ChatGPT & LLMs: How to put them at work for your business
By Rodrigo Beceiro
Understanding how to use ChatGPT and LLMs
ChatGPT is causing a revolution in many industries. Many more are in the process of being disrupted and still haven’t realized that. At the same time, it is hard to know what to do about it. It is difficult to create a clear roadmap to use this technology given the extremely fast evolution of the field. A smart decision today can be outdated tomorrow.
This post looks to share some facts and advice based on our experience at Marvik so that you can avoid getting overwhelmed by your Twitter feed.
Key concepts
A few important concepts you need to be aware of to understand what is going on.
Firstly, ChatGPT is owned by OpenAI. OpenAI is a private company in which Microsoft has a huge investment, you can read more about that here. The specifics of the model used by them hasn’t been revealed and we don’t have much visibility on their product or commercial roadmap.
Large language models or LLMs are part of the Natural Language Processing (NLP) field. These are huge models (measured by the billions of parameters they have) focused on solving language problems. You shouldn’t care about the billions of parameters but only remember that, the more they have, the better the models are usually and more expensive they are to train and use in production because of the hardware they need.
Generative AI is another field that has evolved fast in the last few months which focuses on the generation of things by the AI models. Those things can be text (for example ChatGPT), images (for example Midjourney), videos, audio, etc.
ChatGPT resides in the intersection of LLMs and Generative AI but there are generative models that don’t generate text and LLMs that focus on other tasks that are not text generation. Neither of these fields are new and there are companies (such as us 🙂 ) that have been working on them for years, they only got more attention lately. We can thank OpenAI & ChatGPT because without their incredible progress this wouldn’t have been possible, and it’s enabling many applications and speeding up the adoption.
Concerns & blockers
If you want to use ChatGPT for your business you are most likely struggling with how to resolve two huge issues:
- Privacy: OpenAI needs to receive data from you as input so it can produce the outputs they generate. There is no way of avoiding sending them information although we explore workarounds for this.
- Accuracy: ChatGPT doesn’t know the specifics of your business and more broadly generative models are trained to generate coherent things which are not always accurate. It can get important facts wrong which can have a huge impact on your customers or internal processes.
If you want to get more technical, when you train these models there is a tradeoff between generalization and memorization. Let’s suppose you train a model to answer questions about your store’s products. You train them with the data you have at the moment and you would like it to be able to answer questions about products that have not yet been added to your catalog or stock. If you let the models generalize and talk about stuff you still don’t have in your catalog during training, then they need to make things up. If you teach the model to be accurate, it can only do so by memorizing your entire catalog. You need a little bit of both, you need to avoid getting too much of either. The exact point where you stand on this tradeoff is part of the engineering work that you need to do when developing these systems.
Using ChatGPT and LLMs
Alternatives are:
- To use ChatGPT with masked information: your business might not have strong restrictions in terms of privacy of the information or the accuracy of the prompts being returned to the users. You are one of the lucky ones
- To use your own Generative or LLM model: you might have heard about Llama from Meta’s AI team, Vicuna which can be found in HuggingFace and many other models with camelid names for some reason. These models have been open sourced for the community to train ChatGPT alternatives. These models are part of what is called LLMs and can be trained for multiple tasks. The advantage is that you can own the model, therefore eliminating any privacy concerns and also teaching the models about your specific domain or company which if done correctly can improve accuracy. Open source datasets facilitate this task which reduces restrictions of needing huge volumes of information to train. This open source data usually gets combined with your own data so it can also learn domain specific information.
- To use both of the above and merge the result: where you use the best of ChatGPT and its advances and combine that with your own models or more sophisticated pipeline. Complex pipelines can require different generative stages where ChatGPT can be complemented with a model you train to specialize in a specific topic.
An important disclaimer is that ChatGPT’s training has cost millions of dollars, was trained on huge volumes of information and is the model, which is notoriously better than almost anything else out there at the moment, has not been open sourced. The community is looking to replicate what OpenAI’s team is doing, but they still have a technological advantage on a general domain. This means that ChatGPT can be better in solving many problems, but not necessarily better at solving your problem. You can provide it with limited context, that might or not be enough for your application.
Getting into the technical details
Systems like these need to be designed on a case by case basis but what a production ready pipeline can look like is seen next.
