We have seen that both experimentation and observation can be used for causal inference. Observational data though is often more readily available and can provide insights into how variables interact in real-world settings. To accurately identify and quantify causal relationships in observational data, it is essential to use appropriate statistical methods and carefully consider potential confounding variables.
Fortunately, there are several Python tools available to help with causal inference analysis. These tools offer a wide variety of algorithms for effect estimation, causal structure learning, diagnosis of causal structures, root cause analysis, interventions, and counterfactuals.
In conclusion, causal inference can be critical for making informed decisions in many areas. The range of applications include business, social sciences, medicine, and beyond. By using rigorous methods to identify causal relationships, we can reduce uncertainty, improve efficiency, and ultimately make a positive impact on the world around us.

