Real-Time Video Processing: deploying applications into the cloud
By Lucas Berardini
How does Amazon Go charge you without the need for a physical checkout? Is it possible to detect failures in manufactured products just by analyzing a camera’s recording? Can we develop an application that supervises cultivated fields to detect pests and optimizes irrigation? The answer to all these questions lies in the field of machine learning with real-time video processing: a camera (or a set of cameras) is used to record video, and this video is processed on the fly so that the desired result is available as instantaneously as possible, producing near real-time results that might impact all kinds of businesses.
There is a huge range of Machine Learning (ML) applications that might benefit from a real-time video processing approach. Tracking objects or people across time (for video surveillance applications), automatic object detection in autonomous driving applications, raising an alert on a manufacturing industry whenever some incident is detected by a video camera, and many more. All these applications share some basic computer principles and it is possible to deploy them using similar architectures.
In this post we will explore some alternatives for designing architectures to deploy production-ready machine learning applications that leverage real-time video processing. We will analyze the advantages and disadvantages of different architectures and explore cloud alternatives in the most relevant cloud vendors. The main goal of this post is to provide a set of possible real-time video processing architectures that might be useful in design stages.
Framing the problem
The image below shows a high-level diagram of what we are trying to build. A device captures video and sends it to a communication module that broadcasts the video into a processing module. In this processing stage, we prepare the video frame by frame for machine learning. The inference takes place in the next module, where an ML application generates predictions based on the input. The application can involve object detection, face recognition, image segmentation, or any other computer vision task. Finally, we sent the output to the last module, where end users consume it.
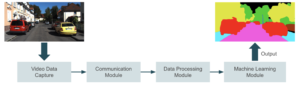
There are two main approaches to address this problem:
- Using the camera devices only for data capture, and sending the video to a cloud provider or a dedicated server. The server handles all data processing, machine learning inference, and output generation. In this case, model training and deployment pipelines take place in the same cloud environment.
- Leveraging edge computing devices to bring machine learning inference near the camera devices, and stream only the inference output into a cloud provider. Here it is necessary to deploy the trained models on the edge and use GPU accelerators to run inference on-site.
The image below shows a high-level diagram comparing these two approaches.
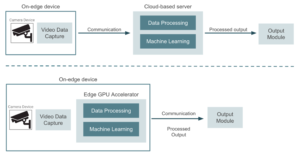
Just as a reference, some of the hardware alternatives that can be used when going for an edge-based architecture are the NVIDIA devices (Jetson Nano, Jetson Xavier NX, and Jetson AGX Xavier, with different prices and different computing power capabilities). These are essentially GPU devices with performance computing capabilities we can connected directly to the video devices. It is also possible to use USB-based devices such as Google Coral. These consist of USB accelerators connected to existing devices such as Raspberry Pi boards, and offer TPU (tensor processing unit) capabilities.
At this point, it makes sense to ask ourselves which approach will give us the best cost/benefits outcome, and how to make this decision.
Let’s think of the first approach, a set of security cameras that capture video and send it to a cloud environment where we host a deployed machine learning model for object detection. All video devices perform the data-capturing process but the cloud environment takes care of processing the rest of the pipeline, away from the edge devices.
There are some advantages of a cloud-based approach compared to running a machine learning (ML) inference directly on edge devices:
- Computational load on edge devices is relatively low, they are just used for capturing and sending data.
- It is easy to scale up or down cloud resources based on the workload requirements by using any of the cloud services that provide autoscaling.
- A cloud environment centralizes models, software, and infrastructure, making it easy to manage deployment, model retraining, and software updates. This avoids the need of deploying models on each edge device.
Now, there are some honest disadvantages when taking this approach that are worth mentioning:
- Transmitting data to the cloud introduces latency, which may not be suitable for latency-sensitive applications.
- Continuous and reliable internet connectivity is fundamental for transmitting data to the cloud.
- To avoid data privacy concerns, we need to ensure secured connectivity between edge devices and the cloud. In an edge-computing based architecture data does not need to leave the edge devices in most cases. There are applications, for instance, where sending people’s images to the cloud is not a compliant scenario.
Deciding whether to go for a cloud-based or an edge-based solution will depend on a tradeoff between latency and costs. If the designed application admits some latency tolerance, then a cloud-based approach might be the way to go. On the other hand, switching to an edge-based architecture will ensure better latency properties, but will also escalate hardware costs, which would be prohibitive in applications with massive amounts of devices. Going for an edge-based solution will also include some additional work to coordinate deployment and model updates across all devices.