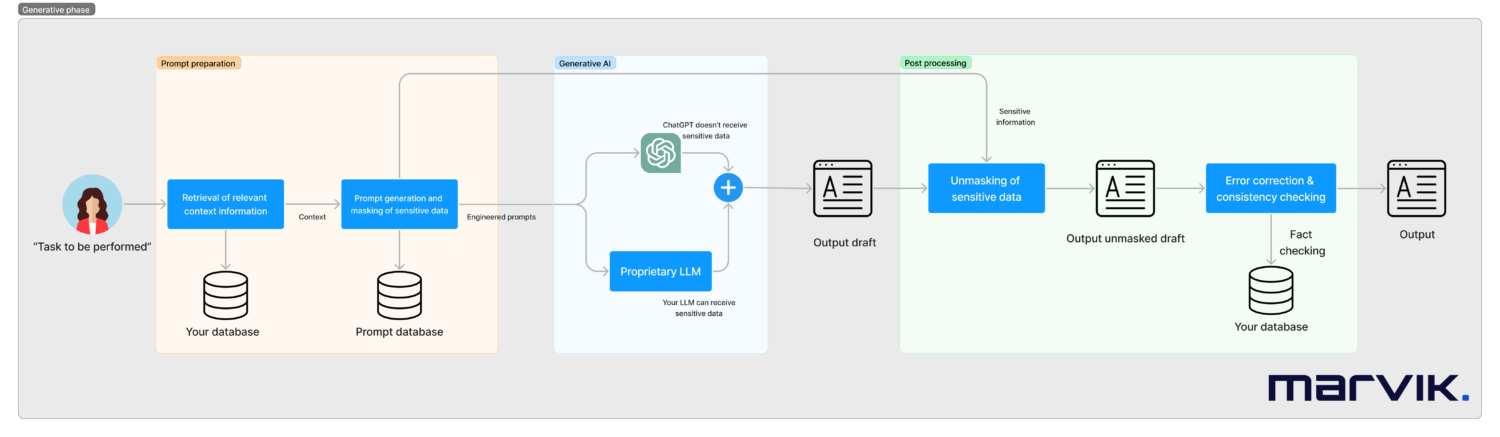
In this workflow, we will:
- Start with a task to be performed (can be triggered by a human or automatically such as an incoming email). Lets work with an example of a customer support case of a financial institution
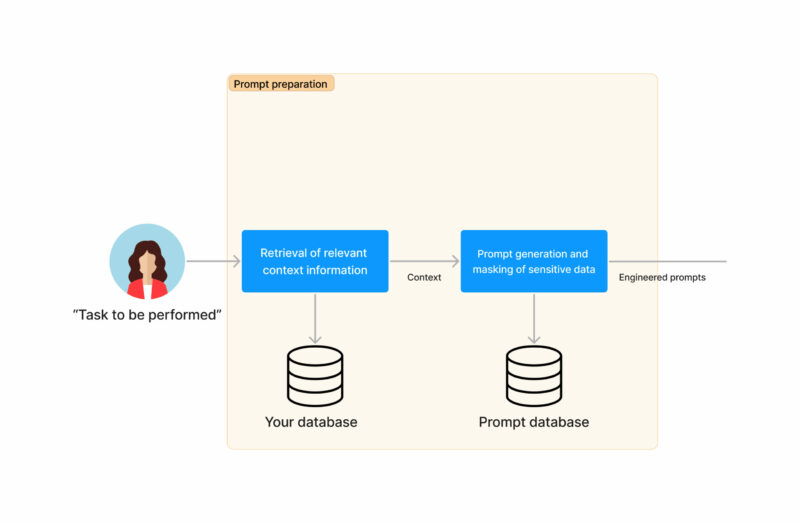
- We will retrieve any relevant context information needed to answer the task. In the example this can be the credit card balance
- We will move on to a phase of preparing the prompts for the generative models. This will be the result of a prompt engineering work done once during the implementation of the system.
- We can also mask any sensitive data if needed at this moment, for example the customer’s name or account balance. Oversimplifying the masking, this can be replacing a balance of $100 for balance of X. This is more complex than that as there are relationships that need to be preserved (if you are trying to purchase an item for $200 it is not the same if your balance is $100 or $300).
