By Joaquin Bengochea
In this blog we are going to talk about a technique called model distillation, and how can it be used to train supervised models from synthetic datasets created with GANs.
With this technique, we can take advantage of the properties of unconditional image generation and use them in conditional models, with an outstanding improvement in execution time (more than 150 times faster) and cost.
A bit of theory
Generative models are a subgroup of unsupervised models with the capability of generalizing and creating new elements from data examples. Generative Adversarial Networks (GANs) can be found inside this group.
GANs
GANs define a generative nets architecture based in 2 sub-models: the generator and the discriminator. Both of them compete in a zero sum game, trying to fool their adversary. The generator receives noise proceeding from a predefined latent space, and has to generate content similar from the input set. The discriminator, in the other hand, must discern if the content given by the generator belongs to the input set or not. Both models are trained jointly, giving feedback to each other, until the generator can fool the discriminator about half the time.
There are many applications of GANs in computer vision, from creation and automatic edition of high quality content, to data augmentation.
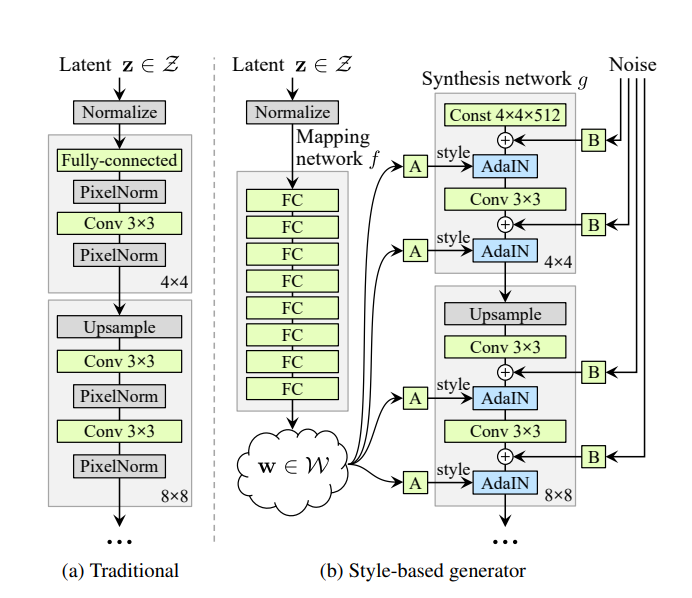
StyleGAN2[1] is a GAN architecture created by NVIDIA for image generation, mostly used for human faces, whose generator has the ability to modify individual features from an image in a highly decoupled way, allowing to apply styles to the generated image with different levels of granularity.


Its generator incorporates a mapping network of 8 fully connected layers, that receives a vector Z and generates 18 vectors from the latent space W. Those vectors feed each of the 18 layers of the generator individually, making it possible to modify only a few to apply specific changes on the image, without altering it as a whole.
cGANs
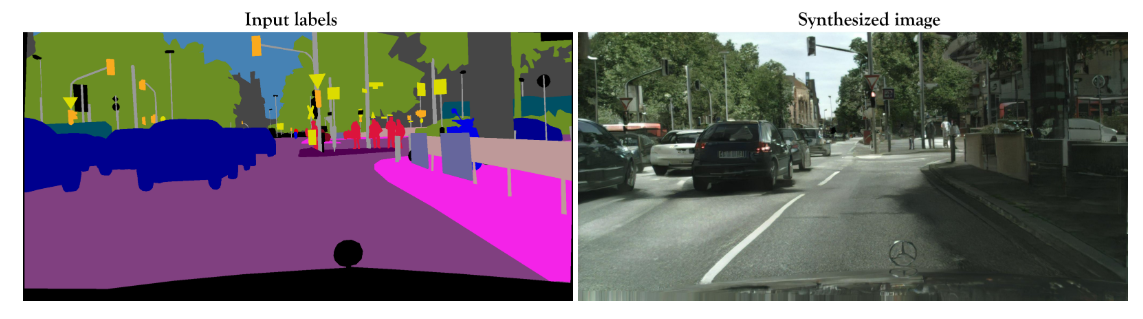
Conditional GANs (cGANs), in the other hand, are GAN networks that use additional information that conditions the data generation. They are usually trained with pairs of images source-target, thus making the task supervised. Pix2PixHD[2] is a cGAN model that allows to create photo-realistic images from semantic label maps. This model is trained with pairs of images, and requires a big dataset.
Real life application
In one of our projects, we had an automatic image transformation system made with StyleGAN. The system used an encoder to find the vector representation of a real image in StyleGAN’s latent space, then it modified the vector applying the feature transformation, and generated the image with the resulting vector. The problem of this system is that, in order to find the vector of the real image, it must execute several backpropagation iterations, comparing resulting images with the objective, trying to approximate it. This task is really time and compute expensive. In this case, our job was to reduce the execution time of the system without compromising the quality of the images.
Model distillation
Our solution consisted in using a technique called model distillation to leverage the lack of images needed to train Pix2PixHD. It was used to tackle this problem in the paper “StyleGAN2 Distillation for Feed-forward Image Manipulation”[3] This technique consists in making a student network learn from the output of a larger teacher network. In our case, this concept is applied generating random images and their respective latent vectors with StyleGAN2, applying the feature transformations to the vectors and generating the pairs with the original and the modified image. In this way, we were able to create a synthetic dataset of 10,000 high quality images to train Pix2PixHD.
We conducted a qualitative test about the quality of the images generated by StyleGAN2 and found out that, approximately, 86% of the images had an acceptable quality. We needed to find a way to clean that remaining 14%.
Preparing the data
As the original system was only used in adults, we decided to filter the generated dataset, given that StyleGAN2 generates faces of all ages. In order to do this we used Azure’s Face API to classify each image and filter every image outside of our target range. This also had a side benefit: we filtered out images with too many artifacts in which the API was unable to recognize the age. This way, we made sure that the images had an acceptable quality at a very low cost.

Training
With the dataset ready, we proceeded to the training. We opted for a g4dn.xlarge AWS EC2 instance, with an hourly cost of $0.526 and an estimated time to complete the 200 epochs of 22 days (we previously run a few epochs to calculate this estimate), resulting in an approximate cost of $277 for the whole training.
Results
The results exceeded the expectations in computing time and hardware cost, maintaining the great quality of the images, and generating a realistic transformations for both StyleGAN2 generated and real images.




We had the average time of the previous version, 19.36 seconds in a g3s.xlarge instance with an hourly cost of $0.75 as benchmark. The inference time of the new model, averaged from 500 images in the same instance was 0.11 seconds, 176 times lower.
At the same time, with the necessity of the encoder to find latent vectors removed, it was possible to run the model in instances without GPU, with inference times also better than the original version. For example, inference time in a CPU only c5.2xlarge is 1.5 seconds, even a t2.medium can run the model with an inference time of 7.23 seconds.
Key takeaways
- StyleGAN2 generates high quality images, with plenty of transformation capabilities. It can be used with real images with the help of an encoder, but proved to be slow and expensive.
- However, StyleGAN2 proved to have enough potential to generate a diverse, high quality synthetic dataset. This dataset can be used to train a conditional model without the downsides of having to incorporate an encoder.
- Pix2PixHD can be used to generate automatic transformations in realistic images given a big enough dataset. It suits great with StyleGAN generated datasets.
- External API’s like Azure’s Face API can be used as automatic data validation.
References
[1] Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., Aila, T.: Analyzing and improving the image quality of stylegan. arXiv preprint arXiv:1912.04958 (2019)
[2] Wang, Ting-Chun et al. “High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs.” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (2018)
[3] Viazovetskyi, Yuri, Vladimir Ivashkin, and Evgeny Kashin. “StyleGAN2 Distillation for Feed-Forward Image Manipulation.” Lecture Notes in Computer Science (2020)

