Product Search: Finding few needles in a haystack
By Ignacio Aristimuño and Carolina Allende
Introduction
Have you ever wondered how fast you can show your friends that stunning sofa you just bought without saving the link to the post beforehand? And what about how you found that particular sofa from a wide variety of sofas you didn’t know even existed? That’s Product Search coming into play.
Product Search is a use case within Search Engines. These engines allow us to type a query in natural language, and carry out the heavy lifting for us, looking among millions and even billions of possible results, and select those which are more relevant to our search query. But how do these search engines sweep through many possible results in near real-time and still get relevant results? How do they even identify relevance? We’re addressing these problems and more throughout this blog, first from a high-level perspective, and then going deeper into more technical details.
What are Search Engines?
Search engines vs Recommender systems
When we look for certain products, generally two types of results can be found. One can be related to the product itself, say you want to buy a new cellphone so you type the query “iPhone 12”. Then, the most relevant results could be different variations of iPhone 12, in terms of memory capacity, color, and other factors. However, other results may come out as well, such as iPhone 12 cases and tempered glass for protecting your phone. These are other types of results, more related to recommendations rather than the product search itself. The former problem is being handled by Product Search Engines, while the latter by Recommender Systems.
At first glance, the difference between a Search Engine and a Recommender System (RecSys) can be a little bit blurry, however they serve different purposes. Recommendation Systems or Recommender Systems, make suggestions related to each user’s search history by building customer profiles and storing relevant metadata, by either comparing items based on previous experiences (content-based filtering), by using information from other users with similar online behavior (collaborative filtering), or a hybrid approach involving these two.
Recommender Systems tend to focus on solving problems such as:
- Data sparsity: in order to have an effective system you usually need to have a large number of users interacting with the website. These people could have a large influence on how the recommender engine works.
- Big Data: usually, websites that use RecSys have to deal with huge amounts of data, including items’ data, users’ data, metadata, and more.
- Cold-start: if a new user or a totally different product from the rest enters this sea of information, it’s impossible to associate its information to other related entities. Also, depending on the retailer, it can take months to accumulate enough behavior data to start building a custom RecSys, hence this cold-start problem.
Search Engines tend to focus on solving problems such as:
- Efficient indexing: used to quickly locate data without having to sweep through every row in a database table every time the table is accessed.
- Attribute ranking rules: ranking results by their expected relevance to each user’s query, using a combination of query-dependent and query-independent methods.
- Data cleaning: from the user’s query, retrieve the most important information, disregarding those words that don’t add value to the query’s intention or semantic meaning itself. Some techniques such as stop word removal, and stripping accents and special characters comes in quite handy.
- Fuzzy matching: approximate string matches (e.g. “iphone” vs “ihpone”). There are several techniques to handle this issue, while the most common could be using Levensthein’s distance.
- Non-fuzzy matching: to capture words that usually refer to similar concepts but are not written almost exactly the same. These techniques include: stemming, lemmatization, and tokenization.
In short, while search engines help users find what they want, recommendation systems help users find more of what they like or relevant alternatives. Nevertheless, search engines are tending to adopt a certain degree of recommendation among their results, so it’s not uncommon for users to see both search results mixed with recommendations.
Let’s look at an example for further clarity:

SEARCH RESULTS



In this case, we can observe that all three dining tables are black Northern dining tables, where the two first could be the same product but with different images taken and the third table is rectangular instead of rounded.
RECOMMENDER RESULTS


Here we can see chairs and decorations that make sense given the search. In other words, we correctly understand what the user is looking for and think of new items that might make sense to consider buying at the same time, whereas in the search results we only focus on what the person is looking for.
Search engines use cases
We use search engines on a daily basis. From those podcasts you listen to while waking up, to that Netflix series your best friend has been recommending for months and you looked it up to finally start watching. Let’s dive in into some real-life examples of search engines we usually interact with.
This one hardly needs any introduction, with over 86% of the search market share Google had to be top tier in the list. Google search is split in three phases, two of which happen long before a search query is run:
- Crawling: The first stage is finding out what pages exist on the web. Since there isn’t a register of all web pages, the first step is to find out which webs exist. Once Google discovers a new page, it may “crawl” it to retrieve the relevant information and find out what’s on it.
