By Nahuel Garcia and Paola Massonnier
This article is the first of a series, in which we will be reviewing Neural Radiance Fields – most commonly known as NeRFs – the state of the art technology used for synthesizing 3D volumes.
In this first installment, we will be reviewing the “classic” approach, and state of the art results that expand on it. We’ll try to handle concepts as intuitively as possible, so that any techie with or without ML background will understand.
What can NeRFs do?
NeRfs first appeared in 2020, and they’ve already come a long way since. After all, in ML, findings of 10 years back can appear as old technology. It’s like dog years. We can consider NeRFs to be as revolutionary in 3D rendering technology as GANs were for CV in 2016. Well that might be a little bit of a stretch, but they really did propose a new perspective to rendering objects from images that has become the basic paradigm for these problems.
But really, before getting into all the specifics, we should probably take a step back to understand the complexity of this problem. Why is it hard to create a volumetric representation of an object from its images? More so, why would it be hard to create a volumetric representation, having even several consecutive images of the same object from slightly different views?
Here we strike the typical computer vision argument for everything: whereas humans can see two consecutive images and understand that they were taken at the same object and at the same time, for a computer, an image is nothing more than pixels. First of all, the computer itself can’t detect objects in an image. Secondly, even if it could, it can’t understand without any context from two images alone that one was taken consecutively from the other, and thirdly, they cannot infer that both images refer to the same object. However, if we teach them a way of following certain steps so as to interpret the data in a way they can trace a single continuous object from consecutive images, we can synthesize volumes.
NeRFs basics
The first thing we should know about NeRFs is that they define the general architecture of a neural network to train a single scene. For those who have more understanding about handling models and running inferences, NeRFs – or at least classic NerRFs – are not meant to produce a single generic model that we can then run on any set of images to render whatever we want.
NeRFs established a training architecture that we can use to train a single scene (a set of images knowing for each one the position of the camera) to visualize a 3D representation of that particular scene, this process is called view synthesis.

Key terminology
Before going any deeper there’s some specific vocabulary we should get used to when talking about NeRFs:
- A scene for us will be the object or concept that we want to render (The drums in the last figure for example).
- A view will be the rendering of a specific “view” of a scene given the camera position.
- Rendering or image synthesis is the process of generating a photorealistic or non-photorealistic image from a 2D or 3D model by means of a computer program.
- Camera position (level) refers to the height of your camera relative to the ground while camera angle refers to its angle relative to the ground.
- Volume rendering is a collection of techniques that allow you to create a 2D projection of a 3D discretely sampled dataset.
- View synthesis is the opposite of volume rendering—it involves creating a 3D view from a series of 2D images
Real-world example
To better understand the rendering process, consider a common example: have you ever seen a billboard on a construction site that illustrates how the final project would look like by the time the building is finished? This can either be done manually with photoshop, or the architect can take the building 3D plans, specify viewing angle, lighting, and other photographic specifications, and render an image from the 3D plan. That’s an application of rendering from 3D objects.
Now imagine that what we want is not to render an image from a 3D object, but to render a video from multiple views. In a way, that’s what NeRFs do: try to build a frame-to-frame smooth volume from input images into an output video – a video, because it is the easiest way to appreciate the results. “
How do you NeRF? Classic approach
“NerRFs are first introduced in the paper: NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. This is what the literature now refers to as the “classic NeRF” approach, and it’s the basics for understanding the neRFs paradigm. The authors have a website where they make available the paper, the code and – good news for data scientists – the data is free and available for anyone to download.
Conceptually, NeRFs learn to map specific spatial coordinates into an rgb value.
For this, the authors propose a method that synthesizes views of complex scenes by optimizing an underlying continuous volumetric scene function using a set of input views. To synthesize a view, they use 5D coordinates: spatial (x,y,z) and viewing direction (θ, φ) that come from the camera angle data associated with that view.
To synthesize a new view, you would need to follow these three steps:
a) march camera rays through the scene to generate a sampled set of 3D points
b) use those points and their corresponding 2D viewing directions as input to the neural network to produce an output set of colors and densities, and
c) use classical volume rendering techniques to accumulate those colors and densities into a 2D image.
Since volume rendering is naturally differentiable (d), gradient descent is used to optimize the model by minimizing the error between each observed image and the corresponding views rendered from the representation, and the only input required to optimize the representation is a set of images with known camera poses.
Minimizing the rendering error across multiple views, encourages the model to learn a more coherent representation of the scene, achieving a high fidelity in rendering novel views.
