Welcome to Marvik Digest 🚀
By Natalia Cohn
We’ve got some exciting news.
We are happy to announce the launch of Marvik Digest 🙌 🚀 We will get you up to date on the most relevant topics that were discussed in the ML community in the past weeks.
Want us to cover a specific topic? DM or ping us to [email protected] to send us your suggestions.
Stay tuned for more content!
Flamingo
As humans, our experience of the world is multimodal. We can hear, taste, see, feel and smell things. In order for #machinelearning to help solve real-world challenges, it should be able to build models that can efficiently process and interpret information coming from different data sources (image 🌅, text 📄, speech 💬, numerical 🔢).
We are now closer to achieving that with DeepMind’s recent introduction of #flamingo 🦩, a state-of-the-art model that can seamlessly tackle images 🌅, text 📄, and even videos 📹. It is a visual language model (#vlm) that can rapidly adapt its behavior given just a couple of task-specific examples, without requiring any additional training 🏋️♀️ (as seen below passing the Stroop test). So far, results show that for open-ended tasks (like visual question-answering), 🦩 beats the performance of models fine-tuned on much more task-specific data.
👉 To read the full story, visit https://bit.ly/3vVkj6G

Vertex AI
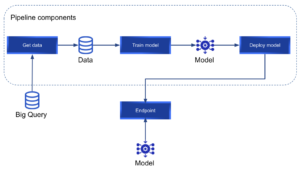
Have you ever struggled to put #ml models into production? Usually, this process takes up a huge amount of time and resources.
In this article, our ML engineer Federico Baiocco tells us about Google‘s service #vertexai , which allows us to build, deploy, and scale ML models faster with custom, pre-trained tools within a unified #AI platform. He goes step-by-step on how to build a #kubeflow pipeline to train a custom model, retrieving data from #bigquery and deploying it using #vertexai.
“Vertex AI makes it easy to train, deploy and compare model results. It is an excellent tool that allows us to focus on ML solutions rather than infrastructure management.”
👉 Visit our blog for the full story https://bit.ly/3OUOtQ3
👉 Reach out to [email protected] to learn more about our experience using Vertex AI
Hugging face raises Series C
Hugging Face recently raised $100M in a Series C round of funding 🚀🚀 Congratulations to the entire team 👏👏👏👏
This is great news for the #machinelearning field. A step forward to keep advancing and democratizing artificial intelligence through open source and open science. Thanks for all the support you constantly give to the #ml community.
👉 Read the full story here: https://bit.ly/3yr2WO2
Another good news for the #machinelearning community 🙌 🎉

Open Pretrained Transformer (OPT-175B)
Meta AI recently launched #OpenPretrainedTransformer (OPT-175B), a large language model trained on 175 billion parameters. Until now, access to models of such scale had been significantly restricted. In line with Meta AI’s commitment to #openscience, the model was trained on publicly available data sets, and its release includes both the pretrained models and the code required to train and use them on research use cases.
This opens up new opportunities to understand how and why large language models work, as well as to find ways to improve their robustness and mitigate common issues.
Kudos to Meta AI for its commitment to democratize and drive the field forward 👏 👏 👏
👉 Find out more here https://bit.ly/3MeYDJX

Gato
A single #AI model that can perform over 600 types of tasks? 🤯 This is turning possible with DeepMind’s recent release of #gato 🐈, a generalist #AI agent that can be trained to caption images, engage in dialogue, stack blocks with a real robot arm and play Atari with a single transformer neural architecture.
🟢 Main takeaways:
📌 Inspired by progress in large-scale language modeling.
📌 The same network with same weights can work with multiple kinds of data to perform multiple kinds of tasks.
📌On 450 of the 604 tasks used to train 🐈, results show that it performs better than an expert more than half the time. Nevertheless, it performs sub-optimally compared to models trained for specific tasks.
📌 By scaling up the parameter size, 🐈 has the potential to achieve better performance results.
Gato 🐈 is far from perfect, but it is certainly a step forward on the long path towards #artificialgeneralintelligence (AGI).
👉 Click here to read more about Gato 🐈: https://bit.ly/3leTMwm
👉 To check out the original paper: https://bit.ly/3wAZjSX

Machine Learning School
The day has finally arrived 🙌 On Monday we welcomed the first batch of interns of the Machine Learning School 🚀 🎉
For 3 months, they will embark on a journey to learn all about the #machinelearning field and put them into practice to tackle several challenging projects.
Stay tuned for more updates! 📢
👉 Know someone who could be a good fit for upcoming editions? DM or reach out to [email protected]
👉 Want to know more? Visit https://bit.ly/3uCXZPP
![]()
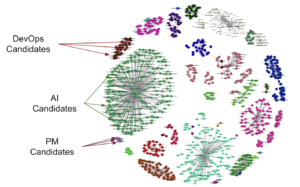
Recommendation systems: matching skills with jobs
For companies out there looking to hire new talent 🔍, we know that matching the right talent to the right role is a huge challenge. Not to mention it has a direct impact on performance 📈.
In this new blog, our #mlengineer Arturo Collazo Gil gives a hint on how to tackle this with the use of recommendation systems. He guides us through the process of how the team approached the skill extraction step taking as inputs resumes (CV) and job descriptions.
“The project has been an amazing journey (sometimes a roller coaster🎢) requiring a lot of innovation in terms of combining techniques, #ML algorithms and the adequate tools to create the matches.”
👉 Visit our blog for the full story https://bit.ly/3Nu7uHG
👉 Reach out to [email protected] to learn more about our experience building recommendations systems
Imagen
Google unveils its competitor to #DALL·E2 🤯 Imagen is Google new #ai system that creates photorealistic images from input text with a deep level of language understanding 🚀
➡️ Main takeaways
✅ Builds on the power of large #transformer #languagemodels and #diffusionmodels
✅ Finds that scaling the pretrained text encoder size is more important than scaling the diffusion model size
✅ Achieves a new state-of-the-art FID score of 7.27 on the #COCOdataset
✅ Introduces #DrawBench, a comprehensive and challenging benchmark for text-to-image models
✅ Reveals that human raters strongly prefer Imagen over other methods
➡️ Want to know more?
👉 Visit https://bit.ly/3sXM3am
👉 To read the full paper https://bit.ly/39ThCLE

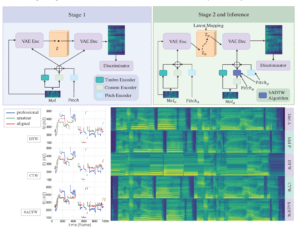
Neural Singing Voice Beautifier
A model capable of generating high quality singing recordings, while improving intonation and vocal tone? 🤯
Researchers at Zhejiang University have reached new heights with the recent release of the first #generativemodel to solve the task of singing voice beautifying (#SVB). The model, dubbed Neural Singing Voice Beautifier (#NSVB), tackles not only the improvement of intonation but also the overall aesthetic quality
🟢 Highlights
📌 Is based on a conditional variational autoencoder as its pillar and is able to learn the latent representations of vocal tone
📌 Introduces a novel time-warping approach for pitch correction
📌 Introduces a latent-mapping algorithm in the latent space to transform the vocal tones, from amateur to professional
📌 Proposes a new dataset containing the same singing recordings of both amateur and professional versions
📌 Demonstrates its effectiveness by experimenting on both Chinese and English songs
➡️ Want to see this model in action? Check out the audio samples here https://bit.ly/3x1DVHY