By Arturo Collazo
Intro
The challenge of connecting talents with employment opportunities has been a major task of recruiters for a long time. The search is always scoped to budget, job specs and time, so doubt always arises: are we getting the best match? or a good enough one?
Recommendation Systems are a powerful tool to provide users with personalized, real-time suggestions. You have probably been using them a lot, when ordering food, choosing a show to watch or buying goods and services online.
This post presents how Marvik’s team approached the skill extraction step on an application in which we were wondering how to match the best profiles with open positions, through ML and tons (tons!) of data. The project has been an amazing journey (sometimes a roller coaster) requiring a lot of innovation in terms of combining techniques, ML algorithms and the adequate tools to create the matches.

🔥The challenge
In our goal to generate pairs of job offers – applicants, we faced various challenges. To begin with, as any data-related project, the data itself. Although we could access a great volume of data (thousands of gigas), it could be unstructured, have different extension (that is doc, docx or pdf among others), or be incomplete. Additionally, performance was a must (nobody wants to wait to get the results), so applying the best development techniques and practices such as steam, lemmatization, search trees, with the proper tools (inverted index for instance), was crucial at each stage.
From text to the vectorial representation
📄Little warm up
Continuous bag of words (CBOW) is a technique where the goal is to predict the current word, considering a window of surrounding words (before and after). Alternatively, continuous skip gram tries to predict the mentioned context positioning on the current word.
Skill2Vec is a technique based on CBOW and C-Skip gram to get skills from documents. Its main advantage is the generated vectorial space where the relationship between skills is represented.
Moreover, Doc2Vec has a similar usability, where tokens inputs are received and a unique vector is obtained, with the advantage of vector distance similarity when the inputs have similar meanings.
Enough theory: hands on!
To obtain a vector that describes the profile of a candidate and the core requirements of a position, we stacked skill2vec and doc2vec to be used as a whitelist to extract the mentioned skills, and build the blueprint (unique vector), respectively.
🙋Candidates & Opportunities
The skill extraction process was our first task and the input involved (CV) did not have a defined format, as we said before. Once we received it, we extracted the text and obtained the skills over Skill2vec. The same was done for the job description.
For instance, given the following resume extract:
“I am currently working as a software engineer at company_name. work based on ERP .In this work am doing HR module. Basicaly doing this work using postgresql, osslib, js & php.Besides my profession,i have completed my mca degree.“
We obtained this set of skills: postgresql, osslib, js, php.
And, from the next job description:
“In this role, you should be a team player with a keen eye for detail and problem-solving skills. If you also have experience in Agile frameworks and popular coding languages (e.g. JavaScript), we’d like to meet you.
This position requires to:
- Work with developers to design algorithms and flowcharts
- Produce clean, efficient code based on specifications
- Integrate software components and third-party programs
- Proven experience as a Software Developer, Software Engineer or similar role
- Experience with software design and development in a test-driven environment
- Knowledge of coding languages (e.g. C++, Java, JavaScript) and frameworks/systems (e.g. AngularJS, Git)
- Experience with databases and Object-Relational Mapping (ORM) frameworks (e.g. Hibernate)
- Ability to learn new languages and technologies”
We extracted: agile, javascript, C++, Java, AngularJs, Git, ORM, Hibernate.
Following is the process we used to extract the skills:
- extract text
- split it by words (further, referenced as token)
- remove stop words
- lemmatize
- comparison vocab
These steps are also replicated with the job description as the input.
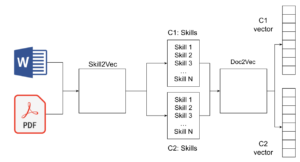
Therefore, at this point we had the skills as a list of tokens. That structure was our document, used to get the vector representation. In contrast to Skill2Vec which was already trained, we had to train doc2vec on our own.
We fitted the model, passing more than a million documents as inputs, arriving at an awesome result. One of the main advantages of doc2vec is the embedding that is within, so the outputs are highly precise.
🔍Checking results
At this point, we were thrilled about the correctness of our result (recommendations), but we also needed to consider our client’s requirement regarding performance. Hence, we combined two extraordinaries techniques to get results: Approximate Nearest Neighbors (ANN) and word mover distance (WMD).
With ANN, we get (roughly speaking) a neighborhood of talents that might be related, but these preliminary results needed a little sanitization and purge. After that, we applied word mover distance as a filter on the related documents (vectors), to obtain the best (closer) candidates for an open position.
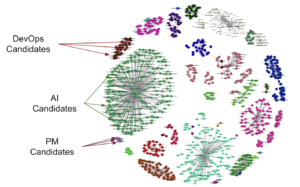
Ok, and now what? Lessons & Conclusions
To conclude, there are some highlights and lessons to share! Probably the basic one was the old but reliable divide & conquer, considering we faced a lot of obstacles to build the model.
Likewise, since its release the client has been serving several matches and is really happy with the output. Furthermore, we are brainstorming to apply these techniques to career counseling to match career paths with talents, a proactive move at our end.
Before saying goodbye, do not forget that you can ping us in marvik.ai, to discuss ideas, projects or doubts that you might have.