We can visualize the overall pipeline in the next figure:
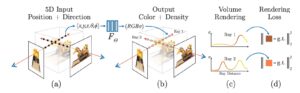
A few caveats from this approach, we have to train a new model for each new scene we want to render, it’s generally necessary to have a lot of images with coordinates data, and according to the authors, training a model can take up to two days in a NVIDIA V100 GPU.
We strongly recommend reviewing the presentation of the paper video and this one explaining the paper to further comprehend the paradigm of NeRFs intuitively.
Expansion of the NeRF field
The NeRF’s field is rapidly expanding and there are at least two different approaches to this:
- The scene-based approach (the so called “classic approach”): Requires training a new model for each new scene.
- The model-based approach: you train a model using different scenes and use it to render new (generally similar) scenes.
Here we review some state of the art research that we found very interesting and that sum up the current ways we discussed rendering scenes with NeRFs:
- NeROIC (scene-based): A NeRF variant that can be trained with images from the same object in different conditions, like different backgrounds, lighting, cameras and poses.
The only expected annotation for each image is a rough foreground segmentation and coarsely estimated camera parameters, which can be obtained using tools such as COLMAP.
The main contributions of the paper are:
- A novel, modular pipeline for inferring geometric and material properties from objects captured under varying conditions, using only sparse images, foreground masks, and coarse camera poses as additional input.
- A new multi-stage architecture where they first extract the geometry and refine the input camera parameters, and then infer the object’s material properties, which they show is robust to unrestricted inputs.
- A new method for estimating normals from neural radiance fields that enable them to better estimate material properties and relight objects than more standard alternative techniques.
- InstantNeRF (scene-based): The paper introduces a method to reduce the computational cost of training and evaluating neural graphics primitives using a multiresolution hash table of trainable feature vectors, which are optimized through stochastic gradient descent. This method allows for the use of a smaller neural network without sacrificing quality, and the architecture is simple to parallelize on modern GPUs.
This method can be used for a variety of tasks, but in particular, it provides a significant improvement over the “classic NeRF” version, allowing us to render basically any scene in up to five minutes of training.
- PixelNeRF (model-based): In this paper the authors propose an architecture that uses fully convolutional neural networks to extract features from images and learn from the scenes seen during training.
As this model doesn’t require explicit 3D supervision, the input can be 1 or many images with only the relative camera poses (which again, can be obtained with tools like COLMAP in the case of more than one image). It doesn’t require test time optimization as classic NeRF.
An interesting use case shown in the paper was the use of images taken from
3D models of cars for training purposes, but rendering scenes using only one image
from a real car with the background removed, obtaining surprising results as can be
seen in the videos on their website. A problem with this approach is that the generated scenes are very low quality, mostly 128×128 pixels.
- LOLNeRF (model-based): In this paper the authors combine two networks: a Generative Latent Optimization network (GLO) and a NeRF. A GLO network is similar to an autoencoder, and its purpose is to reconstruct a dataset from latent codes, which generally have lower dimension than the original, requiring the network to generalize by learning common structure in the data.
This combination, unlike standard NeRF, allows one to create a 3D representation of an object using a single view.
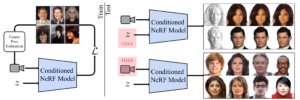
In order for NeRFs to work, the exact location of the camera in reference to the object is needed, but this isn’t always available. For this, the authors are using a model to generate landmarks (in particular they work with faces from humans, dogs and cats), and with this information they are able to extract a canonical set of 3D locations for the semantic points (landmarks).
Another interesting point from this paper is that they use two different networks for the background and the foreground, allowing the latter to concentrate on the finer details of the object.
Some final thoughts
This has been a broad overview of the different approaches to scene rendering that have appeared since the explosion of the topic in the now classic NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis paper.
As a summary on the state of the art of the field, we can say that there are pros and cons for both approaches. For the scene-based approach, the rendered scenes have really high quality in some cases. But having to train a new model for each scene is a huge limitation, and the training time is too long. Although a lot of progress has been done in this direction, it still takes a long time to generate a scene for some use cases. In the next release on this blog series, we will be covering a few tools that will help us render our own scenes with this approach. For the model-based approach, it is great that the models are able to learn from previously seen scenes and generalize to novel ones and that in some cases you can render a scene with only one image, but the quality of the rendered scenes generally isn’t very good, and you need a lot of “labeled” data from different scenes to get good results.
This is such a hot topic these days that you can expect many novel approaches to appear in the next few months. If you want to dive into the world of NeRFs, stay tuned to our blog because we will soon be covering the main problems that we encountered data-wise when setting up these models, and we will be talking about the best tools out there to accompany you in this journey.

