By Matias Kloster
Vision transformers are rapidly gaining popularity in the field of computer vision. These transformers, based on the same principles as the transformers used in natural language processing (NLP), have shown excellent results in various computer vision tasks, such as image classification, object detection, segmentation, and more.
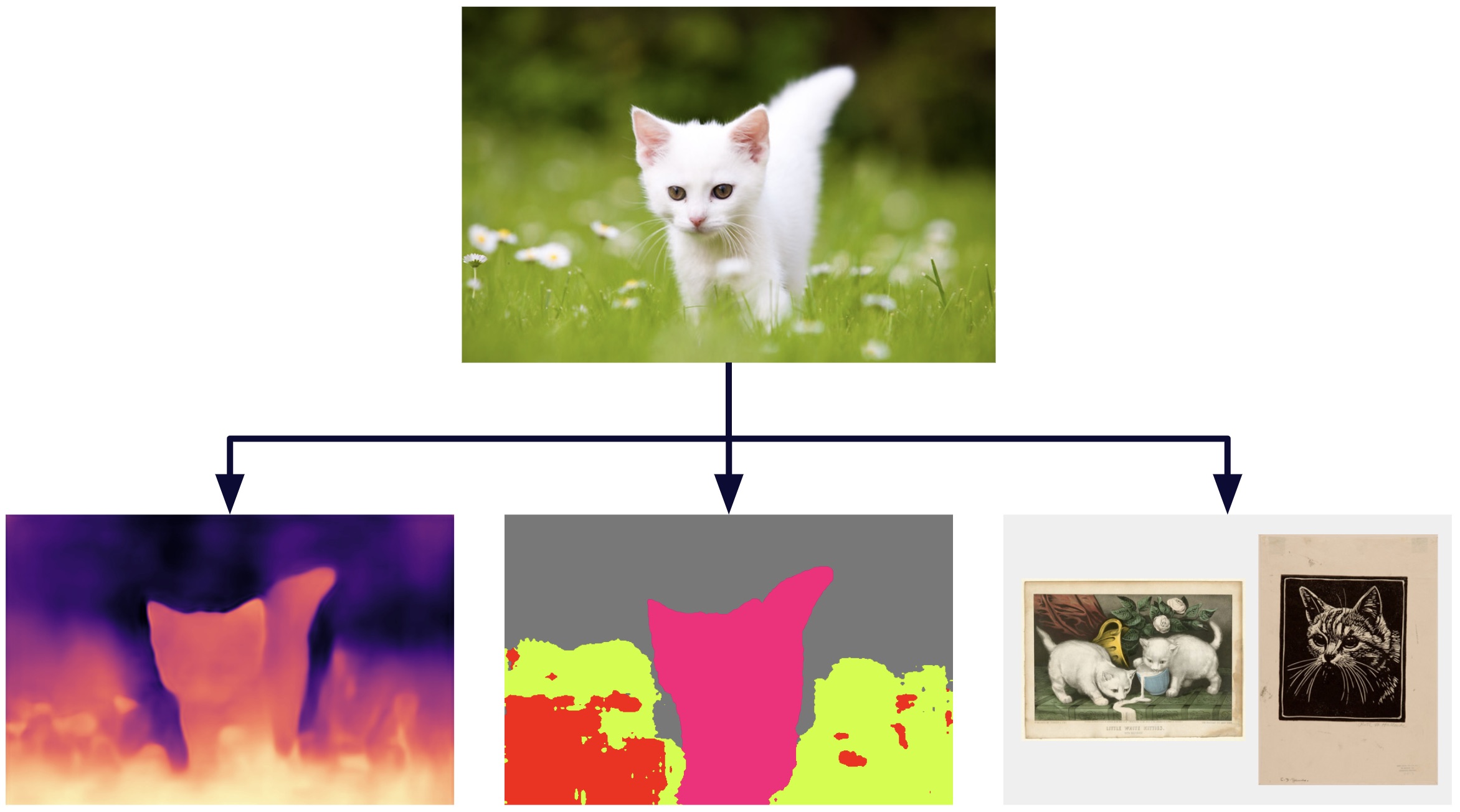
Image created with the outputs of the tool found in the demo of DINOv2 [1]
Just like in NLP, there is a need for a backbone model that can serve as a general feature extractor for various computer vision tasks. Such a model would enable researchers and practitioners to develop more specialized models that can perform specific tasks with better accuracy and efficiency.