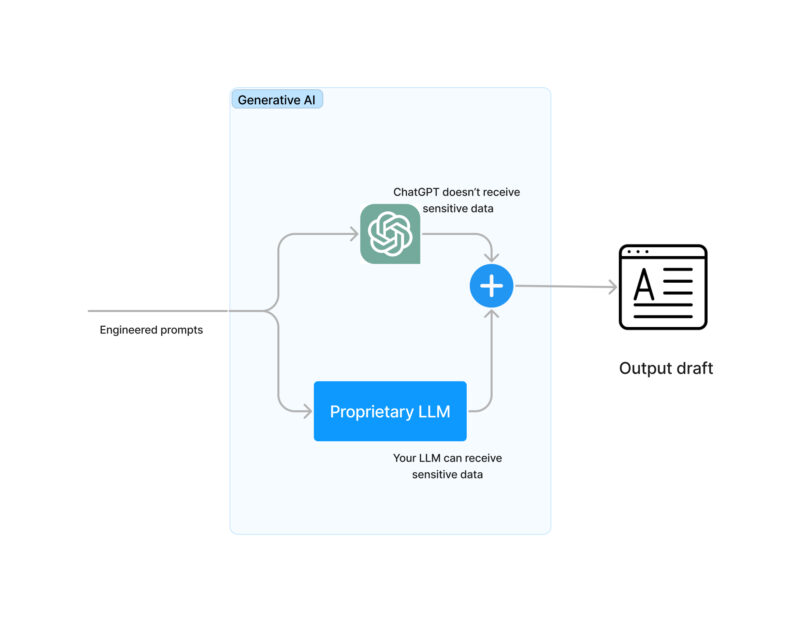
- Prompts will be automatically done to the generative model(s). Alternatives are:
- To use ChatGPT with masked information
- To use your own Generative or LLM model
- To use both of the above and merge the result
- At this moment we need to unmask the sensitive information we had masked before. This is, reverting the balance of X for a balance of $100.
- Do the actual text generation using AI. It can be done using ChatGPT or your own LLM model.
- Now that you have a viable answer, you need to check that you are not saying any inconsistencies. At this moment you put in place error correction and contingency strategies for your data. For example, part of the answer could be “If you have any questions call us at 555-1234 from 8am to 5pm”. That phone number and open hours better be real. This can be very troublesome in some domains, such as e-commerce where you can’t sell an Iphone that has 350 GB, it’s 256GB or 512GB and a generative model can easily get that wrong.
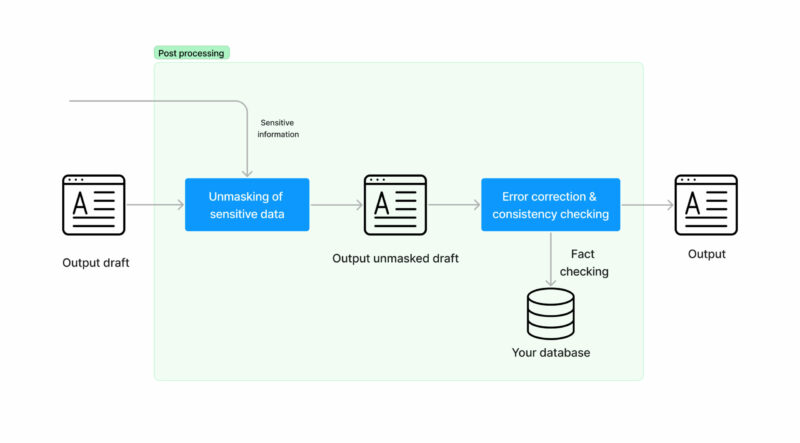
- We are done! Now you have an automatically generated answer for an inbound task that you can share with your users. The facts are checked so there are no inconsistencies and no sensitive data has been shared with third parties.
- Are we done? In specific domains, it is usual for humans to re-prompt. This could be done by a customer support agent working as a human in the loop. If needed, instructions can be given to our models to iterate over the answers.
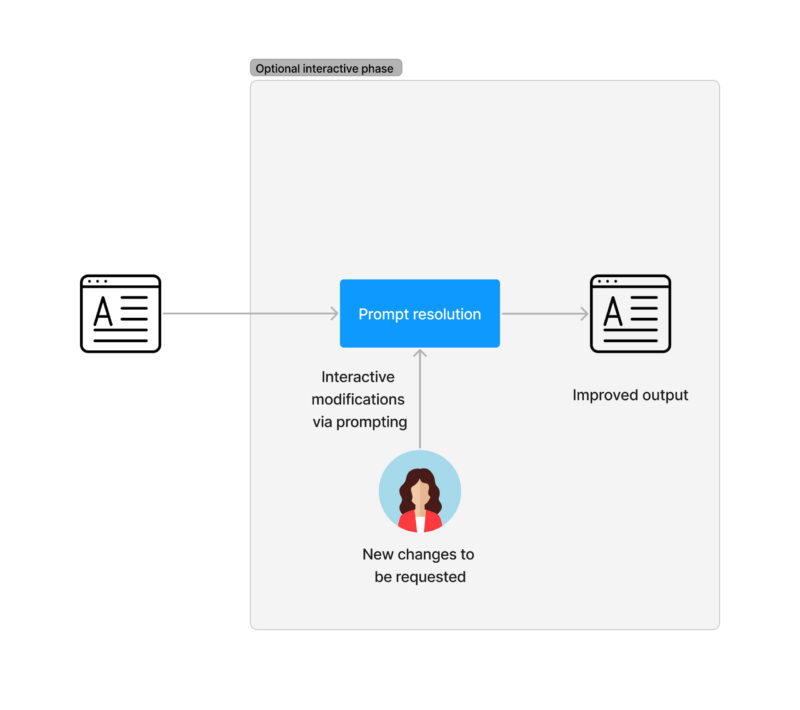
A few important comments if you are considering to really use this:
- ChatGPT is great, and you can leverage any new improved models they release if you use their API. Keep in mind that you will need to define prompts to interact with ChatGPT, you will optimize them to get the best results. If ChatGPT releases an improved model, you are prone to need maintenance.
- Understand the limits of ChatGPT data usage policies. Latest version at this time can be found in https://openai.com/policies/api-data-usage-policies. It basically says: they retain your data for 30 days and if you like they don’t use it to re-train their models. This only applies to the API, not the web interface. All data is processed and stored only in the US at this time.
- Quality of ChatGPT versus your own LLM: You can expect the quality of ChatGPT to be better but not as specific. It needs a huge investment to be the best out there and they have done so, but you might be impressed by the quality of the LLMs you can train (huge thanks to the AI open source community for this). ChatGPT is for example using reinforcement learning which most models aren’t (we are still trying to reverse engineer exactly how they are using that)
- Having worked with generative models in multiple domains at large scales for a few years now, we strongly recommend not to underestimate the importance of the error correction and contingencies needed to check the quality of the generation.
Getting the timing right
You might be scared of getting into a costly development project training your own LLMs when OpenAI or some other company might release a new improved model in the future, or change its privacy policies and your solution might be outdated fast. This is a completely valid point but just a few thoughts on that:
- Reality might change, but it also might not, and if it doesn’t then you are wasting valuable time that your competitors might not be losing
- It is more likely that the community releases an improved LLM or open sources a new dataset that makes it smarter to train a new model and just replace that block in our diagram than OpenAI changes its privacy policies and this becomes an unnecessary investment. The rationale behind this is that:
- This is a fast moving field and the community is catching up really quick with the state of the art
- It doesn’t seem like the smartest move from OpenAI to release its models where they can be reverse engineered while they have a technological advantage
- If new models are released, you will most likely be able to reuse any training preparation that you did already, and the update cost and time will be significantly reduced.
- Even if the generative part of the system needs an update in the future (ChatGPT or your own LLM), it is very likely that the rest of the system will be needed for any task you will like to solve at scale.
Final thoughts
We have seen a huge step up in the game. This is thanks to even larger volumes of information that now we can train on, larger and more sophisticated models and enormous computing power for training. While all of the above are crucial, also part of this evolution is derived from the change in focus of the training of these models that are now trying to resolve more complex tasks. To put it simply, in the past we used to train chatbots to classify a user’s intent and created the response with a fairly fixed rule. We trained the models for accuracy in the classification. Now we train them with the goal of having a realistic human-like conversation. They sound smarter at the tradeoff of not getting the facts right. Getting the conversation and the facts right at the same time is still on the verge of the state of the art.
Many businesses will be disrupted. We are still in the middle of the revolution so it is hard to predict how the landscape will end up looking like. For example, I’m looking forward to the advances we will get in the robotics field really soon. Despite this, there is no better time to work on this than now, tomorrow might be late. As Bill Gates said, the era of AI has begun.
Read more about this in our web: https://www.marvik.ai/areas/large-language-models