Since we want to focus on deploying production applications on the cloud, during the rest of this post we will focus on cloud-based architectures, and will break down the blocks by going into some implementation details.
Streaming video into the cloud
As we saw before, the first problem to address in a cloud-based solution is sending the real-time captured video to the cloud. Typically we will have a set of cameras recording video, and at least some basic interface between those devices and the cloud server will be needed, so that communication can be established. The simplest way to address this is to connect the cameras, for instance, to a set of Raspberry Pi boards with internet connection:
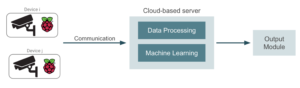
Raspberry Pi boards will be used as an interface between the cameras and the dedicated server that runs the application.
This approach might have a problem though. Think for instance of a security camera that records an almost motionless video, and raises an alert whenever some intruder is found. Most of the video frames will remain unchanged and therefore will not be worth processing. In this case, it would make sense to deploy in the Raspberry Pi a small model that detects relevant, varying frames, and send only those frames to the cloud for proper machine learning. This way, we can achieve some quite important bandwidth improvements.
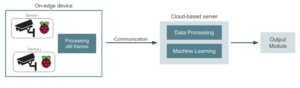
In applications that need to process frames constantly, like in an autonomous driving application, this alternative might not be suitable. Now, let’s get a little more technical and discuss a couple of alternatives to actually establish this camera-cloud environment connection:
Direct connection between cameras and server
The most direct way to send real-time data is to establish a streaming connection from the Raspberry Pi boards to the cloud. This can be achieved by setting up an RTSP (real-time streaming protocol) connection, which is possible using many open-source tools, like FFmpeg or OpenCV. The data processing module directly reads data produced in the video cameras one frame at a time. It is also relevant to ensure encryption for sensitive data in this kind of connection.
If the number of streaming devices is not that high, this alternative will be enough to handle real-time data. But if the application includes thousands of devices, we will need to set up a more robust, scalable architecture. Let’s jump into the next alternative…
Using a publisher-subscriber architecture
One alternative for more scalable applications is to make use of a stream processing platform, from which Apache Kafka is probably the most extended (but similar architectures can be designed with Apache Pulsar, Redis Streams, and many more tools).
In this solution, streaming data is structured across topics, the fundamental units of data organization and communication. Topics represent a way in which data is shared between publishers (the devices that generate the streaming data) and consumers (the applications reading and processing this data). The publishers (video cameras) send multiple information blocks to a topic, and the subscribers (the cloud server, in our case) are able to poll the information, block by block, from the topic.
To this end, we can setup a streaming cluster with multiple topics that receive streaming data from multiple video devices. The topics push data into a centralized server capable of handling high-traffic loads.
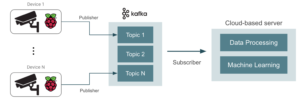
In this alternative, we need to develop, deploy and maintain a streaming application, apart from the main ML application. This could lead to increasing engineering costs that might be worth it in some applications with considerably high traffic loads.
Streaming alternatives, when should we use each one?
In a nutshell, we can consider a direct streaming connection in the following scenarios:
- Strict low latency requirements. RTSP streaming directly from the camera can provide faster real-time video access compared to a message broker, which will introduce some additional latency.
- Need for a simplified architecture with no complex data integrations.
- Small-scale streaming: when dealing with a small number of cameras or a limited data volume.
On the other hand, a publisher-subscriber based approach should be used in any of these cases:
- Large-scale data ingestion from multiple sources with high traffic volumes.
- Applications that need some level of automatic scalability. Managing a Kafka cluster for instance, will provide some autoscaling capabilities.
- Fault-tolerant applications.
Video processing into the cloud
Let’s now discuss some alternatives for the processing module. As we commented before, in a cloud-based approach, the cloud environment carries out both data processing and inference. They might be different applications, but for the sake of simplicity let’s assume only one main application handles both tasks.
This module will take the produced video and produce the machine learning output that the output module will receive. A typical solution leverages a GPU server (which can be cloud-based or even on-premise, depending on the application requirements); this server is responsible for handling all traffic from the devices and carrying out inference for each video frame.