Recently, a new vision transformer called DINOv2 has emerged, which has shown promising results in self-supervised learning for extracting important features in the backbone. Let’s have a closer look at the details of DINOv2 and how it has been able to achieve such impressive results through self-supervised learning.
A closer look into DINOv2
DINOv2 (self DIstillation with NO labels) is an innovative self-supervised learning algorithm developed by Meta, which improves the efficiency and performance of its predecessor, DINO or DINOv1. It uses vision transformers (ViT) to extract knowledge from images without the need for labeled data and, in addition, enables multi-modality learning. This makes it an attractive option for those looking to reduce reliance on labeled data in machine learning and improve performance on downstream tasks.
The use of unlabeled data is a technique that is also commonly used is image-text pre-training, this has its limitations. This technique often does not consider critical information that is not explicitly mentioned in the text descriptions, which can affect the model’s ability to learn certain patterns. In addition, the image-text pre-training process can require large amounts of labeled data to train suitable models, which can be costly and time-consuming.
For example, if an image belongs to a training dataset and comes with a detailed description such as “Close-up of a plant growing above the ground. The dominant colors in the image are green and yellow. The background is blurred and greenish-black. The environment appears to be outdoors or in a forest, as there is grass and other vegetation visible around the plant”, the machine learning algorithm may miss important information that is not mentioned in the description, such as the position of the plant in the image, the relative size between the plant and the image, among other aspects. This is because the algorithm learns to relate the image to the text provided and may miss other relevant visual features.

In summary, DINOv2 is a self-supervised learning technique that does not rely on text descriptions for learning, which allows it to capture more complete and relevant information from images compared to other techniques that rely on text descriptions.
While DINOv2 uses images that are not labeled, to obtain good results it is key that the database is curated. The methodology for obtaining a large curated database is explained below.
Construction of the dataset
A database of 142 million images called LVD-142M was created, which were extracted from an uncurated set of 1.2 billion images.
The first step in the process is to take an initial set of images, which are selected from 25 third-party datasets such as ImageNet-22k and Google Landmarks. Then, duplicate images are removed. Next, we proceed to compute an image embedding using a ViT-H/16 self-supervised network previously trained with ImageNet-22k and use the cosine similarity measure to determine the distance between images and select those that are similar to those found in the curated data. To perform this task efficiently, the Faiss library was used.
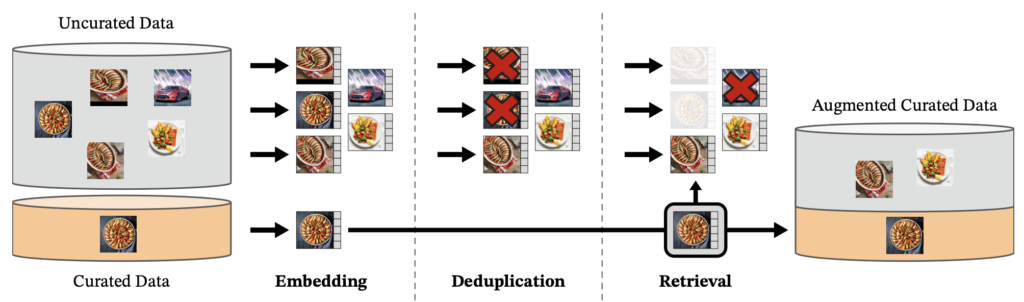
Image extracted from the official paper of DINOv2 [2]
How it works
Before diving into more details about DINOv2, it is important to understand what Visual Transformers are. That is why a brief explanation of them is presented here.
A brief explanation of Visual Transformers (ViT)
In 2017, the Transformer architecture was introduced in the field of natural language processing with the paper “Attention is all you need”. Then in 2021, the Vision Transformer (ViT) concept was presented in the paper “An Image is Worth 16*16 Words”. ViT is an adaptation of the Transformer architecture for image processing, allowing a neural network to learn from large image datasets. ViT has shown outstanding results in a variety of tasks and can be an alternative to convolutional networks in some cases.
