NVIDIA-Merlin: A framework for building recommender-systems
By Eric Spiguel
Over the last years recommender systems gained huge popularity in the machine learning and data science community due to their impact in digital and e-commerce platforms revenues by suggesting specific items to customers that would be interesting in them. Nevertheless, when building recommender systems a wide range of obstacles are encountered. To address those challenges, a large variety of tools are being developed to minimize the efforts invested when building these systems such as TensorFlow Recommenders, TorchRec, and NVIDIA-Merlin.
In this article we will make a deep dive into NVIDIA-Merlin, which is a state-of-the-art framework for building recommender systems at scale as it promises to address the different challenges arising from recommender systems workflows. We will summarize important tips that will be useful when assessing its suitability for a project or when starting to work with it.
The problem
One of the biggest issues digital companies are facing nowadays is the engagement of users in their platforms, which translates into increased profits. Questions like: how do we get our Youtube users to click on ‘What’s next’ one after another for a long period of time? Or how do we give a specific Netflix user a “What is recommended for you” suggestion that will help retain them for a bit longer? Even if you have an online fashion store: how do we help our customers find their products in an easier way? “You might also like…” or “Frequently bought together” help solve this issue.
All of the aforementioned examples are possible thanks to recommender systems.
Recommender systems
Recommender systems boost business revenue by helping customers find the desired items and buy the most suitable ones for them with less effort.
Some illustrative examples of how recommender systems are impacting on digital platforms and e-commerce are:
- A McKinsey & Company report attributed 35% of Amazon’s sales to recommendations [1].
- According to the article ‘2019 Personalization Development Study’ held by Monetate: 78% of businesses with a full or partial personalization strategy experienced revenue growth (against a 45.4% revenue growth experienced by businesses with no personalization strategy) [2].
- An Epsilon research shows that 80% of consumers are more likely to make a purchase when the online store offers personalized experiences [3].
- According to Segment: almost 60% of consumers agreed to become repeat shoppers after a personalized shopping experience [4].
Collaborative versus content filtering
Considering there are several criteria to make specific recommendations to users, there are also various types of recommender systems. A first general classification distinguishes between personalized or non-personalized recommenders. An illustrative example of the latter consists of popularity-based recommendations (e.g. when Netflix shows you the most popular movies in your country).
On the other hand, personalized recommendation systems aim to recommend in a “customized” way finding mainly three types of filtering: collaborative, content-based and hybrid ones, which take the advantages of both systems.
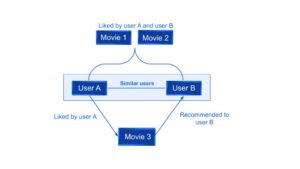
- Collaborative filtering relies on the fact of “similarity in preferences” between users in order to recommend new items. Given previous interactions between users and items, recommender algorithms learn to predict future interaction. The idea is that if some people have made similar decisions and purchases in the past, like a movie choice, then there is a high probability they will agree on additional future selections.
For example, in Fig. 1 it can be seen that if a User A and a User B both liked the same two movies, the system will recommend to user B a third movie liked by user A.
- Content filtering, by contrast, uses the attributes or features of an item -this is the content part- to recommend other items similar to the user’s preferences. This approach is based on similarity of item and user features, given information about a user and items they have interacted with (e.g. a user’s gender, age, the average review for a movie) model the likelihood of a new interaction.
For example, if a user liked a movie A then a movie B with similar features to movie A will be recommended to the user.
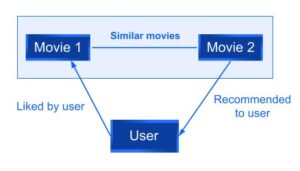
Fig. 2: Content-based filtering examples
- An hybrid recommendation system aims to overcome some of the the limitations of both content-based and collaborative filtering methods. There are several ways to implement this type of systems: making content and collaborative-based predictions separately and then combining them, by adding collaborative-based capabilities to a content-based approach or the other way round.
For example, Netflix makes use of this approach by first comparing what is watched by similar users (collaborative-based filtering) and secondly by recommending movies with similar features to the ones highly rated by the user (content-based filtering).
The challenges
The recommender system inference process involves selecting and ranking candidate items according to the predicted probability that the user will interact with them (those with the highest predicted probability are presented to the user).
In this section we will be discussing how to cope with the obstacles encountered at each step of the workflow when building a recommender system from the beginning until it is ready for customers in production.