The simplest solution is to deploy the ML application into a virtual machine instance with GPU capabilities. The server hangles the streaming traffic in a centralized way, as in the figure below:
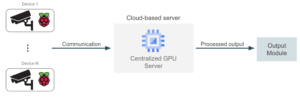
This solution, although easy to implement might be only suitable for small applications with a reduced number of devices. Having one centralized machine that handles all streaming data might mean that the instance is probably oversized. Since the server needs to support traffic peaks (which we do not usually reach in a typical scenario), this can lead to high bills. Selecting an undersized instance might also lead to bottlenecks in data processing in high-traffic moments. Also, adding new streaming devices might present some scalability issues with a centralized server.
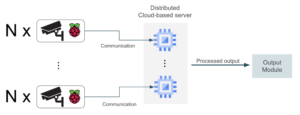
An alternative to achieve better scaling capabilities is to set up multiple smaller GPU servers that handle traffic from a subset of devices. This way, scaling the hardware is easier as the number of devices increases just by adding new small servers.
In this second alternative, load across GPUs should be reasonably distributed so that no idle resources are maintained.
Finally, the most robust solution would be to deploy a containerized ML application, and use a container orchestration platform, such as Kubernetes, to manage container deployment and scaling. With this approach we can deploy additional instances of our application based on demand, optimizing performance and costs. Additionally we can achieve better use of GPU resources due to containers being more lightweight compared to virtual machines
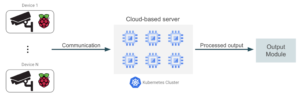
Selecting which architecture to use for the application module will mostly depend on the traffic, the possibility of increasing the number of devices over time, and also cost restrictions. The containerized orchestrated solution will usually lead to a high engineering and development cost, but will also provide the best cost optimization.
Machine learning outcome: impacting business
A well-defined streaming and processing architecture does not mean much if the output from the application cannot positively impact our business. In this section we will discuss the final and most important module of the architecture we described at the beginning. We can categorize streaming applications into two main groups:
- Applications where the output is a real-time video processing stream. Tracking specific objects or people trajectories across time, applying real-time visual effects on an input video (such as replacing backgrounds and removing objects), and automatic text translation over video, applied for instance to translating Chinese or Japanese products using a mobile camera
- Applications where the output a set of metrics that can change over time. Detecting defects in manufacturing pieces, a problem in an assembly line that triggers an alert in a control panel, tracking real-time football players statistics throughout a game, or automatically handling traffic lights based on current traffic are examples of this category.

For the first category, the output is usually a set of processed frames that show the ML inference output. In this case, we might need to set up some additional streaming architecture to handle the output; it is possible to use any of alternatives already discussed.
In the second case, the output is a signal or metric that is stored in a database or sent to an external API that handles all the downstream tasks.
On-edge vs cloud-based, is there any intermediate solution?
Well, the answer is yes. As we mentioned before, the hardware costs associated with GPU accelerators for running inference near the edge is arguably the most usual limitation for edge computing architecture.
In some applications setting up one GPU per device might be an overkill and a fog computing architecture might be suitable. Fog computing concept is related to sharing hardware resources between many edge devices. While the inference is executed in a local area network that is connected to the centralized cloud. The main goal is to bring computing resources, storage, and applications closer to where data is generated and consumed, which helps reduce latency, bandwidth usage, and reliance on centralized cloud infrastructure. The term “fog” represents the idea of a cloud that is closer to the ground or closer to the edge devices, analogous to the lower-lying clouds that touch the surface of the earth.
Some benefits of a so called architecture are:
- Proximity to edge devices, optimizing cloud bandwidth
- Hardware sharing between edge devices
- Low latency compared to a fully cloud-based solution
- Distributed architecture: each fog node communicates with other nodes and the central cloud, forming a scalable network infrastructure.
- Data privacy and security: we might need to process and store sensitive data locally within the fog network.
Selecting a cloud provider
So far we have described the high-level problem of real-time video processing to perform machine learning. In most cases, solution architects will choose to handle these architectures within a cloud-defined provider. All extended cloud vendors provide services and tools to make development easier and faster, and to centralize all application features. We will describe some alternatives in the three most extended Clouds, feel free to directly jump into any of them.
Amazon Web Services: leveraging Kinesis Data Streams
The prodigal son of streaming video apps in AWS is Kinesis Video Stream, a fully managed service that makes it easy to securely stream video from connected devices to the cloud for real-time and on-demand processing and analysis. With this approach, all video devices must be configured as Stream producers. Then, it is necessary to set up a video processing app that receives que stream output and runs all data processing and inference. It is also possible to send the model output to yet another Kinesis Stream for further processing.