In ViTs, input images are treated as a sequence of patches where each patch is flattened into a single vector by concatenating the channels of all pixels in a patch and then linearly projected onto the desired input dimension.
Let’s explore the steps:
- Split an image into patches.
- Flatten the patches.
- Produce linear embeddings of smaller dimensions from the flattened patches.
- Add positional embeddings.
- Use the sequence as input to a standard transformer encoder.
- Pre-train the model with image labels in the case of supervised learning, which is the most common. However, it is explained below how DINOv2 uses vision transformers in self-supervised learning.
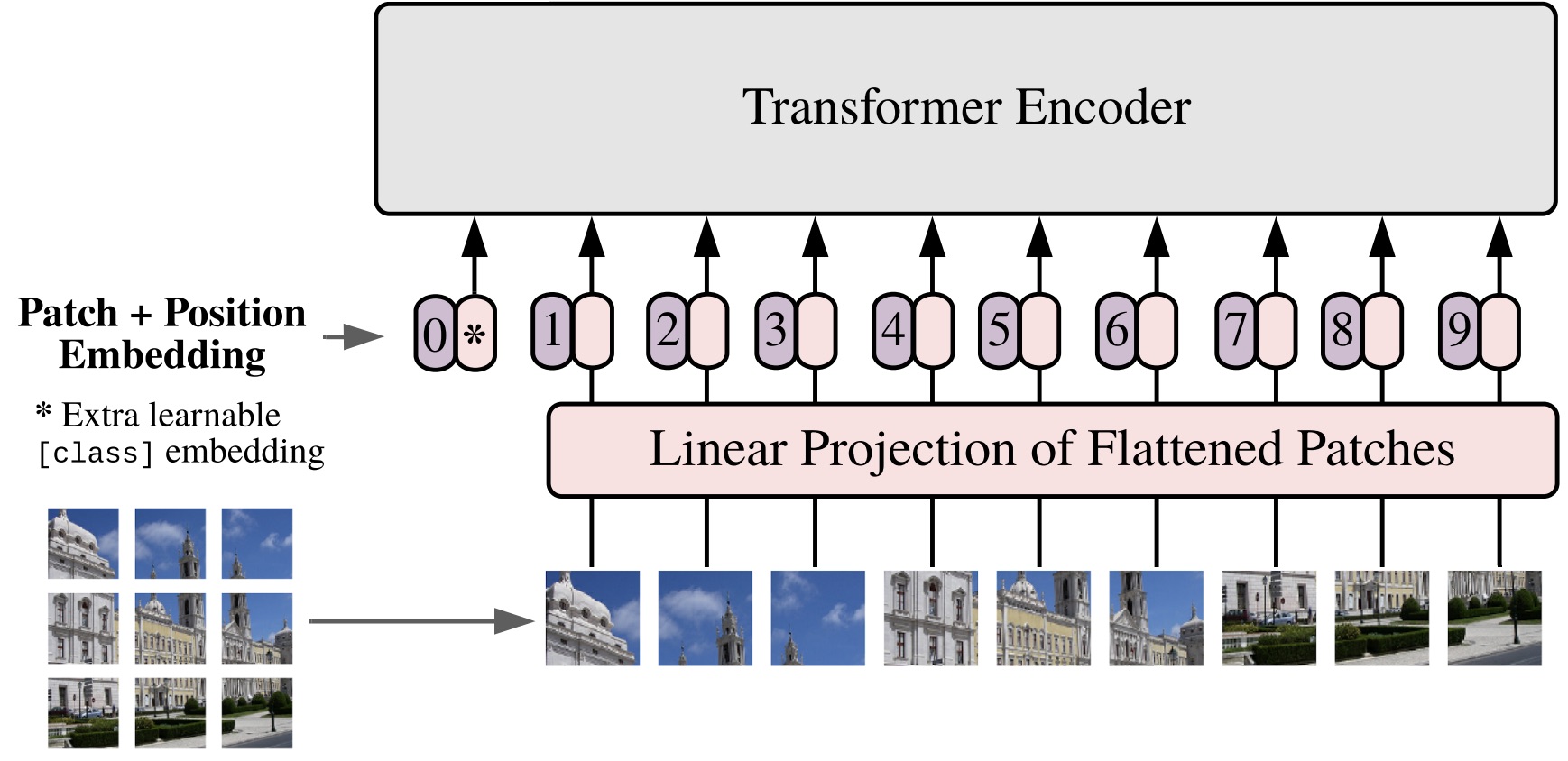
Image extracted from the paper introducing Vision Transformers [3]
Basics of DINOv2 operation
The DINOv2 backbone consists of a network of transformers that processes the image input and generates a high-dimensional vector representation that captures the relevant image features. This vector representation is common to all machine vision tasks that can be performed with DINOv2. The model has 1 billion parameters and self-distillation was applied to generate smaller models resulting in four final models: ViT-Small, ViT-Base, and ViT-Large which were obtained from the ViT-Giant version.