1. Getting the data and preparing it for training
Data from users and items interactions come from reviews, likes or even clicks in a website, and are usually stored in datawarehouses or datalakes. These pieces of data are then used to train the recommender systems. The main objective of the ETL (Extract, Transform and Load) process is to prepare the dataset for the training part which usually comes in a tabular format that can even reach a Terabyte scale which means there is a lot of data to process in the feature engineering (i.e. creating new features from existing ones) and preprocessing parts.
For example, if your online fashion store would like to make use of a mailing list in order to send personalized recommendations once a month, you will first have to collect every user interaction inside your website (e.g. which items did the user like, previous reviews made), cleaning the data (e.g. unmeaningful reviews) and select the features that will be used while also creating new ones (e.g. an average user rates can be useful).
Many challenges arise from this step:
- The lack of high quality data: the abcense of high quality data can make you struggle to build an accurate recommendation engine.
- Data sparsity: mostly found in collaborative recommender systems this problem appears when an item is rated by few people but with high ratings reviews which would not appear in the recommendation list. This could provide inaccurate recommendations for users with ‘uncommon’ tastes compared to other users.
- Systems that can adapt to the change in user’s interests: user and item dynamics should be considered when recommending (e.g. recent user’s interests cannot have the same impact on the recommendations as older ones)
- Steps like feature engineering, categorical encoding and normalization of continuous variables normally can take long time specially for commercial recommenders involving huge datasets (terabytes or even bigger ones).l
2. Training
The training step is usually performed by choosing one of the available frameworks (such as Pytorch, Tensorflow or Huge CTR which is a NVIDIA Merlin library that will be discussed later on), evaluated and then ready to move on to production. Some of the challenges that arise in this step are:
- ‘Cold start’ problem (mostly found in collaborative filtering): this problem arises when a new user or a new item is just added to the recommender system where no previous information about the user exists reason why the system is not able to accurately predict next user choices.
- Bottleneck problem: it can happen that your online store experiences a sustained growth leading to a catalog enlargement. So now, a huge amount of data that was not considered at first. This could lead to a ‘bottleneck problem’ in which your potentially huge embedding tables stop fitting into your GPU memory and a corrective action should be made.
3. Deployment and refinement of the recommender system
- Continuous need of retraining due to incoming new users/items registers: even if you have your model working in production and making recommendations to your users you may constantly need to add new products to your online store which will be leading to new interactions with your users. In addition, you will also have new users registering. Both cases lead to the need of retraining your models in order to keep satisfying your user needs. This also leads to the need of loading and unloading models in an easy way.
- Handling many users at the same time
- In some scenarios real-time inference is needed: for example when a customer is next to ‘checkout’ a specific sport product ‘added to cart’ such as some running shorts you will also want to suggest your user buying some other running clothes. In this case, the inference is needed to be performed at the moment, i.e. in real time. When addressing these kinds of issues, the inference time and the amount of users to handle are key aspects to consider.
By contrast, if you want your online store to make use of a mailing list to recommend personalized products for each user once a month you will just be performing the inference step before sending the emails. This consist of a non real-time scenario.
A wide variety of barriers appear when recommender systems are in the scene. So, in order to make data scientists and machine learning developers’ lives simpler (or at least, try to) new tools and frameworks start being developed in order to support this recommendation engine: TensorFlow Recommenders (a library developed by Google researchers), TorchRec (a PyTorch domain library) and Nvidia-Merlin (a framework developed by NVIDIA) are some of them.
From now on this first article will focus on NVIDIA-Merlin which was launched in 2020 and promise to address some of the challenges mentioned above.
NVIDIA-Merlin
NVIDIA Merlin official documentation defines itself as an ‘open-source framework for building high-performing recommender systems at scale’. This framework was designed to accelerate the whole recommender system in the whole recommendation workflow at the following steps:
- Preprocessing
- Feature engineering
- Training
- Inference
- Deploy to production
The following diagram in Fig. 3 shows the main features for which NVIDIA Merlin was developed and how it orchestrates the whole recommendation system. Having this big picture of the process we are then able to jump to each of the libraries designed for this purpose.
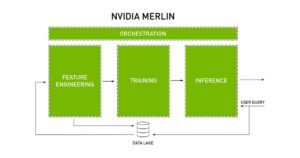
Fig. 4: NVIDIA Merlin orchestration of the main features of a recommendation system [6]
NVIDIA Merlin provides multiple components so a single library or multiple of them can be used to accelerate the entire recommender pipeline: from ingesting, training, inference, to deploying to production.
Depending on the problem you are trying to solve the components of NVIDIA Merlin being used may vary.
The three main libraries that are designed to work together are:
- NVTabular: designed to manipulate recommender system datasets that come in a tabular format. The preprocessing and feature engineering parts are performed by this library.
- Merlin Models: provides standard models (such as Matrix factorization or Two Tower) for recommender systems. This library includes some building blocks that allow defining new architectures.
- Merlin Systems: designed to deploy the recommender pipeline to production. This is done by creating the ensemble that will serve for the Triton Inference Server (described later on) which will perform the inference step.
There are also some other Merlin libraries designed to address some specific challenges:
- HugeCTR: specially useful for cases involving large dataset and huge embedding tables which allow to perform the training step in an efficient way by distributing the training across multiple GPUs and nodes.
- Transformers4Rec: designed for sequential and session-based recommendations this library function makes it different from the rest. Sequential based recommenders capture sequential patterns in users that can anticipate next user intentions and provide them with more accurate recommendations. On the other hand, session-based recommenders (subclass of sequential) are used when you have only access to a short sequence of interactions within the current session aiming to deliver personalized recommendations even when prior user history isn’t available or when users’ taste changes over time.
In addition to Fig. 3 where the key features of a recommender system are summarized, the Fig. 4 shows how each library performs a specific task inside the recommender system workflow.
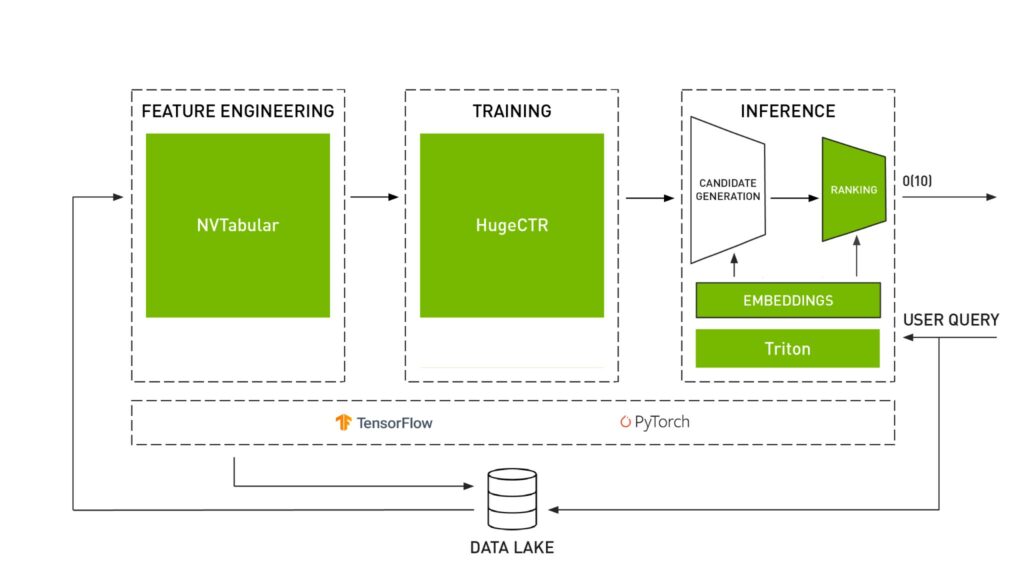
Fig. 4: NVIDIA Merlin libraries [6]
An advice before following: Fig. 4 shows how Merlin is built on Tensorflow and Pytorch. Nevertheless, before following you should be aware that for most of the components, the Pytorch API is initiated but incomplete at the time of publishing this article. So, for example, if in your present project you need to use Merlin Models you will not be able to build it on Pytorch yet.
In addition to these libraries NVIDIA Merlin takes advantage of NVIDIA AI already developed software available in their platform. It is relevant to mention NVIDIA Triton Inference Server which aims to achieve a high-performing inference at scale in production. This is achieved ‘by running the inference efficiently on GPUs by maximizing throughput with the right combination of latency and GPU utilization’, as it is described in official NVIDIA documentation.
Session-based recommender: an end-to-end application using NVIDIA-Merlin
A special scenario comes when you want to predict next user’s interests but you have no prior information about them. This is useful considering user’s interests may change over time or even when users decide to browse in private mode. So, just gathering the information from the current session can help to solve these issues.
An example of this is presented in the official documentation provided by NVIDIA aiming to recommend next user items from the current session interactions.
In this section the main steps and libraries used to achieve this goal are described (you can follow along the code for further reading in [5],[6]).
1st NVTabular: used to define the workflow to preprocess the data by grouping the interactions from the same session, sorting them by time.
2nd Transformers4Rec: this library allows you to make use of the transformer architecture which is imported from the Hugging Face Transformers NLP library in order to do the training. This library also includes Recsys metrics that allow you to measure how well your model is performing.
3rd Triton Inference server: this library allows to deploy and serve the model for inference. The deployment from both is achieved: the ETL workflow (since in the inference you will need to transform the input data as done during training) and the trained model. As a result now your users can query the server obtaining the next item predictions.
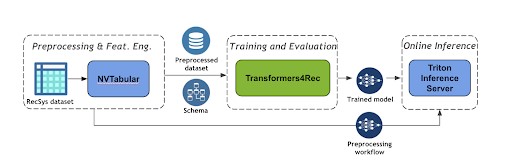
Fig. 5: A session-based recommender workflow [6]
About the solution
After reading NVIDIA’s official documentation we decided to put some hands-on and try some libraries by ourselves. NVTabular and Merlin Models were the main components addressed finding out some key aspects to have in mind before deciding to move on with this tool.
- End-to-End solution
Merlin Models, NVTabular and Merlin Systems are components of Merlin that are designed to work together. NVTabular will output (in addition to the preprocessed parquet files), a schema file describing the dataset structures that is needed to feed Merlin Models. Then, the ensemble with Merlin models must be done in order to get the model inference pipeline. The final step would be to deploy the NV-Tabular workflows and models to Triton Inference server.
This designed integration between libraries makes it straightforward to build end-to-end RecSys pipelines but in terms of flexibility if deciding to move on another technology can be difficult.
- An advice about Docker containers
The simplest way to use Merlin is by running a docker container that can be found in https://catalog.ngc.nvidia.com/containers, in order to avoid libraries-dependencies issues. We decided to run it on an AWS instance g4dn.xlarge which provides a single GPU, 4 vCPU and a 16GiB memory size. Using this type of instance costs USD 243 per month (calculated using AWS calculator). The project you will embark on will set your own infrastructure costs which will be different to this one but for sure needed to be considered before moving on.
As it was already mentioned before, we discovered from the official NVIDIA documentation the following advice: “In our initial releases, Merlin Models features a Tensorflow API. The PyTorch API is initiated, but incomplete”.
So, first thing to be aware of: despite some specific components (as for Transformers4rec) NVIDIA-Merlin is designed to be integrated with Tensorflow.
Final thoughts
In this article we first discussed the impact of recommender systems in today’s digital platforms and the different types of filterings. Then we moved on to understand the main challenges that arise from recommenders and the need of tools that support every step of the workflow process. Finally we introduced and discussed NVIDIA Merlin, a promising framework for building end-to-end recommender systems which can be useful to speed up the preprocessing and feature engineering using NV Tabular but is not as flexible (up to now) to be used for a whole recommender system built on Pytorch. We also discussed session-based recommenders which are particularly useful when no prior user interactions are found.
At Marvik we are always searching for state-of-the-art technologies in order to solve complex problems. Feel free to contact us at [email protected]i if you have any questions or want to share some ideas.
References
[1] I. MacKenzie, C. Meyer, S. Noble (2013, October 1). “How retailers can keep up with consumers”. https://www.mckinsey.com/industries/retail/our-insights/how-retailers-can-keep-up-with-consumers
[2] Monetate (2019). “2019 Personalization Development Study”. https://info.monetate.com/rs/092-TQN-434/images/2019_Personalization_Development_Study_US.pdf
[3] Epsilon (2018, January 9). “New epsilon research indicates 80 of consumers are more likely to make a purchase when brands offer personalized experiences”. https://www.epsilon.com/us/about-us/pressroom/new-epsilon-research-indicates-80-of-consumers-are-more-likely-to-make-a-purchase-when-brands-offer-personalized-experiences
[4] Keating (2021, June 1). “Announcing the state of personalization 2021”. https://segment.com/blog/announcing-the-state-of-personalization-2021/
[5] NVIDIA. https://nvidia-merlin.github.io/Transformers4Rec/main/examples/tutorial/03-Session-based-recsys.html (accessed 12/12/2022)
[6] R. AK, G. Moreira (2022, June 28). “Transformers4rec – Building session based recommendation with an nvidia merlin library”. https://developer.nvidia.com/blog/transformers4rec-building-session-based-recommendations-with-an-nvidia-merlin-library/
[7] ] NVIDIA. https://github.com/NVIDIA-Merlin/Merlin (accessed 12/12/2022)