Some extra features that can be implemented to improve this architecture are the following:
- A data retention policy defined within the Kinesis Video Stream to store data periodically in an S3 bucket.
- An EC2 instance hosts the video processing app. It is also possible to select an AWS Fargate instance, better for managing autoscaling automatically.
- A deployed SageMager model resulting from the training pipeline executes the inference stage. The video processing app gets predictions from SageMaker and sends them to an output Kinesis video stream.
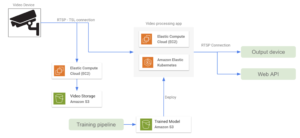
When thinking about using Kinesis Video Streams for a given application it is necessary to address its pricing scheme, which is based on the amount of data ingestion and data egress.
If pricing is a sensitive constraint in the application, another alternative would be to set up directly an RTSP connection between the video processing app and the devices, which might need some additional development compared to Kinesis Video Streams. In this case, an output device can receive the model output via an RTSP connection.
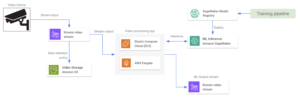
Google Cloud Platform: Pub/Sub is all you need
Google Cloud doesn’t have a specialized service for handling big amounts of streaming data, such as Amazon Video Streams. It is possible however to use Google Pub/Sub to design similar architectures. Pub/Sub is a general-purpose messaging service that enables reliable and asynchronous communication between independent applications. Pub/Sub pricing is based on the amount of throughput data.
We can configure all video devices as producers for a Pub/Sub topic, so that then push video frames into a topic. Then a hosted model running on a containerized app pulls from the topic and gets all video frames for processing.
Some add-ons that can be included in this architecture are:
- We set up a Cloud Dataflow service for storing the input streaming data in a Cloud Storage Bucket. Further model retraining pipelines can leverage this long-term storage data.
- An output device receives the model output via an RTSP connection or a web API.
- The hosted server (or Raspberry Pi board) handles all data transformation on the device’s side.
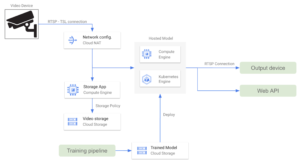
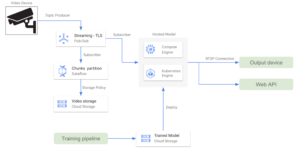
Same as in AWS alternatives, if pricing is a constraint and the least number of cloud services need to be used, we can set up a direct RTSP connection from the edge devices. Since all GCP applications run on a VPC it is necessary to configure Cloud NAT so that the internal network can receive incoming data. In this case, since we are not considering Pub/Sub, we might set up an app to store video data in Cloud Storage for retraining.
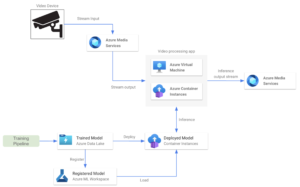
Microsoft Azure’s Media Services platform
Azure Media Services is a platform that allows users to build and deliver scalable and secure real-time video processing solutions. It offers a range of services and features for encoding, streaming, protecting, and analyzing media content across various devices. It is a general platform with many capabilities, but the most relevant ones are related to sending and receiving data through RTMP or RTSP protocols. Media Services also includes capabilities for live video processing like resizing, cropping, or adjusting the video quality. Media Services pricing is based on the number of setup streams and they are billed on a daily basis.
Architecture-wise, Media Services streams work similarly to Kinesis Video Streams. It allows the user to send real-time video from a camera device into a video processing application.
Some key features of this alternative are:
- We deploy a trained model in a hosted service such as an Azure Virtual Machine or a Container instance. This application gets the streaming from the Media Services account.
- It’s also possible to deploy the ML model in another Container Instance to run the inference step, leveraging Azure ML models and training pipelines.
- The video processing app gets predictions and sends them to an output stream.
Conclusions
In this article we outlined some basic architecture alternatives for designing an ML real-time video processing application. We described some general alternatives using Kafka Topics and RSTP connections between video devices and a video processing app. Then we evaluated what a basic implementation in each cloud provider would look like, and described some possible add-ons.
A real production-ready architecture might look quite more complex than the ones described in this post. We hope this post serve as a conversation starter when deciding how to structure an application with such streaming features.