- Indexing: The second stage is to save all this information, to “index” it, so as to be able to swiftly find it.
- Serving search results: The final stage is to search for indices whose content matches and return the results which are considered of higher quality and most relevant to the user. Relevancy is determined by hundreds of factors, including the user’s location, language, and device (desktop or phone). As an example, searching for “bicycle repair shops” would show different results to a user in Buenos Aires and a user in Montevideo.
YouTube
Despite some misconceptions about YouTube’s algorithms, they do not use images and videos for search, only text and code. This is due to a simple reason: videos are collections of images stacked sequentially, and images are way more computationally and time expensive to process than text. Adding this up to the volume of videos in the platform, it’s nearly impossible to achieve good results for near real-life applications by analyzing videos. However, there are several sources that this search engine takes into account for ranking results: titles, tags, descriptions, captions, among others.
Amazon
When it comes to online shopping, product search at Amazon is the undisputed winner; even in comparison to Google. About 61% of US consumers begin their product hunt on Amazon, nearly 45% on a search engine like Google (and others), and 32% on Walmart. Also, when looking for products at a search engine, Amazon usually appears in the top recommended search results.
What data does Amazon use within its search engines? Some of the variables used are: keywords, impressions on the product, sales, Click-through rate (CTR), conversion rate and customer reviews, among others.
Other honorable mentions
Some other well known companies that use search engines which we interact on a daily basis are:
- Facebook: when looking for a friend, group and even at Marketplace.
- Linkedin: mainly for searching among hundreds of millions of candidates.
- Baidu: is the most used search engine in China, with great investments on AI for different purposes.
- Pinterest: this platform was built in order to discover a wide range of content which focuses on aesthetics, from ideas (cooking recipes, home deco, etc) to products.
Main concepts and challenges
Let’s recall the aim of the search engine algorithm: to present a relevant set of high-quality search results in order to fulfill the users’ queries as quickly as possible.
Query intent
Query intent answers to the question: what is the intention of the user for making this query? These intentions can be broadly grouped into four categories:
- Exact queries (navigational): these occur when the user knows which product wants to reach, and uses the search query as a means to find the desired product.
“Refrigerator Samsung Frost Free RF27T5501SG Inverter”
- Domain queries (informative): these occur when the user wants to inform itself about different products that are grouped within a certain domain, or group of products. The goal is not to buy, although this could happen, but to acquire knowledge of the options available.
“Interior plants”
- Symptomatic queries: these happen when the user has a problem he/she/they want to solve, but has no clear knowledge of which product can solve the problem.
“Stained rug”
- Thematic queries: these queries are often difficult to define as they are inherently vague in nature and some include some fuzzy boundaries, making reference to locations, seasonal or environmental conditions, special or promotional events, among others.
“Halloween plastic cups”
Main challenges
Some of the main challenges to be aware of while dealing with Product Search Engines are:
- Speed: the results are usually shown between 0.5 and 3 seconds while the webpage loads.
- Sparsity: there are many products to compare with, hence the use of pre-filtering and indexing to compare the query with the most relevant ones.
- Language: queries may be or may contain words from different languages. Having multilingual capabilities could be desirable, even more if the website attracts users from different countries.
- Units of Measurement: when a user searches for a hair product with 0.7 L of volume, the Search Engine must associate that 700 mL refers to the same value of the same magnitude.Robustness towards spelling: this could include:
-
- Orthographical errors: “pomegranade” instead of “pomegranate”.
- Typing errors: by swapping letters or mistyping letters that are close to each other on the keyboard. E.g: “blakc sofa” or “floor lanp”.
- Synonyms: “circular inflatable pool” and “rounded inflatable pool”
- Morphological variations: “red” and “redish”
-
- Language-dependent difficulties: there are also some additional difficulties that can be found depending on the languages we are working with. For example, in German, it’s common to stack many words together for creating a new word (compound words) and this could potentially lead to some issues.
Nice to have
It could be also desirable to:
- Understand each user’s way of writing, in order to understand better the intent and relevant content from their queries.
- Capture phonetically similar words: “bluetooth” and “blututh”.
- Have certain interpretability of results in order to detect where’s room from improvement on further iterations of the search engine.