The DINOv2 head is adapted to the specific task being performed and is connected to the end of the backbone. For example, if image classification is being performed, the head would consist of a linear classification layer that takes the vector representation generated by the backbone and uses it to classify the image into different categories. If object detection is being performed, the head would consist of a detection network that uses the vector representation to locate and classify objects in the image.
In summary, DINOv2 has a backbone common to all computer vision tasks, and a head that adapts to the specific task being performed.
Image-level objective, patch-level objective & more
DINOv2 combines key elements from DINOv1 and iBOT, including the concepts of an image-level objective, a patch-level objective, untied head weights between both objectives and more. Below, we will provide a brief explanation, beginning with one of the most crucial concepts.
Image-level objective: Two types of neural networks are used, a teacher network and a student network, both with the same architecture but different parameters. The architecture consists of a backbone (ViT or ResNet) and a Projection Head consisting of a three-layer multilayer perceptron (MLP).
To train the student network, the concept of “Knowledge distillation” is used. This approach involves training the student network to mimic the output of the teacher network, thus allowing the student network to acquire the knowledge of the teacher network.
In the first stage of training, different global and local views of lower resolution are generated. All these views or crops are passed as input to the student network, while only the global views are used as input to the teacher network. This encourages the student network to learn local to global correspondences.
Then, with the teacher neural network fixed, the cross-entropy cost function is minimized so that the student network precisely copies the teacher network. SGD (Stochastic Gradient Descent) is used as the optimizer.
Unlike the classical Knowledge Distillation approach, DINOv2 does not use a pre-existing teacher network. Instead, a self-supervised learning method is employed in which the teacher network is constructed from previous iterations of the student network using an exponential moving average (EMA).
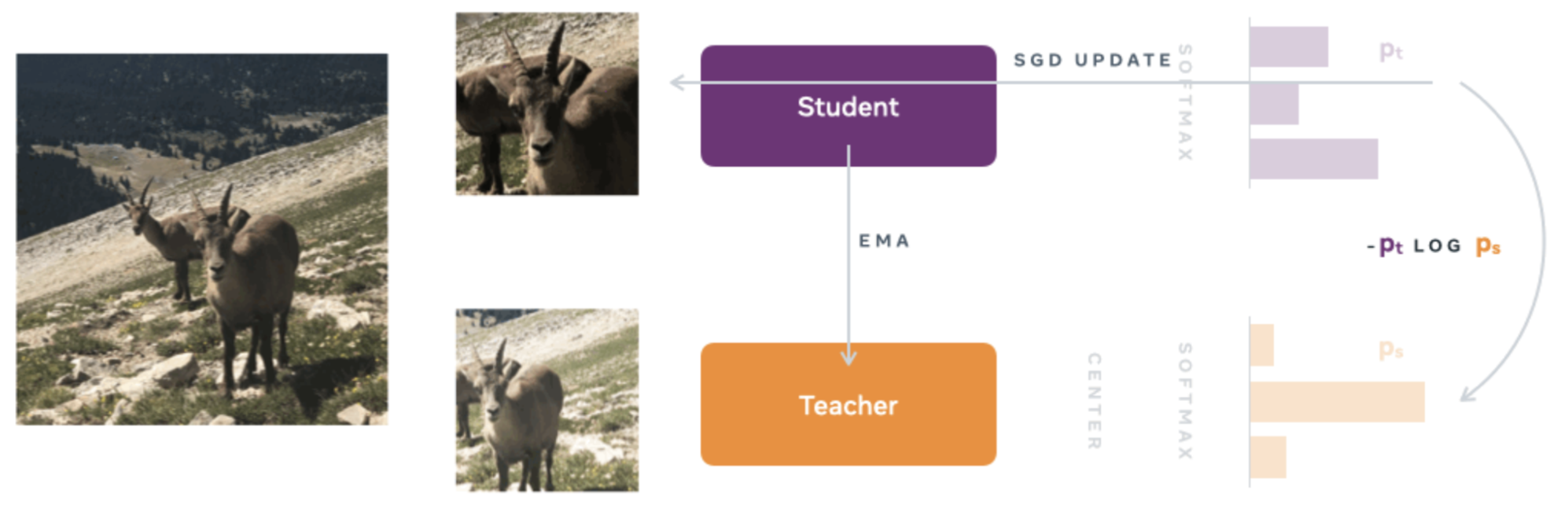
Image extracted from the official blog of DINOv1 [4]
The rest of the concepts used in DINOv2 are explained below.
