Speech synthesis and voice cloning
By Ilana Stolovas
Speech synthesis literally means producing artificial human speech. It presents a lot of practical applications, such as music generation, text-to-speech conversion or navigation systems guidance.
Traditional approaches for speech synthesis involved searching for speech units that match an input text on a large database and concatenate them to produce an audio file. It often resulted in an emotionless and unnatural speech. Parametric approaches have also been developed, lying on the idea that speech can be synthesized combining features like fundamental frequency and magnitude spectrum.
Nowadays, TTS (text-to-speech) models have taken a step further, not only making machines talk, but also pushing them to sound like humans of different ages and gender, or even to resemble a target voice.
By reading this post you will discover some selected models for:
- Spectrogram to audio waveforms synthesizing (vocoder)
- Text to speech conversion
- Voice cloning: Flowtron
Spectrogram to audio

Traditional models typically generate audio waveforms by passing the spectral information through signal processing algorithms, known as vocoders. Some models that achieve that purpose are:
- The Griffin-Lim algorithm: a phase reconstruction method based on the redundancy of the short-time Fourier transform, used to recover an audio signal from a magnitude-only spectrogram. It is implemented in Librosa Python library.
- Wavenet: Authored by Google Deepmind. It presents a neural network based on PixelCNN for generating raw audio waveforms. Their model is fully probabilistic and autoregressive, and generates text-to-speech results for both English and Mandarin. Although the original model performs the entire text-to-speech pipeline, posterior synthesizers use a modified version of the WaveNet architecture for the task of inverting the Mel spectrogram feature representation into time-domain waveform samples.
Obs: autoregressive models are inherently serial, and hence can’t fully utilize parallel processors like GPUs or TPUs. - Waveglow: Authored by NVIDIA. It is a ‘flow-based’ network capable of generating high quality speech from mel-spectrograms, combining insights from Glow and WaveNet, without the need for auto-regression.
Text to speech conversion

State-of-the-art text-to-speech techniques are owned by third party service providers, such as AWS, Google Cloud and Microsoft Azure, all of which are paid per use (we will not get into detail of those). They have state of the art results but do not suite all applications (for example custom voices).
We present two TTS synthesizers whose fundamentals are of public concern and their implementations can be easily found. The models are ranked by the Mean Opinion Score (MOS), a numerical measure of the human-judged overall quality of an event or experience on a scale of 1 (bad) to 5 (excellent).
- Tacotron: Its pipeline takes characters as input and produces spectrogram frames, which are then converted to audio waveforms. It has a seq2seq model that includes an encoder, an attention-based decoder, and a post-processing net. The latter is called ‘CBHG module’, and aims to convert the decoder’s output into a target that can be synthesized into waveforms (a spectrogram). The vocoder step is implemented by the Griff-Lim algorithm described above. Given pairs (text,audio), Tacotron can be trained completely from scratch with random initialization. The model is ranked with a MOS of 3.82/5. There is no official implementation available, but several repositories can be accessed.

- Tacotron 2: Similar to Tacotron, presents a system composed of a recurrent sequence-to-sequence feature prediction network that maps character embeddings to mel-scale spectrograms. In contrast with the latter, it is followed by a modified WaveNet model acting as a vocoder to synthesize time-domain waveforms from those spectrograms. The model is trained on an internal US English dataset, which contains 24.6 hours of speech from a single professional female speaker. The model is ranked with a MOS of 4.53/5. A Pytorch implementation is available.

Voice cloning
The purpose of voice cloning is to resemble a target voice or style on a speech generation framework. Those algorithms are often trained with the desired speakers and are rarely easy to fine-tune with other speakers.
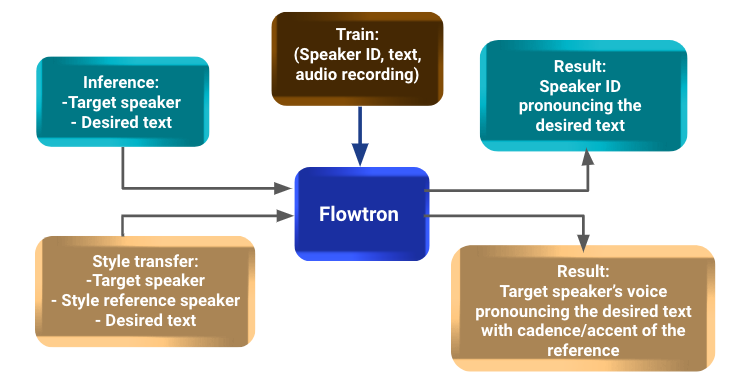
One of the most promising solution at the moment of writing this post is Flowtron, NVIDIA’s state-of-the-art TTS model. It provides a text-to-speech solution using Tacotron 2 and adds a voice style transfer with additional processing.
Flowtron models are pre-trained with audio recordings from different speakers and their corresponding text narrations. To introduce new speakers, a fine-tuning step should be done.
The key concept is the following: Flowtron learns an invertible function that maps a distribution over speech characteristics (mel spectrograms) to a latent z-space parametrized by a simple distribution (Gaussian) and conditioned on an input text sample. Though, we can generate samples containing specific speech characteristics manifested in mel-spectrogram-space by finding and sampling the corresponding region in z-space.
The model is ranked with a MOS of 3.67/5.
In terms of inference, an audio can be generated feeding the model with a text, and indicating the id of the desired speaker.
On one hand, adding a new speaker to the model is an expensive task. It requires several hours of short audio recordings with their respective transcriptions to fine-tune a pretrained model. Models trained with less data have shown poor performance in practice.
On the other hand, for style transfer only a few samples of the target speaker are needed. The model achieves to transfer voice features like the cadence or the accent of the target to the model speaker voice.
The repository is available here.
Final comments
We have explored different alternatives to implement a text-to-speech pipeline, understanding the concepts behind them, looking for practical implementations and benchmarking solutions. The post aims to sum up what we considered as the most powerful and promising solutions for the task.
As a part of the research we came across some other papers and implementations we discarded (and are mentioned below in order to save your time!):
- https://github.com/CorentinJ/Real-Time-Voice-Cloning, it comes with a disclaimer: ‘not only is the environment a mess to setup, but you might end up being disappointed by the results’.
- Neural Voice Cloning with a Few Samples
Based on: this paper, it claims the following:
‘We clone voices for speakers in a content independent way. This means that we have to encapture the identity of the speaker rather than the content they speak. We try to do this by making a speaker embedding space for different speakers’. This project is archived and no longer maintained nor recommended by its owner. - 15.ai, a MIT project, has excellent results but it has not yet been open-sourced or published.