- Seasonality approaches, using trends on which products are most likely to be searched given the season of the year.
How do Product Search Engines work?
In this section we’ll get more technical to look at a deeper level how these solutions are designed. As products have to be shown in a certain order, this introduces the notion of ranking, meaning sorting documents (in this case, products) by relevance to find contents of interest with respect to the user’s query. This is a fundamental problem in the field of Information Retrieval.
Ranking models typically work by predicting a relevance score (s) for each input (x), where the input depends on a query (q) and a document (d).
![]()
Once we have the relevance of each document, we can sort (i.e. rank) the documents according to these scores, for showing up the most relevant results first. The scoring model can be implemented using various approaches, but two of the most popular are:
- Learning to Rank (LTR): using a Machine Learning algorithm such as XGBoost, where the model learns to predict the association score given a query and a document, learning to minimize certain loss which will be introduced shortly.
- Vector Space Models: these models compute a vector embedding (e.g. using TF-IDF, Word2Vec or BERT) for each query and document, and then compute the relevance score with some distance metric between the vector embeddings, as the cosine similarity.
Data Cleaning
Previous to using any kind of model, it’s desirable to do some data cleaning and use some text pre-processing as the queries are written by users, which tend to have typos, orthographical errors, and other kinds of noise to the model. This is why many papers recommend to do some cleaning including:
- Basic text pre-processing: convert text to lowercase, get rid of accentuations as hyphens in Spanish, remove trailing whitespaces, special characters, among other transformations. In this regard, Unidecode can be extremely useful.
- Stemming/Lemmatization: these techniques can be used for making variations of the same root word, to be converted to the same exact written word, which can help the algorithm while training to associate these words as they have semantic similar meanings. One of our favorite tools for these sorts of tasks is spaCy.
- Stopword removal: in some cases it can be useful to remove words that do not add value to the semantic intent of the query. Once again, spaCy can help with this task.
- Units of Measure standardization: in eCommerce in particular, it’s quite common to have diverse units of measure and possible conversions. This could also be detrimental to the learning capabilities of models, hence the necessity of a good preprocessing by standardizing them. Libraries such as Pint and Quantulum3 comes in handy for this step.
Learning to Rank
Keeping in mind that we for product search, our documents (d) represent products and the queries (q) are the search query written by the user, the most common approaches for training a LTR model are:
- Pointwise methods: where the supervised learning problem is seen as a regression problem, where for each query-document pair, there is a float type label representing how similar are the query and the document, and the model tries to learn these patterns in the data. There are also discrete versions of the Pointwise methods where similarity is discretized between a certain range, e.g: from 1 to 10.
![]()
- Pairwise methods: although the regression task can be seen as the most intuitive, is mostly unlikely to have data labeled for that way of training. Therefore, another approach is, given two products (d1 and d2), determine which product is more similar to the query.
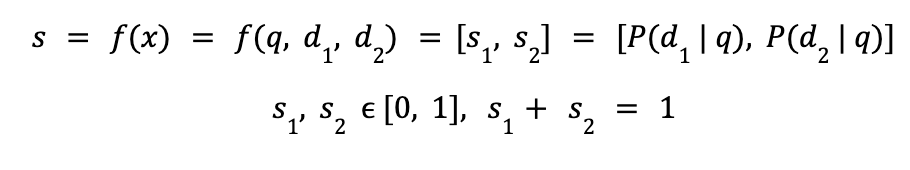
- Listwise methods: in these methods, instead of transforming the ranking problem into a regression or classification task, Listwise methods solve the problem more directly by maximizing the evaluation metric.
Vector Space Models
These approaches are both traditional statistical methods such as TF-IDF, or depend on training a Machine Learning model on an auxiliary task for learning a desirable representation of both queries and documents in a vector space. Usually this auxiliary task is a classification task, but removing the last classification layer (or even some more), the model can convert the inputs on these handy representations of data, called embeddings.
Word2Vec
The effectiveness of Word2Vec comes from its ability to group together vectors of similar words. This is based on a hypothesis that each word in a phrase is conditioned by the words in their surroundings (context). There are two main ways to train Word2Vec, but let’s look at the most intuitive: Continuous Bag of Words (CBOW).
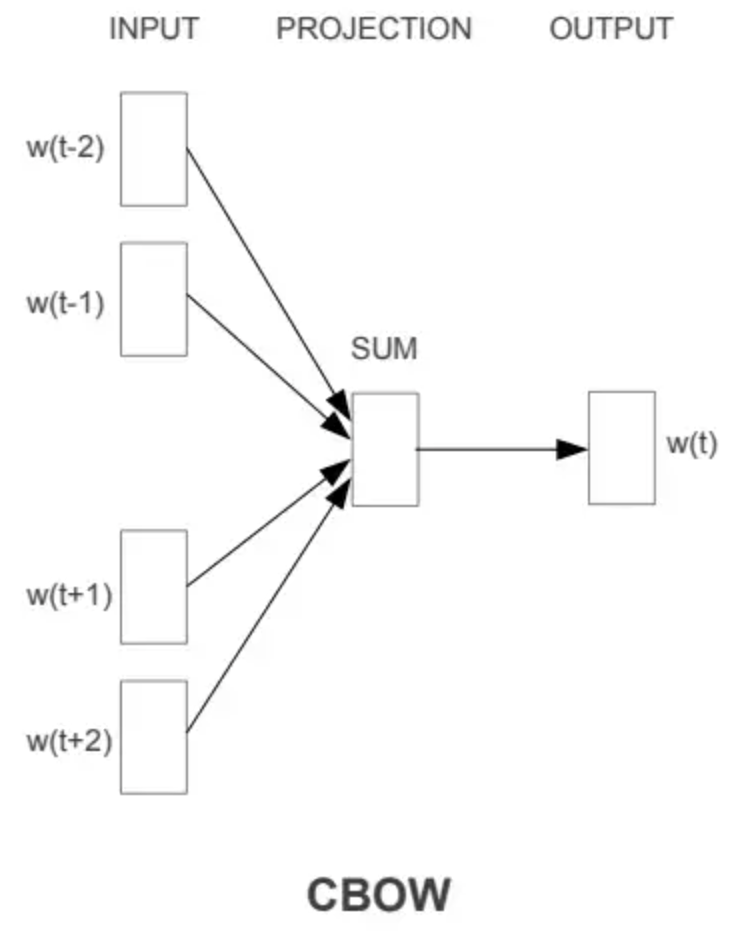
CBOW Architecture, taken from the Word2Vec paper
In the picture above, the input is a phrase with five words, where the word middle is not given to the model, and the model’s goal is to predict which word should be in the middle of that phrase. These inherently, makes the parameters learn the frequencies and correlations between words that are commonly used together in phrases, and the vector that represent each word have some desirable semantic and syntactic properties as the shown below:
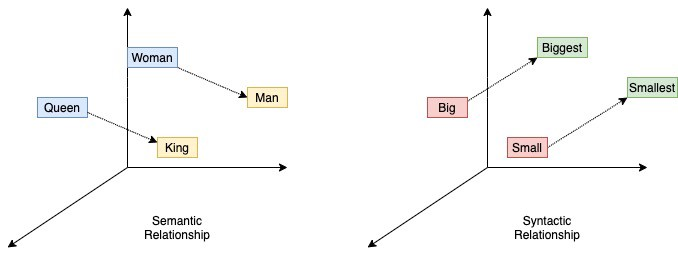
Word embeddings semantic and syntactic relations
Then, with these representations, we can create embeddings for each word and use some heuristics to define an embedding for the whole query or product. Then comparing these embeddings to determine the ranking to be shown.
Encoders
We have mentioned BERT as it is one of the most used encoder transformer architectures, but any encoder could serve the same purpose. The idea behind this is using BERT as the backbone of the architecture, and then add a classification or regression head for training the model as referred in the POintwise and Pairwise methods.