Patch-level objective: some patches of the image are hidden/masked for the student network but not for the teacher network, and then the cross-entropy between the features of the two patches is calculated. This cost function is combined with the one previously explained in “image-level objective”.
It’s worth noting the relationship between masking images or patches – also known as Masked Image Modeling (MIM) – and Masked Language Modeling (MLM) used in NLP. MLM is to Transformers in NLP what MIM is to Vision Transformers. Just as in MLM, where a portion of the text is masked and used to predict the missing word, in MIM, a portion of the image is hidden or masked and used to predict the obscured part, using the rest of the image as context. In both cases, the goal is to learn a dense and continuous representation of the text or image that captures the meaning and semantic relationship between the words or pixels.

Therefore, both MLM and MIM are techniques that allow deep learning models in NLP and Computer Vision, respectively, to capture the contextual information of the input data better and improve their ability to perform specific tasks, such as text generation or image reconstruction, among others.
Untying head weights between both objectives: If the neural network weights (or parameters) associated with both targets (image-level and patch-level) are tied, the network can underfit in the patch-level classification task, while overfitting in the image-level classification task. Unbinding these weights solves this problem and improves network performance in both tasks.
Adapting image resolution: Increasing image resolution is important for detailed tasks such as segmentation or small object detection, but training at high resolution is time-consuming and memory-intensive. Instead, we increase the image resolution to 518×518 at the end of pre-training for a short period of time.
Additional concepts: The paper mentions more specific concepts that served to obtain good results such as the suggestion to use a different method to normalize the data in the training process of certain algorithms. Instead of using the current softmax centering technique of the teacher network in DINOv1 and iBOT, it is proposed to use a technique called Sinkhorn-Knopp (SK) batch normalization of another algorithm called SwAV. It is also recommended to use L2 norm and then apply the KoLeo regularizer. For more details, see the paper “DINOv2: Learning Robust Visual Features without Supervision” [2].
DINOv2 in action
As mentioned earlier, DINOv2 uses high-dimensional vector representations or embeddings to extract knowledge from images. This information can be utilized across various modalities, including depth estimation, semantic segmentation, and instance retrieval. Below, we show some examples of these applications. You can also explore an official demo of DINOv2 at dinov2.metademolab.com [1], where the examples below were generated.







Conclusions & Next Steps
In conclusion, DINOv2 is a powerful self-supervised learning framework that enables the training of vision transformers as backbones for image understanding. The ability to obtain a pre-trained backbone and add a head for specific tasks without the need for extensive labeling is a significant advantage.
The success of DINOv2 highlights the potential of self-supervised learning for developing more advanced and versatile deep learning models. Future research in related areas such as Segment Anything Model (SAM), Track Anything Model (TAM), and Caption Anything Model (CAM) could contribute to the development of even more sophisticated models.
References
References explicitly mentioned in this blog:
- Official demo of DINOv2
- “DINOv2: Learning Robust Visual Features without Supervision” (Paper of DINOv2)
- “An image is worth 16X16 words: transformers for image recognition at scale” (Paper introducing Vision Transformers)
- Official blog of DINOv1
- “SimMIM: a Simple Framework for Masked Image Modeling”
Additional valuable sources:

