By Ilana Stolovas
Autonomous vehicles are great, but it seems hard to get into that world, right? What should be your starting point? Autonomous vehicles should be capable of handling multiple sensors and actuators. Such tasks are orchestrated on powerful hardware and must manage an extremely reliable control system. Don’t get overwhelmed if you don’t know what to do first, getting into a new subject involves a lot of research and hands-on trial and error to get on the track.
Since autonomous systems are indeed a broad topic, we want to specially focus on visual information, tackling object detection in camera frames. This post aims to discuss some of the challenges of designing and deploying a system for traffic signs detection.

Where does the software run?
One of the main questions we ask if we want to build a first but scalable system: Where to deploy it? Should it run on the edge (on-vehicle) or in the cloud? Is cloud computing appropriate in terms of security? Would it be possible to rely on an internet connection? And what if it fails or the latency is critical? To handle these issues, edge computing comes to the rescue, and NVIDIA Jetson sounds like the best option.
Jetson devices run Linux OS making it an easy-to-use development tool, and enable communication to physical actuators, either transmitting to a local network or by GPIO voltage outputs. Machine learning applications can be optimized using TensorRT, a C++ library for high performance inference on NVIDIA GPUs. We recommend choosing a Jetpack SDK suitable for your project requirements (we used v4.4), and pay attention to TensorRT, CuDNN and CUDA versions. Watch out for the package versions on your target application, as compatibility issues are frequent.
How to glue the pieces together?
So now that you have a hardware candidate, let’s talk about the software behind. You need to interact with sensor data (e.g. camera frames), process it and generate an appropriate response for the actuators. You could either make a custom processing pipeline, or leverage existing tools.
ROS, for Robot Operating System, is a renowned open-source software framework in the field of robotic programming and particularly on autonomous vehicles. It is well-suited for data handling between processing modules (called nodes), which can be written in either C++ or Python. As ML developers we adore Python, but we cannot hide the fact that C++ is much better for embedded applications. As a compiled language, it makes more efficient use of memory resources. We suggest using ROS infrastructure, not only because it is relatively simple to use but also because it has a lot of developed free code for the kind of applications we need, such as camera feed reception and message type definitions.
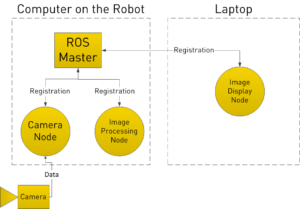
What are we building after all?
At this point we have the where and the how, let’s focus on the what: the object detection application. As mentioned at the beginning, the target is to design a system for traffic signs detection running on autonomous vehicles. You may think of it as a ROS node running the inference of a neural network, trained with an appropriate dataset for the task and doing some kind of additional processing. And that is all the story, but we want to share with you a few insights of this process.
Firstly, you need to choose the network architecture. Faster-R-CNN, ResNet or YOLO are good candidates for object detection in Tensorflow. We will discuss the YOLOv4 procedure but it should be similar for any chosen architecture. Note that YOLOv4 is originally attached to Darknet, an open-source library created by its authors. For TensorRT conversion, you may need to convert the trained model to ONNX format and then to TensorRT.
Secondly, you may build or leverage a dataset for model training, labeled for object detection (box coordinates and classes). The COCO dataset has a “stop sign” class, and there are publicly available traffic signs datasets with varying licenses.
Lastly, you would need to process your inference results. ROS has public libraries with predefined message types, such as vision_msgs for bounding boxes and class scores. In the context of video processing, a frame-to-frame detection should be followed by a post-processing stage to smooth the signals and generate a stable output. Imagine a situation in which, after a minute of video with no signs detected, a single detection of a stop sign is made. Do you stop immediately? What if it was a false positive? You would not want to trigger an alert in that case, but if it stays the same for a couple of seconds it is more likely to be a good guess.
Are we missing something?
We have walked through the main hardware and software interaction insights on an autonomous vehicle application system. We discussed the benefits of edge processing and Jetson optimizations, together with the ROS development framework. We also described a use case on traffic signs detection and the key steps to train and deploy the model.
More challenges will be faced depending on your particular use case. Is processing frame rate tolerable for our application? Which protocol should the camera frame provider use? How are priorities managed for shared resources? These and more questions start to emerge when digging into the project requirements.
We hope to have broadened your perspective on the most relevant aspects of designing an embedded application for object detection. One could think machine learning is all about discussing model architectures and tuning hyperparameters, but as the following picture shows, production ML systems are huge ecosystems of which the model is just a single part.
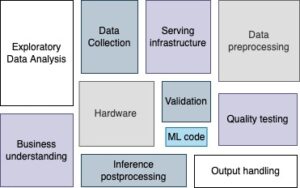
Links of interest:
- Code repository for deploying neural networks onto the embedded Jetson platform: https://github.com/dusty-nv/jetson-inference
- ROS official documentation: https://wiki.ros.org/
- Final diagram inspired on: https://developers.google.com/machine-learning/crash-course/production-ml-systems