Let’s look at an example of the architecture:
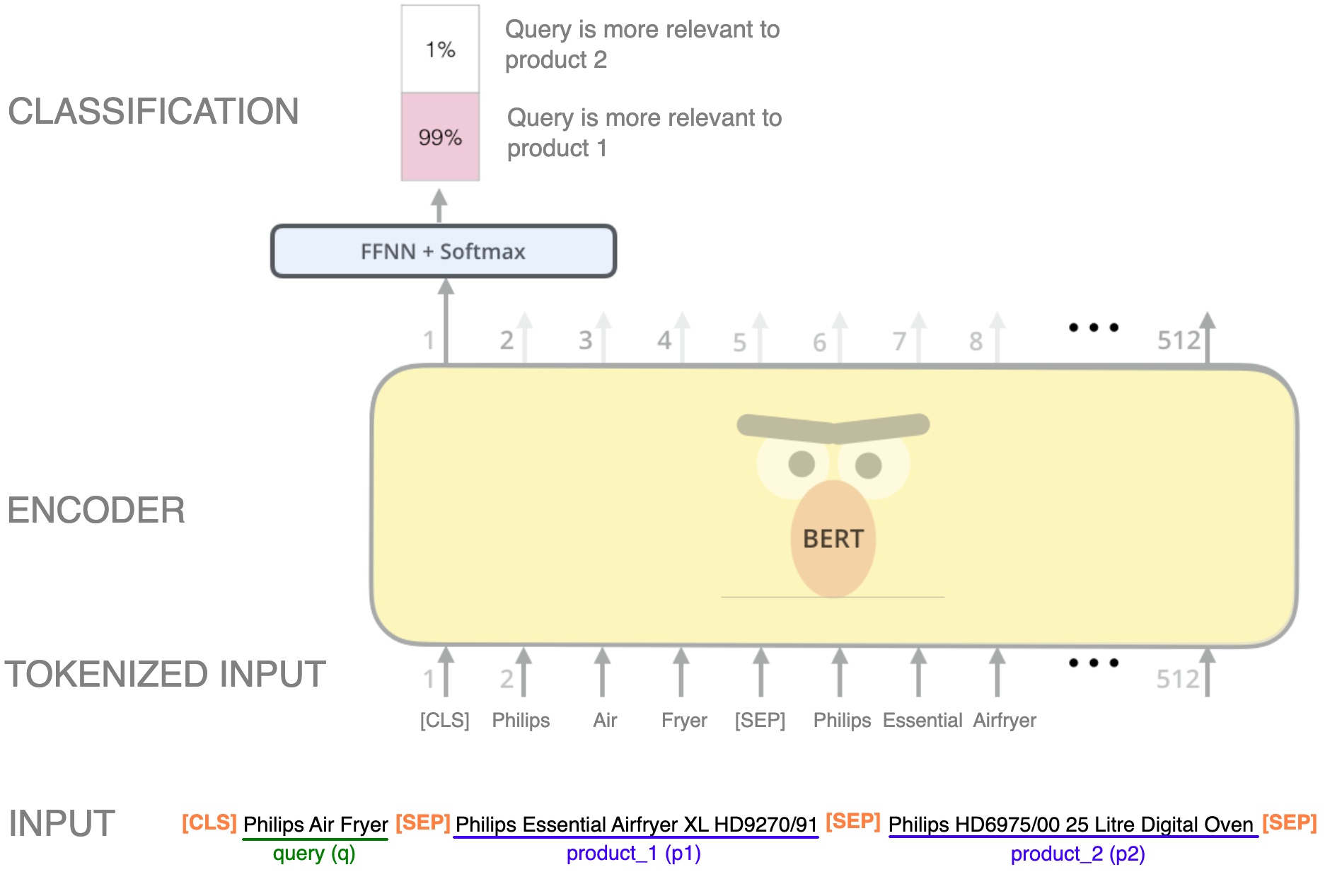
Image modified from Jay’s Alammar blog on BERT.
In this example, we use a pairwise approach for classifying whether the query is more relevant to product 1 or to product 2. To achieve this, a possible is to train the model using a similar structure as the Next Sentence Prediction (NSP) which is one of the ways BERT is pretrained, but with three phrases: the query, product 1 and product 2, each separated by the special separation token [SEP].
Transformers are usually avoided due to being heavy models with millions of parameters. But in some cases, with just reducing the number of encoder layers within its architecture, good results can be achieved and the sequentiality which takes more time and resources, is reduced. The paper which introduced the transformers architecture, “Attention is all you need“, uses 6 stacked encoder layers for the encoder block, but with 1 or 2 layers could be enough for this purpose. An example of this can be seen in the paper titled “Behavior Sequence Transformer for E-commerce Recommendation in Alibaba“ by Alibaba’s Alibaba Search & Recommendation Group. Although this paper refers to a Recommender System, the same concepts can be applied to Search Engines.
However, as in the example the products have to be given as input in pairs, at the moment of using the inference of the model, these two products should be given as well. Other options are using this training as a pretraining and fine tuning the encoder on another downstream task, or just using the encoder without the classification head as we did with Word2Vec. By using this type of input, the number of comparisons may grow exponentially, therefore, this model could be used only when the more relevant products are retrieved first, say a few hundred products for a detailed comparison.
Similarly to Word2Vec, then the last classification layer with the Softmax activation functión can be removed for obtaining queries and documents’ embeddings instead.
Relevant Literature
The following is a selected list of papers that were found of interest for researching viable Product Search solutions that could both be scalable in millions and even billions of catalog products, and still have great performance.
Semantic Product Search
In this paper, the relevance of products given a search query was modeled as a regression problem using a Siamese Network:
- The authors use Bag-of-Words (BoW) shared along the queries and products, for then creating a shared embedding space with average pooling. This is the base for training the Siamese Network with cosine similarity.
- A 3-part Hinge Loss is used to distinguish between bought products, not-bought clicked products and not clicked products. In a first instance, they tried out a 2-part Hinge Loss with clicked and not clicked products, but the purchase information gave an extremely useful insight for the model to pivot on.
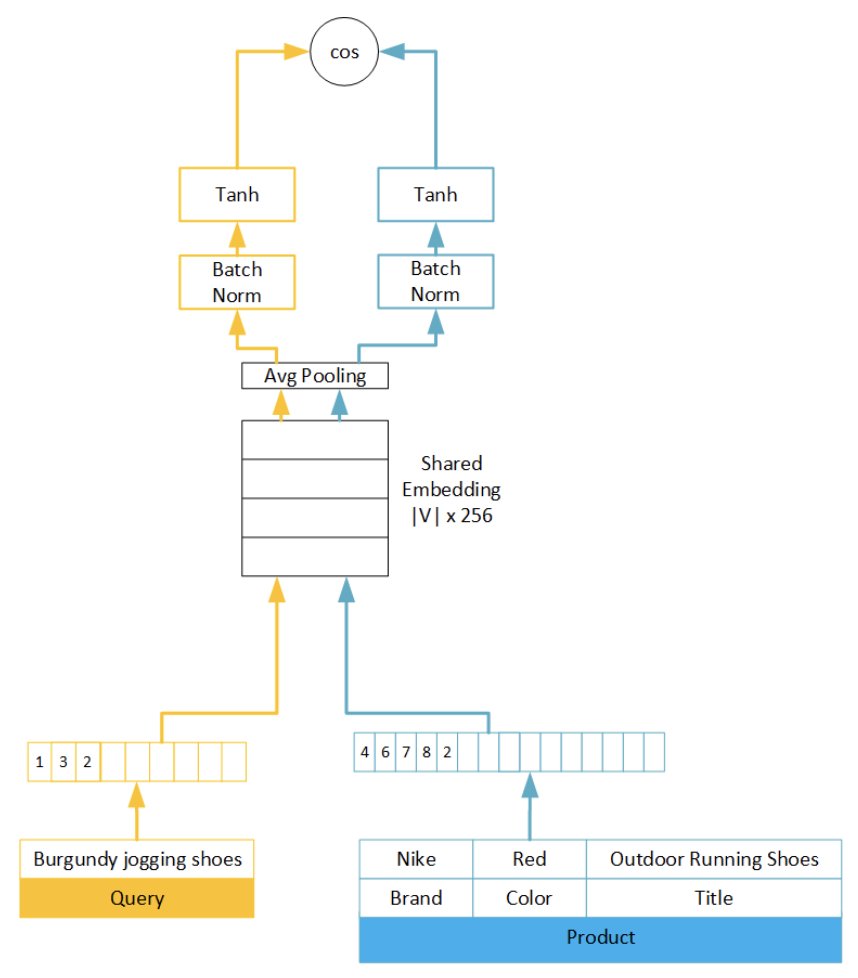
Image taken from the Semantic Product Search paper
Seasonal Relevance in E-Commerce Search
This paper focuses on the idea that many products have inherently a seasonal component on their sales. This leads to queries that possibly align with these temporal trends, so it’s more likely for a user to search for a winter sweater at the beginning of winter rather than in Summer.
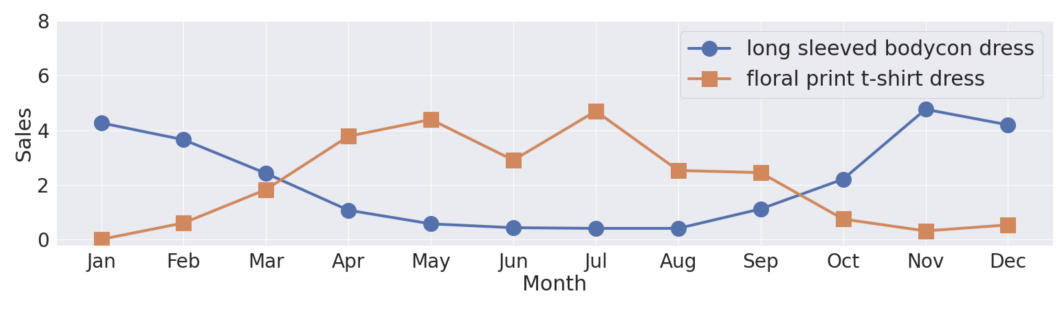
Image taken from the Seasonal Relevance in E-Commerce Search paper
Highlights:
- The authors show that the 39% of queries made by users align with these seasonality components of the products.
- Hence the idea of proposing seasonality features to being used in the search algorithms.
- They propose a simple Feed-Forward multiclass classification Network with stacked attention mechanisms, which takes only the input query as input to the network, creating embeddings with Fasttext, and adding a seasonality term to the categorical cross entropy loss.
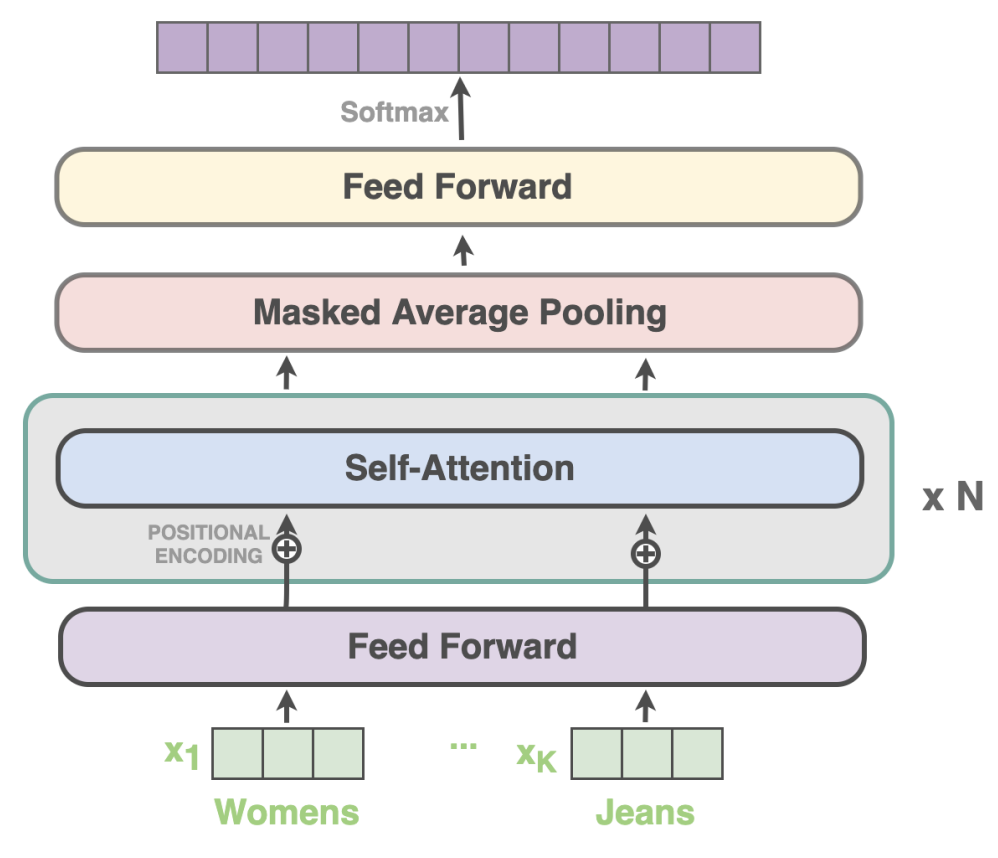
Image taken from the Spelling Correction using Phonetics in E-commerce Search paper
ROSE: Robust Caches for Amazon Product Search
This paper is a bit different from the rest as it’s not centered around the design of the model, but on how to improve user experience with the use of smart caches robust to typos, misspellings and similar phenomena (low quality queries) for lower latency when users search.
Highlights:
- This cache system is currently in production for Amazon.
- The authors propose mapping low-quality queries to high-quality queries, keeping only high-quality queries in caché. For indexing and capting the semantic similarity for these queries, a Locality Sensitive Hashing (LSH) is being held, as proposed by the Approximate Nearest Neighbours (ANN) approach.
- Some words such as product attributes are weighted greater than other words to keep this semantic similarity, using Named Entity Recognition (NER) techniques.
Spelling Correction using Phonetics in E-commerce Search
In this paper, authors talk about the reality that most solutions involving search engines are centered around the noisy text queries the users type, but do not take into account phonetic errors. For example, when an old couple tries to find out the headphones with “blutut” their granddaughter wanted for christmas.
Highlights:
- Issues with text can be solved with edit distance, n-grams or even word embeddings, but phonetic errors are quite more difficult to tackle.
- Similarly to the Levenshtein distance for words textual similarity, the authors propose the use of word sound distance, such as Soundex.
- They propose using a tree-based model, such as XGBoost, for correcting the typed query taking into account both distances (textual and sound) with an efficient candidate search algorithm.
For example:
Without phonetic similarity: the query “blutut sant systam” got 82 results, correcting it to “blututh sent system”
Adding phonetic similarity: the query “blutut sant systam” got over 9000 results, correcting it to “bluetooth sound system”
Final thoughts
That was a lot of information to take in! But we hope that with this blog you were able to grasp on a higher level, the key concepts around Product Search, the differences between Search Engines and Recommender Systems and the main aspects and challenges to consider when building a Product Search Engine.
If you were interested enough to continue with the more technical details about the State-of-the-Art on Product Search, we hope this blog gave you some insights on what decisions have to be made to build a scalable and performant search engine, along with some ideas of where can we start to try while modeling these solutions.
Stay tuned for more content!
References
- Alexander Reelsen, “A Modern E-Commerce Search” (June 2020). https://spinscale.de/posts/2020-06-22-implementing-a-modern-ecommerce-search.html
- Baymard Institute, “Deconstructing E-Commerce Search UX: The 8 Most Common Search Query Types (42% of Sites Have Issues)” (July 2022). https://baymard.com/blog/ecommerce-search-query-types
- Francesco Casalegno, “Learning to Rank: A Complete Guide to Ranking using Machine Learning” (February 2022). https://towardsdatascience.com/learning-to-rank-a-complete-guide-to-ranking-using-machine-learning-4c9688d370d4
- Google Search Central, “In-depth guide to how Google Search works” (October 2022). https://developers.google.com/search/docs/fundamentals/how-search-works
- Loop 54, “The difference between product search engines and product recommendations engines” (October 2016). https://www.loop54.com/knowledge-base/product-search-engines-product-recommendation-engines-differences
- Mangool, “Search Engines” (January 2021). https://mangools.com/blog/search-engines
- Pinterest, “All about Pinterest” (July 2022). https://help.pinterest.com/en/guide/all-about-pinterest#
- Search Engine Journal, “Meet the 7 Most Popular Search Engines in the World” (March 2021). https://www.searchenginejournal.com/seo-guide/meet-search-engines
- Telus, “What are search engines in Machine Learning?” (February 2021). https://www.telusinternational.com/articles/what-are-search-recommendation-systems-in-machine-learning#
- Webinterpret, “Understand the Amazon search engine to drive more sales” (August 2022). https://www.webinterpret.com/us/blog/ecommerce-product-searches-amazon-google/

